This directory contains the code for training models using DDSP modules. The current supported models are variants of an audio autoencoder.
Unlike the base ddsp/ library, this folder is actively modified for new
experiments and has a higher chance of making breaking changes in the future.
Functions and classes marked EXPERIMENTAL in their doc string are under active development and very likely to change. They should not be expected to be maintained in their current state.
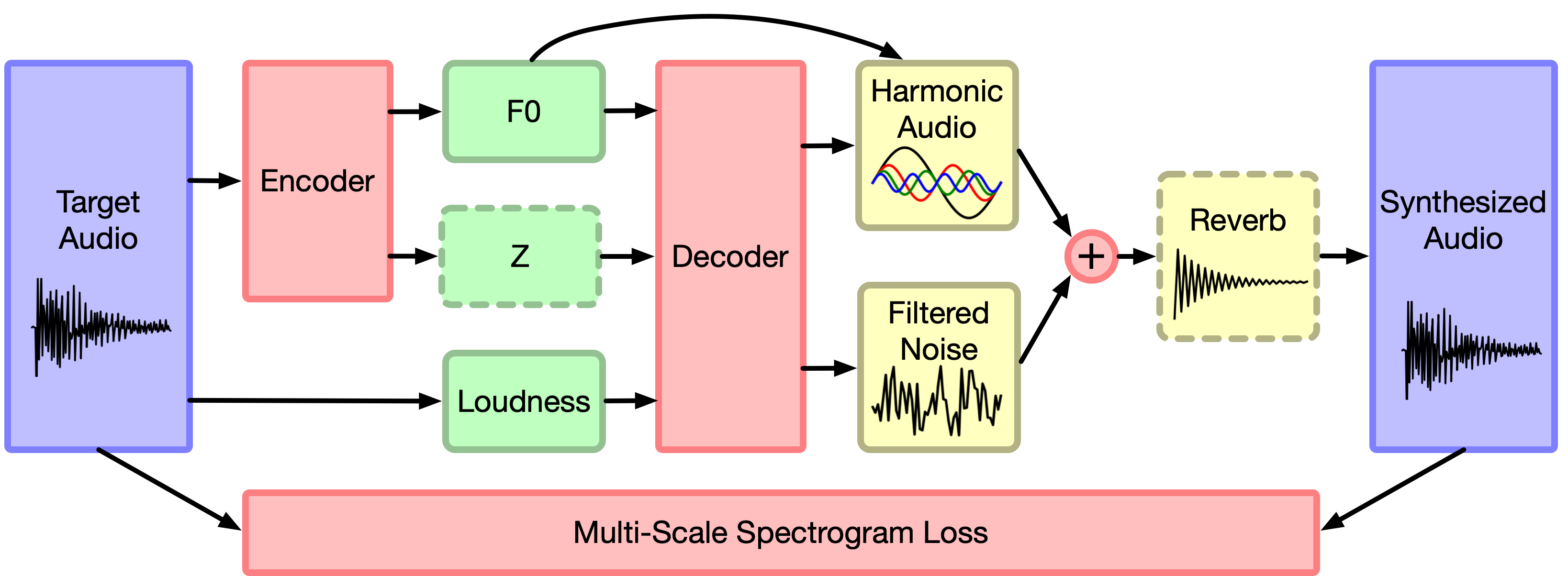
The DDSP training libraries are separated into several modules:
- data: DataProvider objects provide tf.data.Dataset.
- models: Model objects define the full forward pass and losses.
- preprocessing: Preprocessor objects format and scale model inputs.
- encoders: Layers to turn preprocessor outputs into latents.
- decoders: Layers to turn latents into ddsp processor inputs.
- nn: Network functions and layers.
- inference: Model wrappers for efficient inference and the ability to store as SavedModels.
The main training file is ddsp_run.py and its helper libraries:
- ddsp_run: Main file for launching training, evaluation, and sampling runs.
- train_util: Training loop and helper functions.
- trainers: Training step defined by helper objects that bind the strategy, optimizer, and model.
- eval_util: Evaluation and sampling loop.
- evaluators: Evaluator objects responsible for computing metrics and summaries.
- metrics: Metrics for evaluation.
- summaries: Summaries for tensorboard images and audio of samples.
While the modules in the ddsp/ base directory can be used to train models
with tf.compat.v1 or tf.compat.v2 this directory only uses tf.compat.v2.
The pip installation includes several scripts that can be called directly from the command line.
Hyperparameters are configured via gin, and ddsp_run.py must be given three
--gin_file flags, one from gin/models, one from gin/datasets, and one from gin/eval. The
files in gin/papers include both the dataset, model, and evaluation files for reproducing experiments from a specific paper.
By default, the program searches for gin files in the installed ddsp/training/gin location, but additional search paths can be added with --gin_search_path
flags. Individual parameters can also be set with multiple --gin_param flags.
This example below streams a version of the NSynth dataset from GCS.
If not running on GCP, it is much faster to first download the dataset with
tensorflow_datasets, and add the flag
--gin_param="NSynthTfds.data_dir='/path/to/tfds/dir'":
ddsp_run \
--mode=train \
--save_dir=/tmp/$USER-ddsp-0 \
--gin_file=papers/iclr2020/nsynth_ae.gin \
--gin_param="batch_size=16" \
--alsologtostderrddsp_run \
--mode=eval \
--save_dir=/tmp/$USER-ddsp-0 \
--gin_file=dataset/nsynth.gin \
--gin_file=eval/basic_f0_ld.gin \
--alsologtostderrddsp_run \
--mode=sample \
--save_dir=/tmp/$USER-ddsp-0 \
--gin_file=dataset/nsynth.gin \
--gin_file=eval/basic_f0_ld.gin \
--alsologtostderrWhen training, all gin parameters in the
operative configuration
will be saved to the ${MODEL_DIR}/operative_config-0.gin file, which is then loaded for evaluation, sampling, or further training. The operative config is also visible as a text summary in tensorboard. See
this doc
for more details.
For backwards compatability, we keep track of changes in function signatures in update_gin_config.py, which can be used to update old operative configs to work with the current library.
To use a Cloud TPU for any of the above commands, there are a few minor changes.
First, your model directory will need to accessible to the TPU. This means it will need to be located in a GCS bucket with proper permissions.
Second, you will need to add the following flag:
--tpu=grpc://<TPU internal IP address>:8470 \
The TPU internal IP address can be found in the Cloud Console.
TFRecord dataset out of a folder of .wav or .mp3 files
ddsp_prepare_tfrecord \
--input_audio_filepatterns=/path/to/wavs/*wav \
--output_tfrecord_path=/path/to/dataset_name.tfrecord \
--num_shards=10 \
--alsologtostderrddsp_run \
--mode=train \
--save_dir=/tmp/$USER-ddsp-0 \
--gin_file=models/solo_instrument.gin \
--gin_file=datasets/tfrecord.gin \
--gin_file=eval/basic_f0_ld.gin \
--gin_param="TFRecordProvider.file_pattern='/path/to/dataset_name.tfrecord*'" \
--gin_param="batch_size=16" \
--alsologtostderr