[TOC]
| List | Set |
|---|---|
| List的特征是其元素以线性方式存储,集合中可以存放重复对象。 | Set是最简单的一种集合。集合中的对象不按特定的方式排序,并且没有重复对象。 |
1、根据存入对象的hashCode判断是否存在相同的,如果不存在,则不重复 存储。
2、如果hashCode相同,则调用equals方法判断是否相同,如果不相同,则不重复 存储。
3、如果hashCode相同,equals返回为true则重复,不存储。
HashMap的结构是桶链式(在jdk1.8下如果链表的长度超过8时,会自动转换成红黑树),
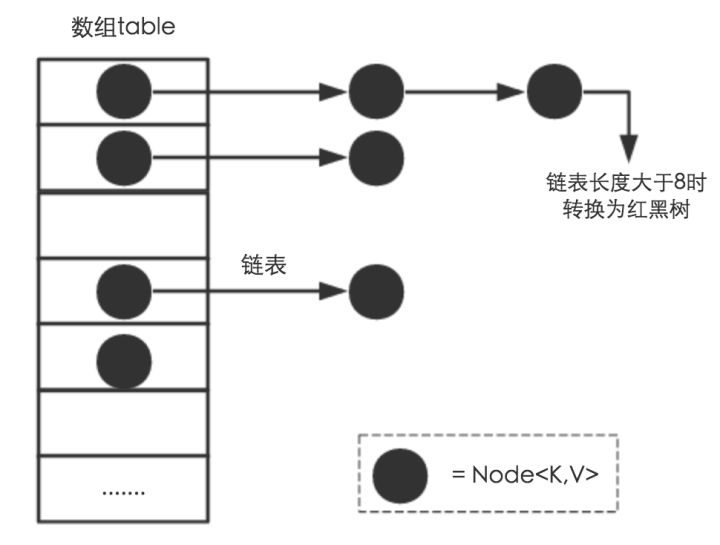
jdk1.7版本下 HashMap底层实现是Entry数组实现。jdk1.8 HashMap底层实现是Node数组实现。
-
由于是数组的实现,那么在并发情况下,对于同一个index下标元素的处理会发生覆盖。
-
在HashMap自动扩容处理中,会讲原来的数组复制到扩容后的数组,在并发情况下,会存在数据丢失。
HashMap的默认大小capacity是16,它的负载因子loadFactor是0.75,那么它的最大个数threshold = size * loadfactor 为12,那么也是说当数组的length超过12的时候,HashMap会触发扩容,首先会新建一个数组,其大小为原来的两倍,然后将原来数组的元素复制到新数组。其中复制的过程,过程详细如下。
由于我们数组的的大小一定是2的次方倍,并且扩容之后的大小为原来的两倍,所以我们设原来大小为2^N,那么扩容之后的大小为2^N+1,那么元素在put到HashMap中,它在数组的中下标是由它的key的hashCode决定的,但是由于数组的长度有限,你的HashCode是大小不能超过数组的长度,所以我们会看到在源码中有这么一行,
i = (length - 1)& hash(key) 这里解释一下 length是数组的长度,减一是因为下标从0开始,hash(key)就是返回key的哈希值,这样就保证i的范围在0到length-1之间,通过这一点我们可以知道 新数组怎么复制到新数组了。
- 如果第N+1位为0 则不需要任何处理,不需要进行位置调整。
- 如果第N+1位位1,则下标变成老的下标值+老的数组长度。
下面代码就是判断扩容的源码
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}其中e.hash & oldCap 就是判断第N+1位是否位0.可能大家看不懂是什么意思,我给大家打个比方,
比如你的e.hash也就是key的hash值位53,HashMap扩容前大小为2^4 =16 N=4, 那么扩容前这个元素在数组中的下标
index = 53 & (16-1) 换成2进制运算也就是 (补齐8位)0011 0101& 0000 1111 = 0000 0101也就是5 那么原来的下标就是5。
那么进行扩容 从16=》32 N原来是4 现在是5 ,所以我们看看按照规则0011 0101 需要判断第五位是否为1
在jdk源码中为 if ((e.hash & oldCap) == 0) 此时我们的e.hash为 0011 0101 oldCap为 16 也就是
0011 0101 & 0001 0000巧妙的利用 &运算符快速判断是不是为1 如果为1 则 newTab[j + oldCap] = hiHead; 如果为0 newTab[j] = loHead;。
-
在1.7中 HashMap底层为Entry数组为拉链式,当hashCode值相等的时候,则在链表上添加元素,那么极端情况下需要遍历整个链表,时间复杂度为O(n)
-
在1.8中 HashMap底层为Node数组为拉链式 + 红黑树,当hashCode值相等的时候,则在链表上添加元素,当链表的长度超过8的时候,链表会转红黑树。那么极端情况下,时间复杂度为O(logn)
-
final可以用于修饰类、方法、字段。如果修饰类,代表该类不可以继承、如果修饰方法,代表该方法不可以重写、如果修饰字段,代表该字段不可以被修改。
-
finally通常与try catch finally一起用,通常用于异常捕获,不管有没有异常发生,finally的代码块一会被执行。
-
finalize 属于object的方法,java技术允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在object类中定义的,因此所有的类都继承了它。子类覆盖finalize()方法以整理系统资源或者被执行其他清理工作。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
共四种,分别是。
- 继承Thread
继承Thread,重写它的run方法既可以创建一个线程,优点是简单,缺点就是java只支持单继承,那么意味着我们这个类就不能再去继承其他的类。实现如下
public class TaskThread1 extends Thread{
@Override
public void run() {
System.out.println("extend Thread");
}
public static void main(String[] args) {
new TaskThread1().start();
}
}- 实现Runnable接口
通过实现Runable接口,重写它的run方法,也可以创建一个线程,它相比之前的方法是去实现接口,java支持接口的多实现,那么这样会显得更加灵活,实现如下。
public class TaskRunner1 implements Runnable {
@Override
public void run() {
System.out.println( " implement runnable ");
}
public static void main(String[] args) {
new Thread(new TaskRunner1()).start();;
}
}- 实现Callable接口
相比于Runable,Callable是一种带返回值得方法,我们需要重写它的call方法, Callable需要与FutrueTask配合使用,通过FutureTask的get方法即可放回call方法的返回值,然后此时call方法还没执行完成,那么get方法将会被阻塞挂起。实现如下
public class TaskCallable implements Callable<String> {
@Override
public String call() throws Exception {
String result = "implement Callable";
return result;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> futureTask = new FutureTask<>(new TaskCallable());
new Thread(futureTask).start();
TimeUnit.SECONDS.sleep(3);
System.out.println(futureTask.get());
}
}- 线程池实现
public class TaskExecutor {
public static void main(String[] args) {
ExecutorService executorService = new ThreadPoolExecutor(10, 20,
1000L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>(1024));
for (int i = 0; i < 10; i++) {
executorService.execute(() -> {
System.out.println("by thread pool");
});
}
}
}-
Callable位于java.util.concurrent包下,是这个泛型接口。它也是一种实现线程的接口,继承Callable接口重写它的call方法即可,它相比于Runnable接口实现线程的优点就是它支持返回值与抛出异常。它指定的泛型就是它的返回值。
-
Future也是一个接口,它用封装异步计算的结果,它有三个比较重要的方法。isDone() 判断线程是否执行完成, cancel()中断线程, get()获取线程执行完的结果,如果尚未执行则会阻塞,一直到执行完。
Callable方式的线程启动有两种方法,一种是通过线程池,一种是通过FutureTask
- 线程池,通过ExecutorService的submit方法即可提交一个Callable线程任务,它的返回值的Future。
- FutureTask,它是Future的实现类,同时它也实现了Runable接口,所以FutureTask可以通过new Thread方式启动,也可以通过线程池方式启动。
下面代码演示一下。
public class TaskCallable implements Callable<String> {
@Override
public String call() throws Exception {
String result = "implement Callable";
return result;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> futureTask = new FutureTask<>(new TaskCallable());
new Thread(futureTask).start();
TimeUnit.SECONDS.sleep(3);
System.out.println(futureTask.get());
ExecutorService executorService = Executors.newSingleThreadExecutor();
Future<String> future = executorService.submit(new TaskCallable());
System.out.println(future.get());;
}
}- corePoolSize 核心线程数
- maximumPoolSize 最大线程数
- keepAliveTime 非核心线程存活时间
- timeUnit 时 间单位
- blockQueue 任务阻塞队列
- threadFactory 线程工厂
- RejectedExecutionHandler 拒绝策略
volatile它的内存语义就是每当线程去写一个volatile变量的时候,它会将本地内存的共享变量重新写回到主内存。
那么每当线程去读一个volatile变量的时候,它会将本地内存的共享变量置为无效,并且重新从主内存读取。
volatile它可以保证可见性与一定有序性那么根据它的特点,它可以被用于线程之间的通信与双重检测机制,
被volatile修饰过的变量,在编译后字节码前后会插入内存屏障。
- 对于volatile写 前会插入 storestore屏障,保证volatile写不跟之前的普通写的重排序
- 对于volatile写 后会插入storeload屏障,保证volatile写不会跟之后的volatile写/读(如果有)重排序
- 对于volatile读 后会插入loadload屏障, 保证volatile读不会跟之后的普通读重排序
- 对于volatile读 后会插入loadstore屏障,保证volatile读不会跟之后的普通写重排序
synchronized 是通过对象监视器来实现的,对象监视器是一种互斥锁,意味着同时只能有一个线程获取到这个对象的锁。
synchronized代表同步,它可以修饰方法,它也可以修饰代码块。
-
如果synchronized修饰的普通方法 那么它锁的当前对象
-
如果synchronized修饰的静态方法 那么它锁的当前类的class对象
同理在同步代码块中synchronized锁的是类的普通成员变量,那么它锁的就是当前对象,
如果是静态变量或者是class对象,那么它锁的是类的class对象。
优点:实现简单,语义清晰,便于JVM堆栈跟踪,加锁与解锁的过程由jvm自动控制,在jdk1.6后,通过了多种优化方案,使用广泛。
缺点: 悲观的排它锁,不能进行高级功能。
- ReentrantLock 可重入锁,独占锁。
- WriteLock 写锁,实现读写分离,读写,写写阻塞
- ReadLock 读锁,实现读写分离,读读不阻塞
- Segment 分段锁 用于ConcurrentHashMap提供线程安全保障
用处:保证线程安全。
底层通过AQS实现,通过一个同步状态量state与同步队列来保证并发运行下线程安全。
在ReentrantLock中对于获取锁操作
-
首先判断 同步状态量是否为0,如果为0代表此时还没有线程获取,则通过cas修改state的为新的同步状态量,一般在ReentrantLock这个值是被写死为1。 如果cas修改成功则 true
-
如果state不为0 则代表当前锁已经被其他线程获取。通过
getExclusiveOwnerThread判断获取锁的线程与当前线程是否是同一线程,如果是则把当前状态量state加上新增状态量(也就是1),然后通过cas修改state的值。 这也就是可重入锁实现的原理。 -
如果以上两种情况都不是,则代表锁获取失败,把当前线程包装成一个node节点,并且添加到同步队列的尾部,等待通知被唤醒,再次参与锁的获取竞争。
对于 释放锁的操作
- 同样的我们对于释放锁,也需要去修改的同步状态量state,因为我们锁是可重入的,所以只有当state为0 的是否才代表当前线程彻底释放锁,才会去唤醒同步队列的头结点,参与锁的竞争。
-
悲观锁 每次操作悲观的会发生竞争,数据被别人修改,所以每次操作前会加锁操作完会释放
- 优点 确保多线程环境一定是线程安全的。
- 缺点 非多线程情况下,也需要加锁释放锁,效率低。
-
乐观锁 每次操作乐观的认为不会发生竞争,所以不会加锁,通常是用过version来判断
- 优点 节省了加锁释放锁的开销,提供了系统的性能。
- 缺点 如果在经常发生冲突(写数据比较多的情况下),上层应用不不断的retry,这样反而降低了性能,对于这种情况使用悲观锁就更合适
-
CAS会存在的ABA问题的,我们可以version或者是lastmodifytime来保证此时的A就是我们之前的A。在atomic包中有一个
AtomicStampedReference可以避免ABA问题,其中它是通过一个时间戳来记录上次修改的时间。 -
CAS 自旋循环开销大
-
CAS只能保证单个变量操作的原子性,不能保证多个,atomic提供了一
AtomicReference来解决
通过Thread.join方法实现 代码如下
/**
* @author yukong
* @date 2018/9/12
* @description 保证A B C三个线程顺序执行。
*/
public class OrderJoinExample {
public static void main(String[] args) throws InterruptedException {
Thread ta = new Thread(()->{
System.out.println(Thread.currentThread().getName() + " is running");
}, "Thread-A");
Thread tb = new Thread(()->{
try {
ta.join();
System.out.println(Thread.currentThread().getName() + " is running");
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "Thread-B");
Thread tc = new Thread(()->{
try {
tb.join();
System.out.println(Thread.currentThread().getName() + " is running");
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "Thread-C");
tc.start();
tb.start();
ta.start();
tc.join();
System.out.println(Thread.currentThread().getName() + " is running");
}
}- NEW 线程创建状态 创建一个线程但是还没运行
Thread t = new Thread() - RUNNABLE 线程的运行状态(运行状态与准备就绪统称RUNNABLE)
t.start() - WAIT 等待状态
Object.wait Object.join - TIME_WAIT 超时等待状态 ``Object.wait(long) Thread.join(long) Thread.sleep(long)LockSupport.parkNanos`
- BLOCKED 阻塞状态
- TERMINALED 终止状态
| sleep | wait | |
|---|---|---|
| 1 | sleep属于Thread的静态方法 | wait属于Object的普通方法 |
| 2 | sleep要指定一个超时等待的时间 | wait可以不指定,代表一直等待直至被唤醒,也可以指定超时等待时间。 |
| 3 | 不会释放锁 | 会释放锁 |
notify会唤醒在等待当前对象锁的一个线程。
notifyAll会唤醒在等待当前对象锁的所有线程。
TheadLocal又称线程本地变量,代表它只能被拥有的它线程访问,其他线程是无法访问,所以它是线程安全。
ThreadLocal是通过一个ThreadLocalMap实现的其实它相当于Map<Thread,Object> 其中的Thread就是调用
set()方法的线程。 那么get的时候通过当前线程获取,从而保证线程安全。注意使用完记得remove,不然会存在内存溢出的问题。