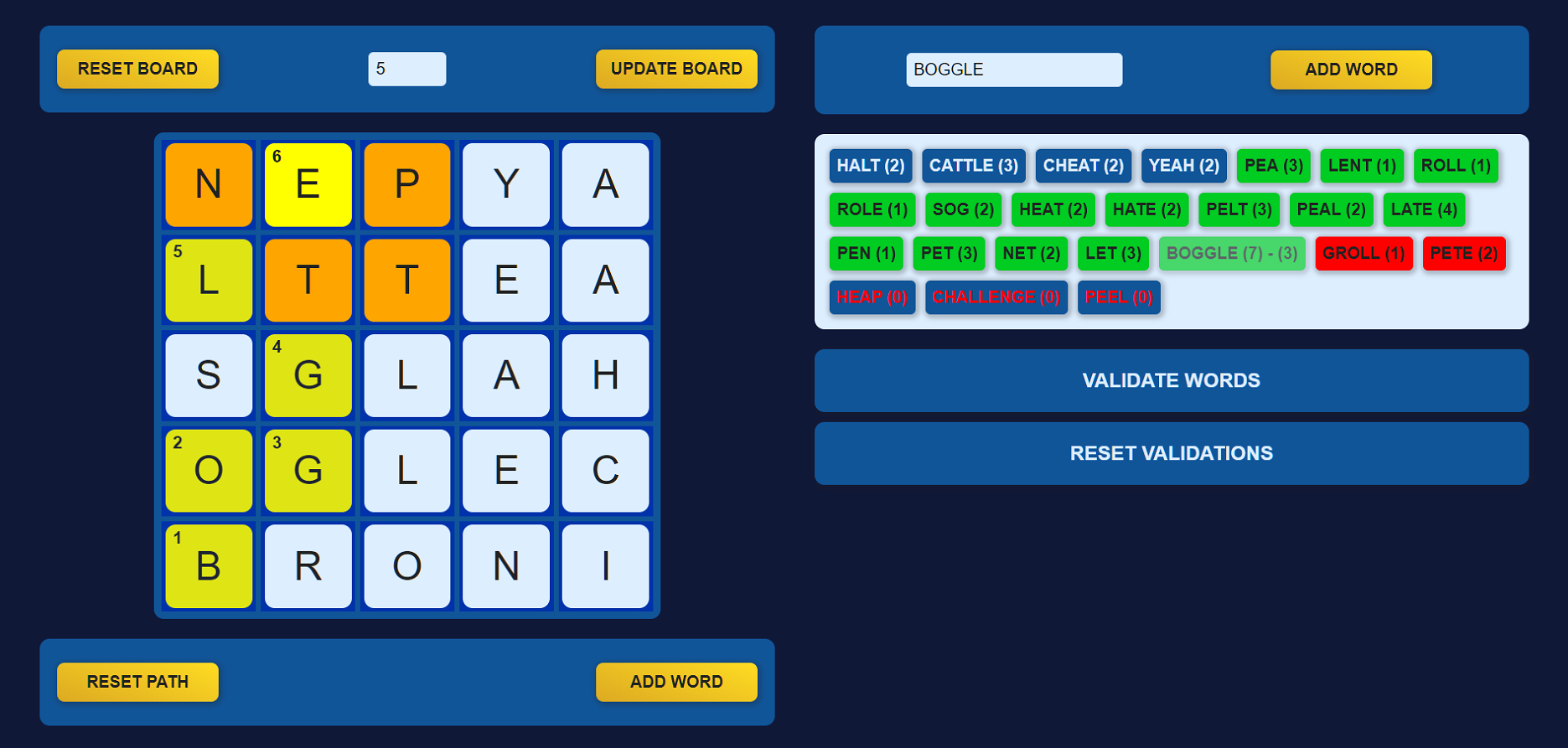
I built this Boggle application just for fun. I was intrigued by the challenge of finding a way to take a boggle board and a word and check in JavaScript if the word exists on the board. I also learned some MongoDB for the project, and came up with a cache system for minimizing the amount of HTTP requests made.
Live at >>> https://boggle.thomaslowry.me/
- React
- Node
- Express
- MongoDB
- Oxford Dictionary API
This project features an algorithm that can take a Boggle board and a word and return a list of all paths on the board that can create the word. It sounded like a cool challenge, so I did it one night, and then I built a react front-end for it, and then I decided to integrate the Oxford Dictionary API for the sake of checking the validity of inputted words.
The first step in the algorithm is finding all of the potential starting points on the board. The board is represented as a two-dimensional array of letters. The algorithm therefore loops through each row of the board to find letters that match the first letter of the word.
Once all the potential starting points have been found, a path is started at each starting point, and the recursive part of the algorithm loops through all letters adjacent to the starting letter to find letters that match the second letter of the word.
The second letter is then added to the path, and the recursion starts again, looking for the third letter and so on until the entire word has been found.
Once the path is complete, the recursion ends, and the path is pushed to the list of valid paths that will be returned. If any path never completes, meaning that it finds only a portion of the word, but cannot connect the next letter, the recursion ends and the incomplete path is forgotten.
Once the recursion finishes and all paths have been found, the list of valid paths is returned.
After building the algorithm and the React application, I decided I might as well integrate a dictionary service to check if a word is legitimate or not. I looked around for a suitable API, but most of them were much more robust than what I needed - the app only needs to know if a certain set of characters forms a legitimate word, not what it means or what its part of speech is or what its synonyms are. Oxford's seemed the most simple, so I went ahead with this option.
With all the dictionary API's I found, only one word can be validated per request - there was no way of requesting multiple words at a time. Because of this and the limited number of requests allowed for a free account, I had to come up with an efficient way of limiting the number of requests sent to the API (during implementation alone I used up an entire month's worth of requests).
It seemed a bit like overkill to create a whole PostgreSQL database just to track words for a Boggle app, so I decided to build a cache system so the server could just keep track of the words that had been previously requested from Oxford and remember Oxford's response, so that it would only need to request each word once.
This evolved into a multi-layerred system that minimizes requests in both the browser and the server. I also decided to learn MongoDB to easily save the responses from Oxford.
The cache system starts in the browser, which requests a list of all previously validated words as soon as the page loads. This is used whenever the user hits the VALIDATE WORDS button to immediately know which words are valid or invalid. Only words that are not found in the list will be sent to the server for further validation.
Just like the browser, the server stores in memory a list of all previously validated words, so that if any word comes in that has already been requested from Oxford, the validity can immediately be found and sent back. This list, however only includes words that have been requested during the server's run time, not necessarily all words in the database.
The server also keeps a self-cleaning cache of outgoing requests to both the database and Oxford. This way, if the same new word is requested multiple times simultaneously, the request will only be sent once to Oxford or the database, and the duplicate words will simply subscribe to that request, so that when the response comes back from either Oxford or the database, the server can then respond simultaneously to all clients that requested that word.
If the word is not found in the cache and no outgoing request is found for the word, then a request is sent to the database to check if it is there. This request is cached so that (as mentioned above) any requests for that same word that come in at the same time can just subscribe to that request. When the database response comes back, the cached request removes itself from the cache.
Any words that make it all the way through the system without being found will be requested from the Oxford Dictionary API. Requests to Oxford are cached and can be subscribed to exactly the same as requests to the database. This ensures that each word that is received by this server will only ever be requested from Oxford exactly once.
I decided to use MongoDB for this project because I had heard that it was very simple to set up, and that it saves data in JSON format. That way I wouldn't have to worry about what data structure was returned from Oxford, I could just save it directly to the database. I found those things to be true; it was very quick to set up and connect the server to, and it allowed the server to be 100% JavaScript.