Link to the published paper: https://ieeexplore.ieee.org/document/9342571
The accurate prediction of stock prices has a significant role to play in the present economic world. However, stocks have an ever-changing nature coupled with a risk factor that always seems much of a gamble, making it worthwhile for researchers to analyze them with machine learning algorithms. We thus seek to develop a machine-based model replacing the traditional yet unreliable time-series forecasting to predict the stocks from the past historical data of a firm and to uncover the underlying patterns to improve the accuracy of the prediction of the model. This project is an Empirical study of applying Machine Learning algorithms to predict the Stock Prices.
Source https://finance.yahoo.com/quote/GOOG/
Contains the dataset of Google.com's stock market prices listed by Yahoo Finance.
Various features of the gathered dataset which is used for Stock Price Prediction are as follows–
- Date: This gives the date corresponding to which the stock prices are stored.
- Open: The open is the opening price at which the market opens, i.e., the price for which the first trading executes.
- High: It represents the highest price at which the stock has reached on the given day.
- Low: It represents the most economical value at which the stock has concluded on the given day.
- Close: The Close is the closing price, and it is the most crucial price as it is the closing price for the given period. Close works as an indicator for the strength- if Close is higher than Open, it is considered a fruitful day for the stock.
- Adj Close: The adjusted closing price is the price that is quoted by the data provider after reviewing any corporate actions like dividends or stock splits.
For evaluating the efficiency of the proposed models, we applied RMSE (Root Mean Square Error) to measure every applied algorithm's accuracy. The RMSE shows the average squared deviation of the actual value from the predicted value. And it gives information about how well the data is concentrated around the line of best fit. Hence, a good model is
one whose RMSE value is lower.
ܴ
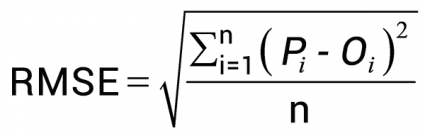
where Pi is the predicted value that we got from the model and Oi is the actual value from the data and n is the total number of observations.
This contains the python notebook which has the main code of our project with a step by step implementation of machine learning algorithms as well as LSTM and the comparison between all of them on the basis of the predictions. We have done some experiment to get the prediction, thats why there are several Jupyter Notebook files.
This file is the presentation that we gave at the INDICON 2020.
This file is a detailed project report. It contains all the necessary information regarding our results, the methods we applied, several comparisons, and the details of references as well.
This is the paper that is published in the IEEE Xplore.
This contains the poster that we made for presentng our project.
- Vaibhav Gaur gathered the dataset of Google’s Stock prices from Yahoo! Finance and preprocessed it so that unnecessary data can be cleaned and then implemented the Linear Regression on the data and concluded that it predicted the stock prices more accurately.
- Shubham Sood did the data visualization and comparison graphs to see the pattern and trends in the data; after that, computation of training time needed for each algorithm is carried out, and the LSTM & k-nn algorithm is applied to the data.
- Lisha Uppal did the literature survey about the project so that we can get the knowledge about our project and we can explore about it then she applied Decision Tree algorithm and observed that it had the fastest execution time but takes the maximum time in training of the dataset moreover she made the proposal and report of the project.