Sleipnir allows you to specify clojure routines to use with battle-tested web-crawlers (heritrix in particular).

First, download and spin up a Heritrix instance (REQUIRED for a crawl to complete).
wget https://s3-us-west-2.amazonaws.com/sleipnir-heritrix/heritrix-3.3.0-SNAPSHOT-dist.zip
unzip heritrix-3.3.0-SNAPSHOT-dist.zip
cd heritrix-3.3.0-SNAPSHOT-dist
./bin/heritrix -a admin:admin
Now Heritrix is running at https://localhost:8443 and can be accessed with the username/pass : admin/admin.
Next, let us set up a simple crawl using clojure routines.
We start with the imports:
(ns sleipnir.demo
"Dude this is the demo"
(:require [net.cgrand.enlive-html :as html]
[sleipnir.handler :as handler]
[org.bovinegenius.exploding-fish :as uri])
(:import [java.io StringReader]))Say, I want to walk through reddit's pagination. We use enlive selectors for our extractor code:
(defn reddit-pagination-extractor
"Pulls reddit pagination using enlive"
[url body]
(let [resource (-> body (StringReader.) html/html-resource)
anchors (html/select resource [:span.nextprev :a])]
(filter
identity
(map
(fn [an-anchor]
(println an-anchor)
(try (uri/resolve-uri url
(-> an-anchor
:attrs
:href))))
anchors))))Then, we want to store the submitted links in some location
(defn reddit-submission-links-writer
"Gets links to reddit submissions"
[url body wrtr]
(let [resource (-> body (StringReader.) html/html-resource)
submissions (html/select resource
[:p.title :a.title])
links (filter
identity
(map
(fn [an-anchor]
(try (uri/resolve-uri url
(-> an-anchor
:attrs
:href))))
submissions))]
(doseq [link links]
(binding [*out* wrtr]
(println link)))))And then set up and execute the crawl. The config object has a ton of options (I'll flesh the documentation out soon). Several of these options tweak Heritrix's settings.
(handler/crawl {:heritrix-addr "https://localhost:8443/engine"
:job-dir "/Users/shriphani/Documents/reddit-job"
:username "admin"
:password "admin"
:seeds-file "/Users/shriphani/Documents/reddit-job/seeds.txt"
:contact-url "http://shriphani.com/"
:out-file "/tmp/bodies.clj"
:extractor reddit-pagination-extractor
:writer reddit-submission-links-writer})In the config above, we specify where heritrix is launched, the job directory, the payload directory and the extraction and writer routines.
The result is a heritrix job that walks through the pagination and dumps
the submitted links to /tmp/bodies.clj.
Here's a screengrab of the job:
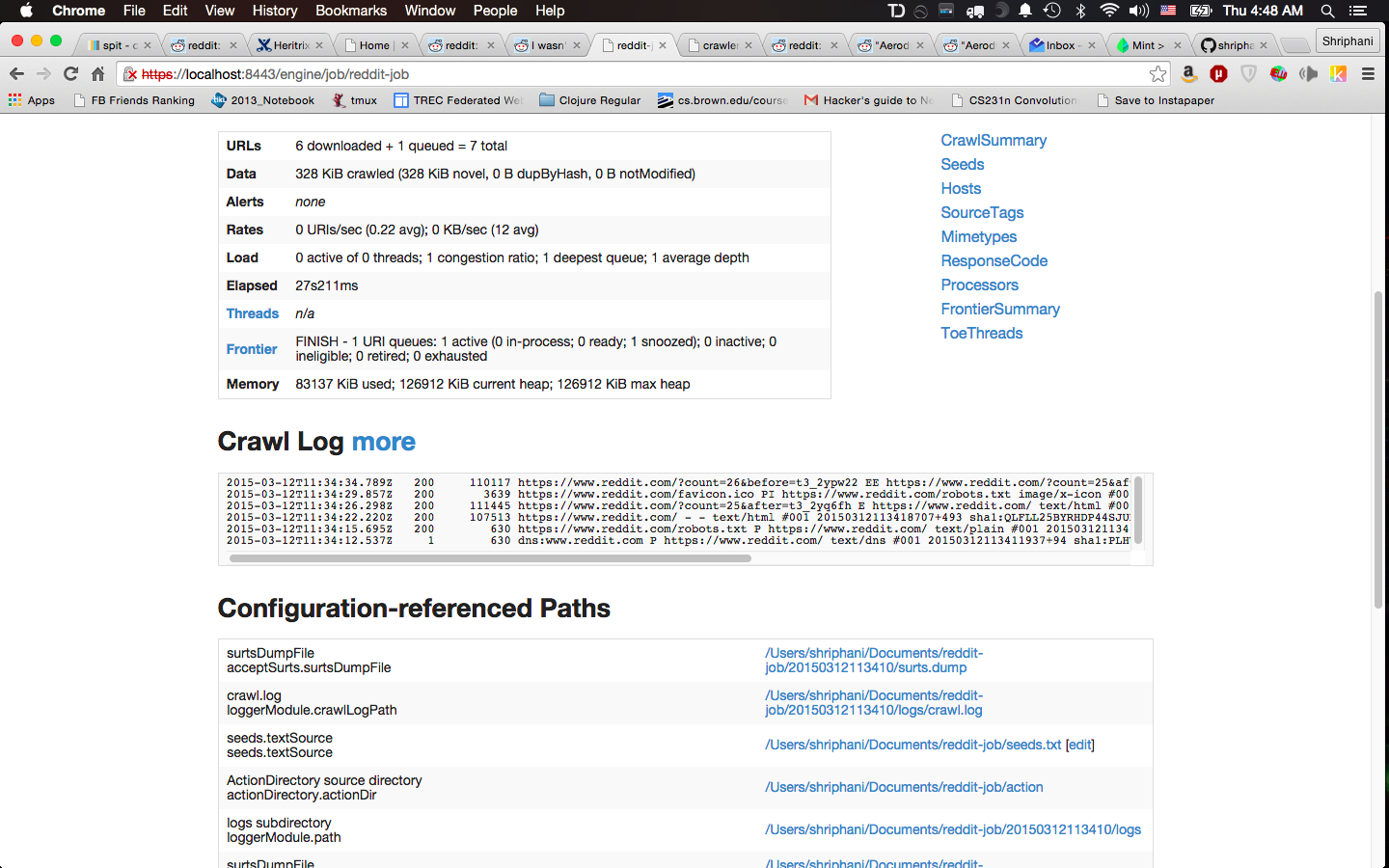
And here's a snapshot of the recorded submission links:
https://www.reddit.com/r/tifu/comments/2ys7wr/tifu_by_attempting_to_clean_the_kitchen/
http://uatoday.tv/politics/ukraine-calls-for-russian-documentary-on-crimea-to-be-sent-to-hague-tribunal-414713.html
https://www.reddit.com/r/Music/comments/2ys88r/check_out_our_free_ep_feathers_by_divide_of/
https://s-media-cache-ak0.pinimg.com/736x/19/f6/18/19f618637135ec676d0dfdcd4d23b542.jpg
http://imgur.com/HqG6Udq
https://www.reddit.com/r/Jokes/comments/2ys8a9/did_you_hear_about_the_nympho_waitress/
https://www.reddit.com/r/AskReddit/comments/2ys8bb/hey_reddit_what_is_a_great_classic_or_family/
http://imgur.com/qTKH4pA
...
...
## License
Copyright © 2015 Shriphani Palakodety