You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
例えば,スペイン語ソース文"El perro blanco (単語順にthe dog whiteとなる)"を,英語に翻訳(ターゲット)すると,"the white dog"となる.英文2つ目のwhiteは,スペイン文の3単語目に対応する.ターゲット英文のwhiteは,ソース文のwhite (blanco)より後に出てきて欲しいので,"the ε white dog"とεトークンを追加することで,ターゲット文を修正し,アラインメントを調整する.
You May Not Need Attention. 2018
Ofir Press, Noah A. Smith
https://arxiv.org/abs/1810.13409
https://github.com/ofirpress/YouMayNotNeedAttention
概要
NMT (Neural Machine Translation)において,アテンションなしで,セパレートエンコーディング・デコーディングなしで,どの程度の性能が得られるか調査.本論では,アテンション及びセパレートエンコーディング・デコーディングなしの,ニューラルリカーレントモデルを提案.この翻訳モデルは低遅延で,最初のトークンを読んだらすぐに最初のターゲットトークンを出力する.標準的なアテンションモデル(Bahdanauらのモデルベース)と同程度の性能があり,長い文では他アテンションモデルよりも良い結果となった.
Introduction
近年のNMTは下記のような特徴がある.
本論ではこれらの特徴を除いてNMTの性能を調査する.
そのために,Bahdanau (2014)のモデルをベースにして,アテンション機構を取り除き,エンコーダーとデコーダーを統合する.このsimplerモデルはZaremba(2014)の言語モデルに似ている.このモデルでは,"eager"に翻訳を行う(ソースの単語を入れるとすぐにターゲットの単語が出てくる,下図).
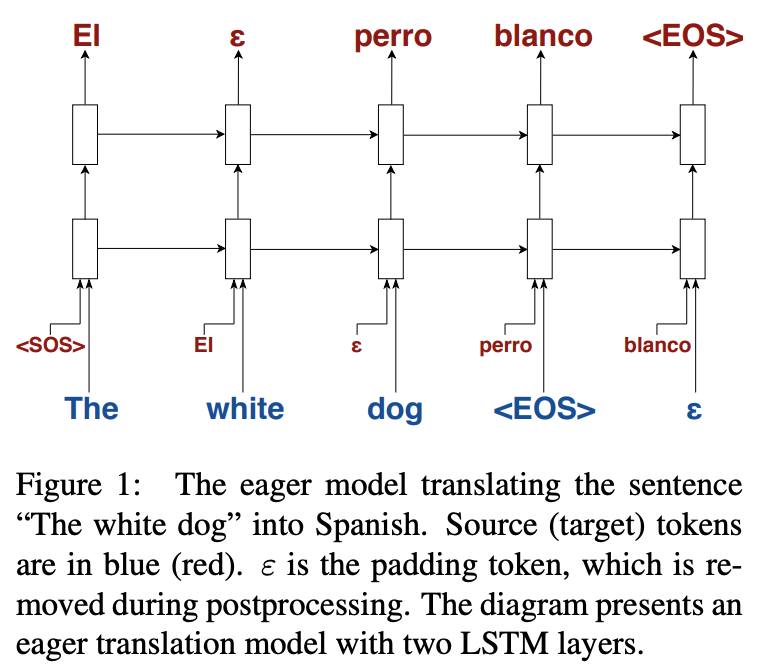
このモデルはソースの前トークンだけを使うため,メモリ消費量は一定量である(アテンション機構ではソースの各ステップのhidden stateをすべて覚えておくのが一般的).
データの前処理
今回のこの,"eager translation model"は学習データに対して前処理がいる.というのも今回エンコードとデコードが同じになっているため,そのままでは学習できない.つまり通常はソースをすべて読んでから翻訳が開始できるが,今回はソースを1単語読むごとにターゲット1単語を出力する必要があり,アラインメント(翻訳元と先の対応する単語)を調整する必要がある.
ソース/ターゲット分に対して,(s, t)の単語アラインメントを推測する必要がある.これをeager feasible (s_i, t_j), i<=jとして表す.// 後ほど説明
このためにまず,off-the-shelfアラインメントモデル(fast_align: Dyer, 2013)でアラインメントを推測し,最小限のεトークン(空トークン)をターゲット文に追加する.このトークンは翻訳生成後に取り除かれる.
例えば,スペイン語ソース文"El perro blanco (単語順にthe dog whiteとなる)"を,英語に翻訳(ターゲット)すると,"the white dog"となる.英文2つ目のwhiteは,スペイン文の3単語目に対応する.ターゲット英文のwhiteは,ソース文のwhite (blanco)より後に出てきて欲しいので,"the ε white dog"とεトークンを追加することで,ターゲット文を修正し,アラインメントを調整する.
下図の例も分かりやすい.ターゲットの各単語に対応するソースの各単語は,ソースの各単語よりも未来方向に出るよう調整される.
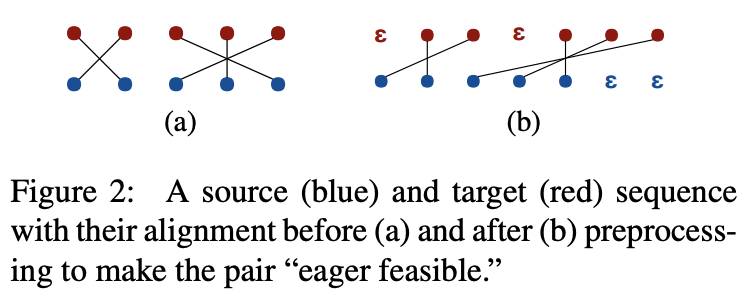
改めて記号を整理する.ソースとターゲット文をs=<s_1,..., s_m>, t=<t_1,...,t_n>とする.Aを(i, j)の順序付ペアとする.これは,t_jがs_iにアラインしていることを表す.ターゲット文の単語は左から順に1つずつ見ていく.またi <= jである.
またεの割合を翻訳パターン別に下記に示す.

更にタスクをシンプルにするため,b ∈ {0, 1, . . . , 5}個のεトークンを全ターゲット文の文頭に入れた.ソースのエンコードを予め行う余裕が出て,ターゲットのトークン間のε挿入を減らせる.またソース・ターゲットの文ペアは同じ長さになるよう,短い文の方にεを追加して同じ長さにしている
モデル
データの流れを説明する.まず各タイムステップで,ソースの入力単語及び1つ前のステップのターゲット単語の出力を次元Eにembedding.この2つのベクトルはconcatされ,マルチレイヤのLSTM(各レイヤは2E次元)に流される.このLSTMの出力は,全結合レイヤに流されの次元はEになる.そして出力のembedding行列とsoftmaxを使い,出力単語の確率分布を得る.
我々のモデルはZremba (2014)ととても似ている.また学習時はティーチャーフォーシング(前ステップの出力単語を入力に入れるときに,予測した単語でなく正解データを利用する方式)を利用し,学習はクロスエントロピーロスを採用.我々はパッディングを行っているものの,特別な損失関数やパディングトークンに対して特別な損失関数や修正は行っていない.
また通常のNMTモデルと異なり,推論時のメモリ量は一定である(前ステップの隠れ層だけメモリに入れる).処理量のオーダーも,最悪O(n+m)で済む.// nとmはソース・ターゲットの文の長さ
Aligned Batching
データの前処理で,すべてのソース・ターゲットのペアは同じ長さになっている.そこで,すべてのソース文を1つのソース文字列に,すべてのターゲット文を1つのターゲット文字列に,それぞれ順序は変えずに作った.これは言語モデルの学習と同様の方法で,翻訳モデルを学習できることを意味する.
Decoding
推論時は,出力品質の改善のため,ビームサーチアルゴを下記のように修正した.
εパディングの出力数に上限を設定した(制限に達成した場合,εの生起確率は強制的に0にされる).また文頭のパディングはこの制約にカウントしない
実験中,ソース文のEOS(end-of-sentence)が流されたとき,デコーダーもEOSを高い確率で出力する傾向にあることを見つけた.そこで,ソースのEOSの前にεトークンを挿入することで翻訳品質が改善するとわかった.そこで,SPIのハイパパラメタをcとセットした場合,ビームサーチ処理は,ソースのEOSの前にc個のεトークンがあると考慮する.
このソースパディング挿入は,ターゲットがソースより長いときに高価を発揮.このインジェクションがないと,ターゲット文はソース文でクランプされる.
実験
WMT 2014を利用.他学習のパラメタ,設定に関してはTable 4参照.
リファレンスモデルとして,Bahdanau (2014)を実装している,OpenNMT (Klein 2017)を利用.両モデルは,devデータで改善しなくなるまで更新した.1GPUでリファレンスモデルは13時間かかり,我々のモデルは38時間かかった.しかし,我々のeager modelは,OpenNMTの約3倍のソーストークンを処理できる.eager modelが時間がかかったのは,収束するエポック数が多かったため.
評価は,SacreBLEU (Post, 2018)を使って,de-tokenize(再結合)した文に対するBLEUスコアで評価.
結果
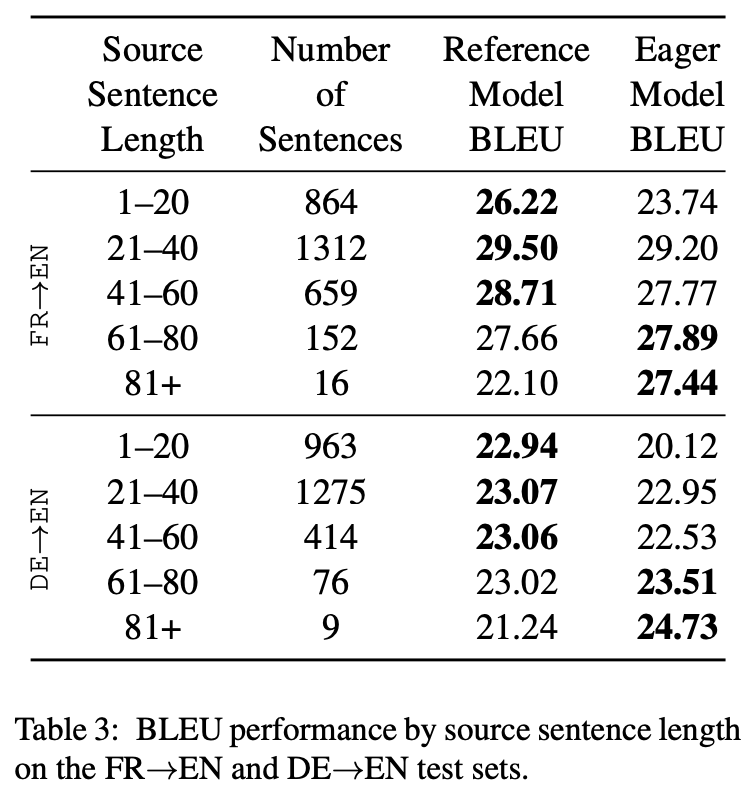
結果はTable 2に.提案モデルは文頭のεパディングを0〜5個で確認.リファレンスモデルに肉薄しているのが分かる.

更に詳細に見てみる(FR->EN,DE->EN).提案モデルは,長い文が短い文よりも得意であることがわかる.長い文はアテンションモデルでは難しいということが知られている(Koehn and Knowles, 2017).
関連研究
初期のNMTでは,エンコーダーとデコーダーが別々でアテンションは使われていなかった.しかし最近はアテンション機構を使った,リカレントモデルやTransformer,またCNNを使ったモデルなども提案されている.他様々なモデルが提案されている(割愛)
これらのモデルはすべてエンコーダーとデコーダーを別にしている.更にすべての細菌のモデルはアテンション機構をデコーダーかエンコーダーとデコーダーのどちらかに利用している.
Elbayad et al. (2018)はエンコーダーとデコーダーを統合したが,リカレントモデルではない.Kalchbrenner(2015)とBahar(2018)は,一般的なエンコーダー・デコーダーアーキをりようしていないが,通常のエンコーダー・デコーダーモデルよりもかなり遅い.
Grissom (2014),Gu (2017)は,オンライン翻訳モデルの学習に強化学習を利用(後者はアテンション利用).Ma (2018)も文頭パディングで翻訳モデルを提案しているが,我々のように入力単語を入れたらすぐ単語が出力するようなものではない.また同時翻訳モデルでも,非同時翻訳モデル(エンコーダー・デコーダー別)ほど性能が出ていない.
またAharoni and Goldberg (2017)では,シンボルを出力するためにいつモデルを学習するか,より多くのソースシーケンスを読む必要がある場合をしるために,訓練データのアラインメントモデルを利用する(我々のeager feasibility前処理と似ている).
結論
アテンションを使わず,言語モデルのように動作する翻訳モデルを紹介した.一般的なアテンションモデルと同等の性能を出すことができた.
コメント
次に読む論文
The text was updated successfully, but these errors were encountered: