My Pet Project. rururu (るるる) is a simple scraping tool. 「るるる」はシンプルなスクレイピングツールです。
- Get values with URLs and Elements. URLと検索要素(XPathなど)を指定して文字列を抽出
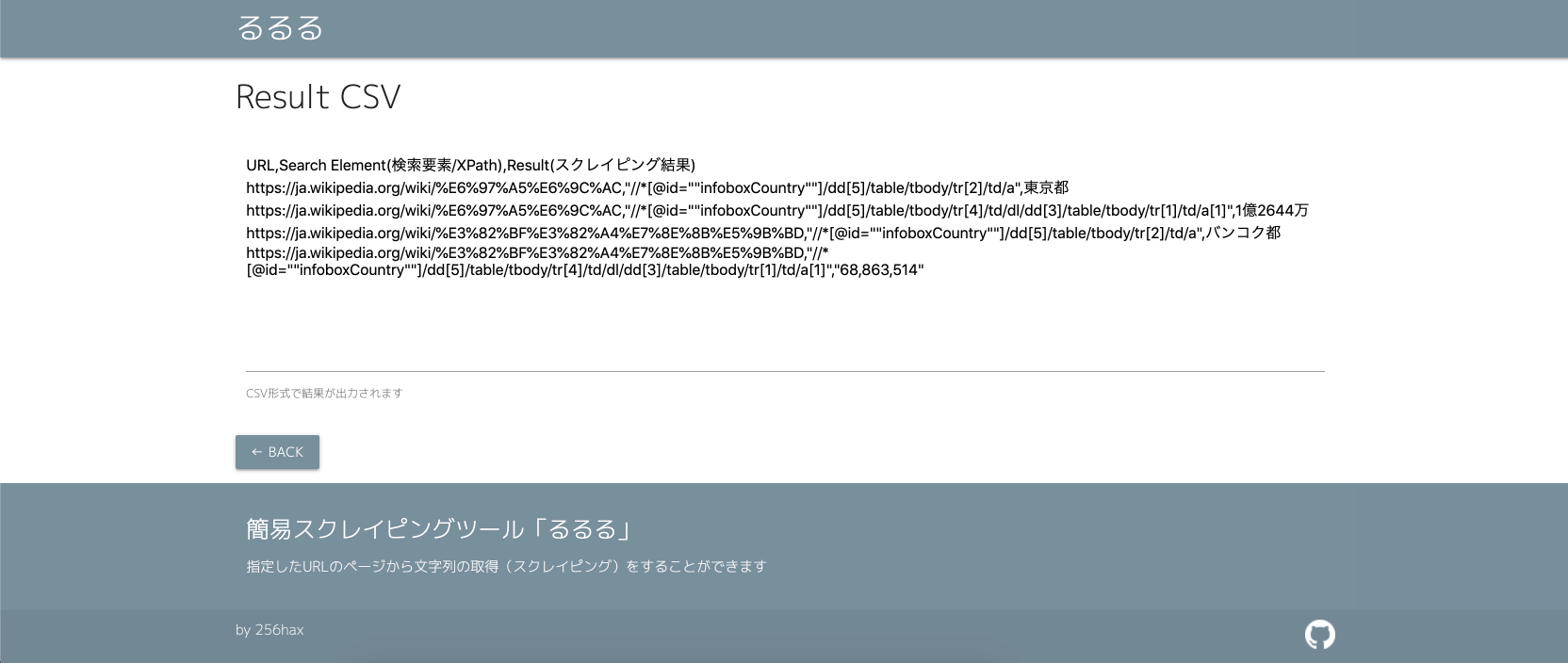
- CSV output. 抽出結果はCSV形式で出力
- Sleep per one scraping for prevent being consider an attack. スクレイピング中に攻撃とみなされないように1スクレイピング毎にスリープ時間を定義
- App file is only One-File also including images on Sinatra. Sinatraを使って1ファイルのみで開発
- Install Ruby
- Download & Unarchive rururu(るるる) zip in GitHub
- $ cd [Unarchive rururu folder]
- $ gem install bundler:2.0.1
- $ gem update bundler
- $ bundle install --path vendor/bundle
- $ cd [Unarchive rururu folder]
- $ bundle exec ruby app.rb
- Open http://localhost:4567/ in browser
- [Enjoy scraping!]
- If you want to stop it, control + C in Terminal
例:Wikipediaの日本とタイ王国のページをスクレイピングする場合
https://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC
https://ja.wikipedia.org/wiki/%E3%82%BF%E3%82%A4%E7%8E%8B%E5%9B%BD
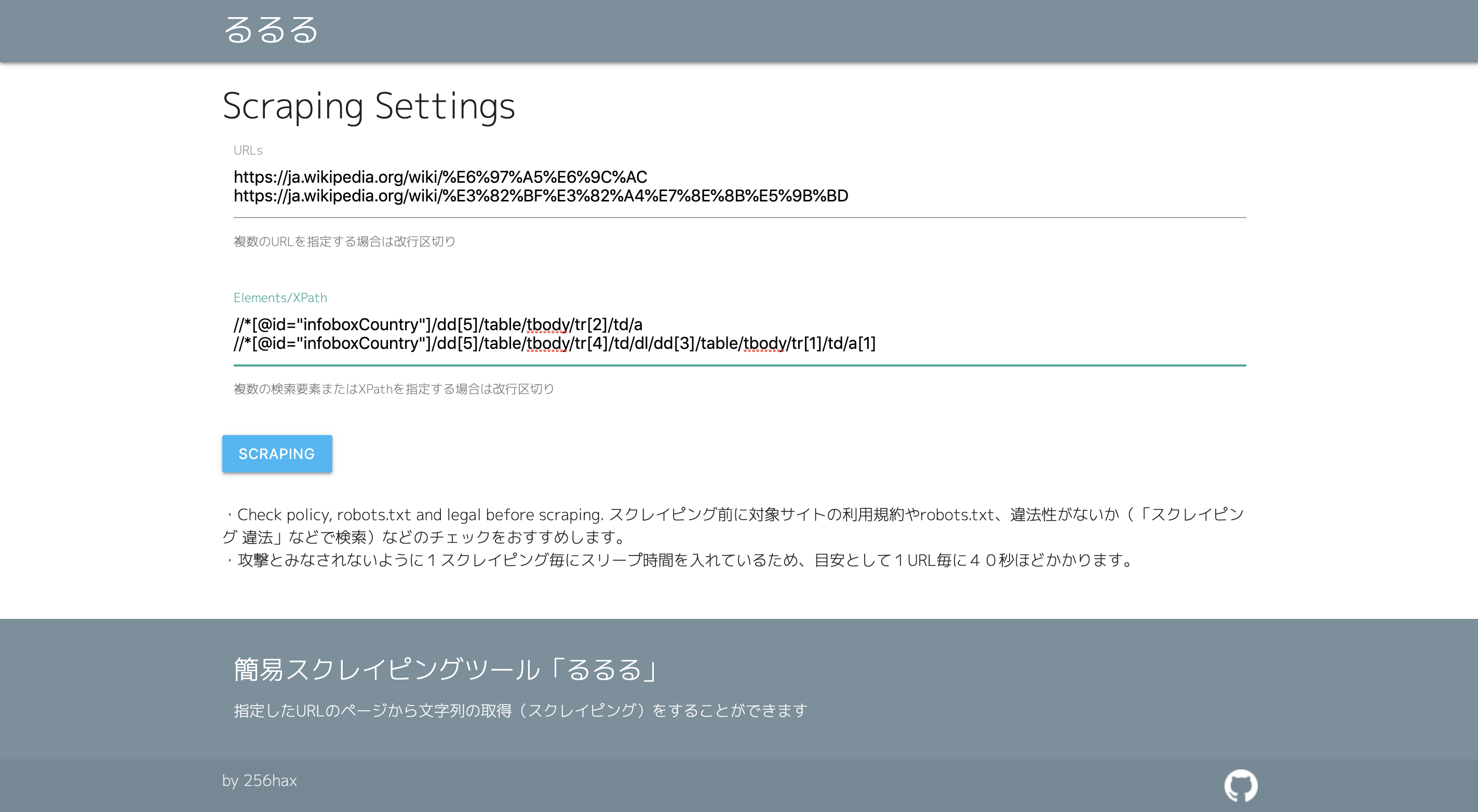
例:首都と人口をXPathで取得する場合
//*[@id="infoboxCountry"]/dd[5]/table/tbody/tr[2]/td/a
//*[@id="infoboxCountry"]/dd[5]/table/tbody/tr[4]/td/dl/dd[3]/table/tbody/tr[1]/td/a[1]
XPathはChromeの検証ツールでかんたんに取得できます。取得方法は「Chrome XPath」で検索してみてください。
または、タグとクラス名で取得する場合、「[タグ名].[クラス名]」として指定できます。
dt.infoboxCountryNameJa
- Copy & Paste result(textarea) values to textpad. スクレイピング結果をメモ帳などにコピペ
- Save as somename.csv. 適当な名前をつけてCSV形式で保存