Big data, Databricks and now also Synapse Analytics. Microsoft really focuses on how to put together BI and Data Warehouse solutions that can handle huge volumes of data. But what about the "ordinary" solutions in the SME market? How do we put together a simple, scalable, sensible and affordable Azure solution for them? Where we can also reuse the competencies we have already built from making the same solutions on SQL Server.
A very simple "ETL framework" based on Integration Pipelines (Data Factory), Data Lake Storage, SQL Database and Power BI. The architecture consist of multiple different layers, where I draw on and use some of the terms from the "modern" solutions. There really isn't anything new in this way of creating an layered architecture - it's mostly a matter of naming and then using the Azure services in the best possible way.
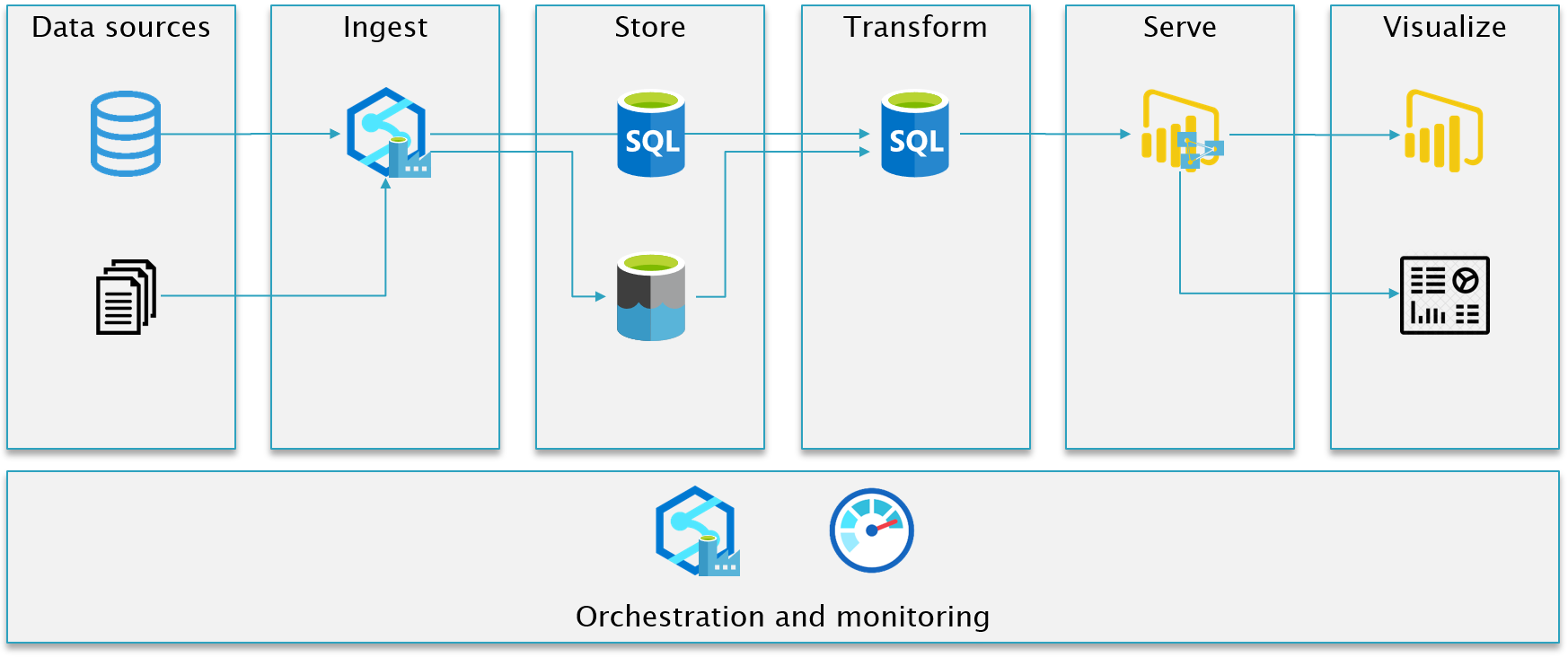
Although the initial architecture shows two SQL Databases, we combine the Store and Transform in the same database. It's adviced to create a DTU based Azure SQL database on the Standard Tier to make the solution most cost effective.
In the database project you find schemas, tables, views and stored procedures. Objects that is all used to transform the data from the raw layer all the way to dimensions and facts in the baseline layer. The solution only handles full load. It's prepared to also handle incremental load, but not yet implemented.
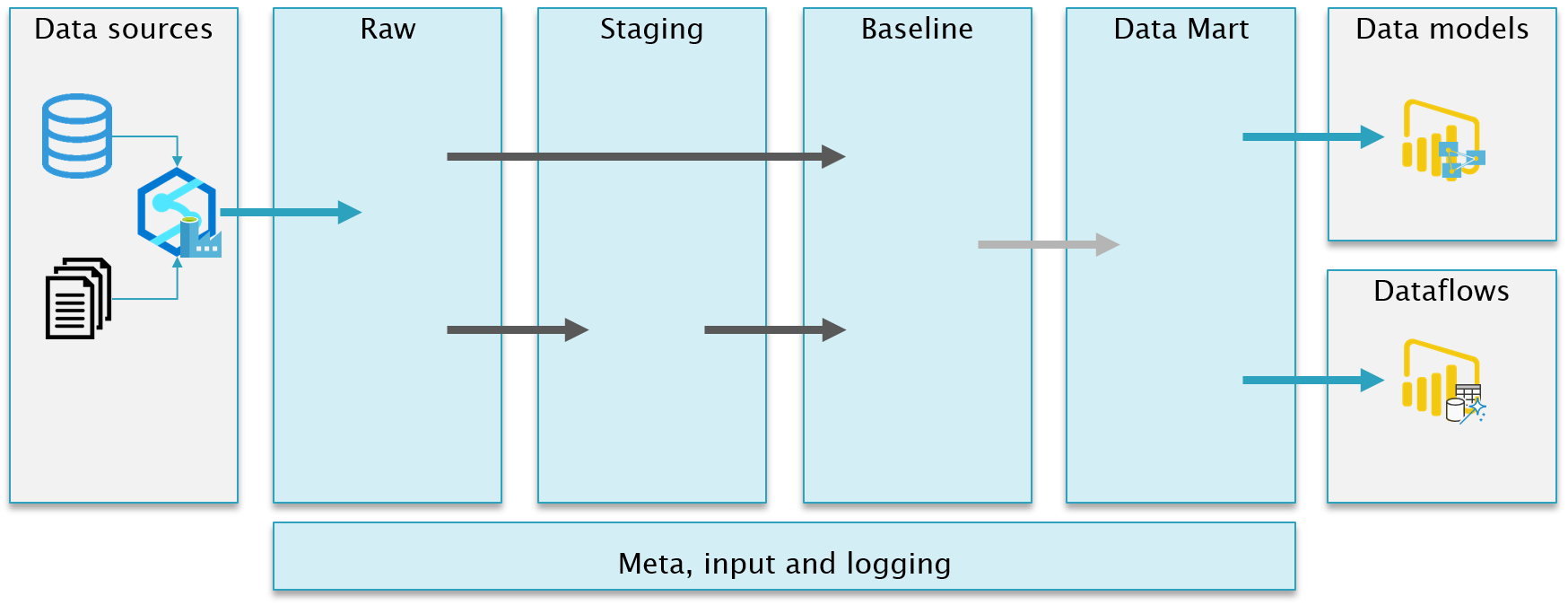
The black arrows is where the "magic" happens. Here we move and transform data from one layer to the next. The transformation is defined in views and a couple of generic stored procedures is then taking the output of the views and persist the data in tables in the next layer. The blue arrows represent moving data in and out of the SQL Database and is handled with Integration Pipelines.
Contains data from each of the different source data systems. The data is stored as is, with no transformation. All tables is extended with an addtional column with the PipelineRunId.
An optional layer if common cleansing or transformation is needed before building the facts and dimensions.
Data is stored in a dimensional star schema as facts and dimensions.
A view only layer with minimal logic. Mostly handling naming, selecting columns and filtering rows. This is the "contract" between the Data Warehouse and the serving layer (data models and dataflows).
Contains stored proedures and tables to handle custom logging on pipeline and task level. Captures duration, row counts, error messages etc. Also gets the service tier of the Azure Database, so you can compare duration against cost.
The pipelines serves two main purposes: Ingesting data and orchestrating the ETL process. In my opinion, this is the best Azure service to do these jobs. Not only in this solution, but in general. You will find these four templates that is all ready for you to import:
- Dynamic pipeline to ingest data from a SQL based source system
- Dynamic pipeline to transform dimensions and facts with the use of the SQL database
- Utility pipeline to scale Azure SQL database
- Utility pipeline to refresh a Power BI data model
You can either deploy the templates to Azure Data Factory or Azure Synapse Analytics. The functionality and cost of runing the pipelines is the same.
It's easy to build the master pipeline, as it's just a matter of calling the other pipeline in the correct order and with the right parameters. Here is an example:
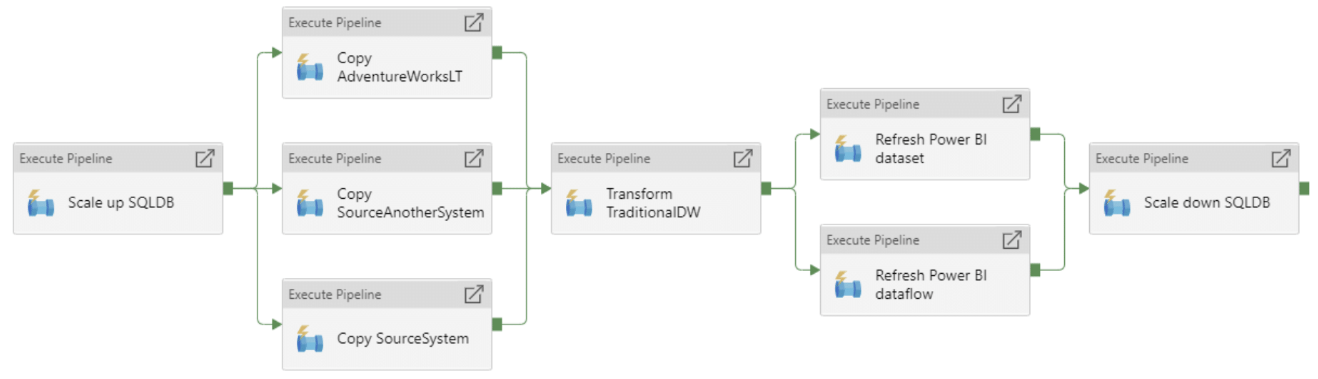
You will need to create a Linked Service to your Azure SQL database to be able to import the "transform pipeline". If you also want to use the ingest pipeline, then you need one or more Linked Services to your Azure SQL based source system(s). The example transformation in this solution is using the AdventureWorksLT database as a source system. You can create this as a sample database, when creating a new SQL database in Azure.
A series of scripts to quickly build a data model with the free version of Tabular Editor, that you can then deploy directly to Power BI with the use of the XMLA endpoint.
Unlock Analysis Services in Power BI, so you can deploy your "enterprise" data models directly.
The solution also consist of some additional components
- Data Lake Storage
- Azure Monitor (Log Analytics)
- Key Vault
See a slightly older presentation of the solution on my YouTube channel. It's recorded as part of the SQLDay 2020 conference: https://www.youtube.com/watch?v=vpId9bOqVJs&ab_channel=justB