This is among the most interesting dataset i have ever worked with. The dataset is called "Labelled faces in te Wild (LFW) dataset". Original daraset is present on kaggle however i'm using the filterest dataset present on this link.
Today we're going to train deep autoencoders and apply them to faces and similar images search.
Our new test subjects are human faces from the lfw dataset.
Let's design autoencoder as two sequential keras models: the encoder and decoder respectively.
We will then use symbolic API to apply and train these models.
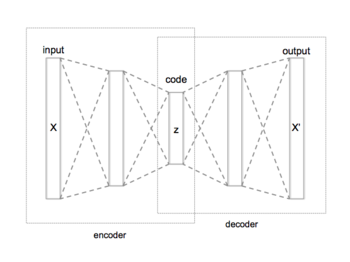
Principial Component Analysis is a popular dimensionality reduction method.
Under the hood, PCA attempts to decompose object-feature matrix
-
$X \in \mathbb{R}^{n \times m}$ - object matrix (centered); -
$W \in \mathbb{R}^{m \times d}$ - matrix of direct transformation; -
$\hat{W} \in \mathbb{R}^{d \times m}$ - matrix of reverse transformation; -
$n$ samples,$m$ original dimensions and$d$ target dimensions;
In geometric terms, we want to find d axes along which most of variance occurs. The "natural" axes, if you wish.

PCA can also be seen as a special case of an autoencoder.
- Encoder: X -> Dense(d units) -> code
- Decoder: code -> Dense(m units) -> X
Where Dense is a fully-connected layer with linear activaton:
Note: the bias term in those layers is responsible for "centering" the matrix i.e. substracting mean.
PCA is neat but surely we can do better. This time we want you to build a deep convolutional autoencoder by... stacking more layers.
The encoder part is pretty standard, we stack convolutional and pooling layers and finish with a dense layer to get the representation of desirable size (code_size).
I recommend to use activation='relu' for all convolutional and dense layers.
I recommend to repeat (conv, pool) 4 times with kernel size (3, 3), padding='same' and the following numbers of output channels: 32, 64, 128, 256.
Remember to flatten (L.Flatten()) output before adding the last dense layer!
For decoder we will use so-called "transpose convolution".
Traditional convolutional layer takes a patch of an image and produces a number (patch -> number). In "transpose convolution" we want to take a number and produce a patch of an image (number -> patch). We need this layer to "undo" convolutions in encoder.
Here's how "transpose convolution" works:

Our decoder starts with a dense layer to "undo" the last layer of encoder. Remember to reshape its output to "undo" L.Flatten() in encoder.
Now we're ready to undo (conv, pool) pairs. For this we need to stack 4 L.Conv2DTranspose layers with the following numbers of output channels: 128, 64, 32, 3. Each of these layers will learn to "undo" (conv, pool) pair in encoder. For the last L.Conv2DTranspose layer use activation=None because that is our final image.
Let's now turn our model into a denoising autoencoder:

We'll keep the model architecture, but change the way it is trained. In particular, we'll corrupt its input data randomly with noise before each epoch.
There are many strategies to introduce noise: adding gaussian white noise, occluding with random black rectangles, etc. We will add gaussian white noise.
First thing we can do is image retrieval aka image search. We will give it an image and find similar images in latent space:
To speed up retrieval process, one should use Locality Sensitive Hashing on top of encoded vectors. This technique can narrow down the potential nearest neighbours of our image in latent space (encoder code). We will caclulate nearest neighbours in brute force way for simplicity.
In the end, you will also be able to generate more images from an input image which are similar to each other.
Play with it & Enjoy weird face expressions you can generate!!