2) Nerf (radiance fields) basics, frameworks and real world uses
- Neural implicit surfaces
- Nerf Basics, 2020
- Capture
- Registration, 2023
- Speed optimizations
- Capture
- Light fields without nerf
- Open Nerf Frameworks, 2023
- Known real world uses
Table of contents generated with markdown-toc
https://www.matthewtancik.com/nerf Representing Scenes as Neural Radiance Fields for View Synthesis
- https://www.youtube.com/watch?v=nCpGStnayHk Two Minute Papers explanation
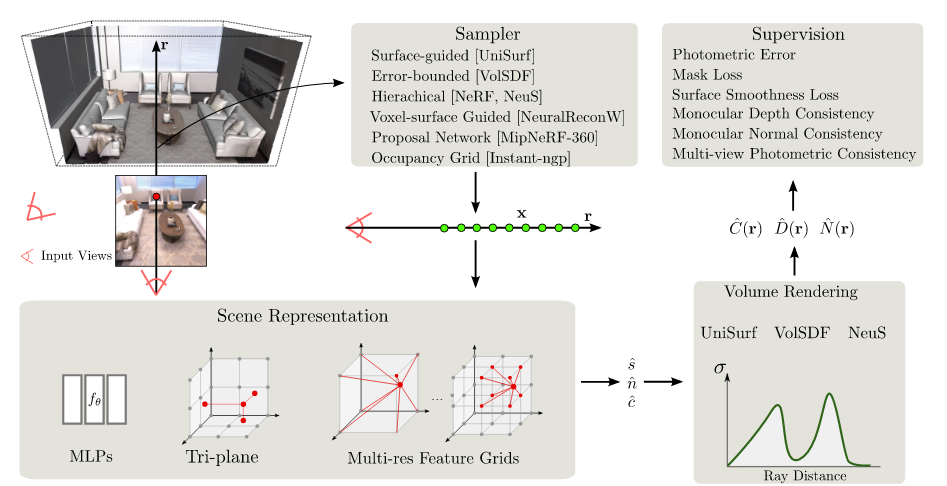
Represent a static scene as a continuous 5D function that outputs the radiance emitted in each direction (theta, phi) at each point (x; y; z) in space, and a density at each point which acts like a differential opacity controlling how much radiance is accumulated by a ray passing through (x; y; z).
Uses regressing from a single 5D coordinate (x; y; z; theta, phi) to a single volume density and view-dependent RGB color.
NeRF uses a differentiable volume rendering formula to train a coordinate-based multilayer perceptron (MLP) to directly predict color and opacity from 3D position and 2D viewing direction. It is a recent and popular volumetric rendering technique to generate images is Neural Radiance Fields (NeRF) due to its exceptional simplicity and performance for synthesizing high-quality images of complex real-world scenes.
The key idea in NeRF is to represent the entire volume space with a continuous function, parameterized by a multi-layer perceptron (MLP), bypassing the need to discretize the space into voxel grids, which usually suffers from resolution constraints. It allows real-time synthesis of photorealistic new views.
NeRF is good with complex geometries and deals with occlusion well.

Advances in Neural Rendering, https://arxiv.org/abs/2111.05849 Source: Advances in Neural Rendering, https://www.neuralrender.com/
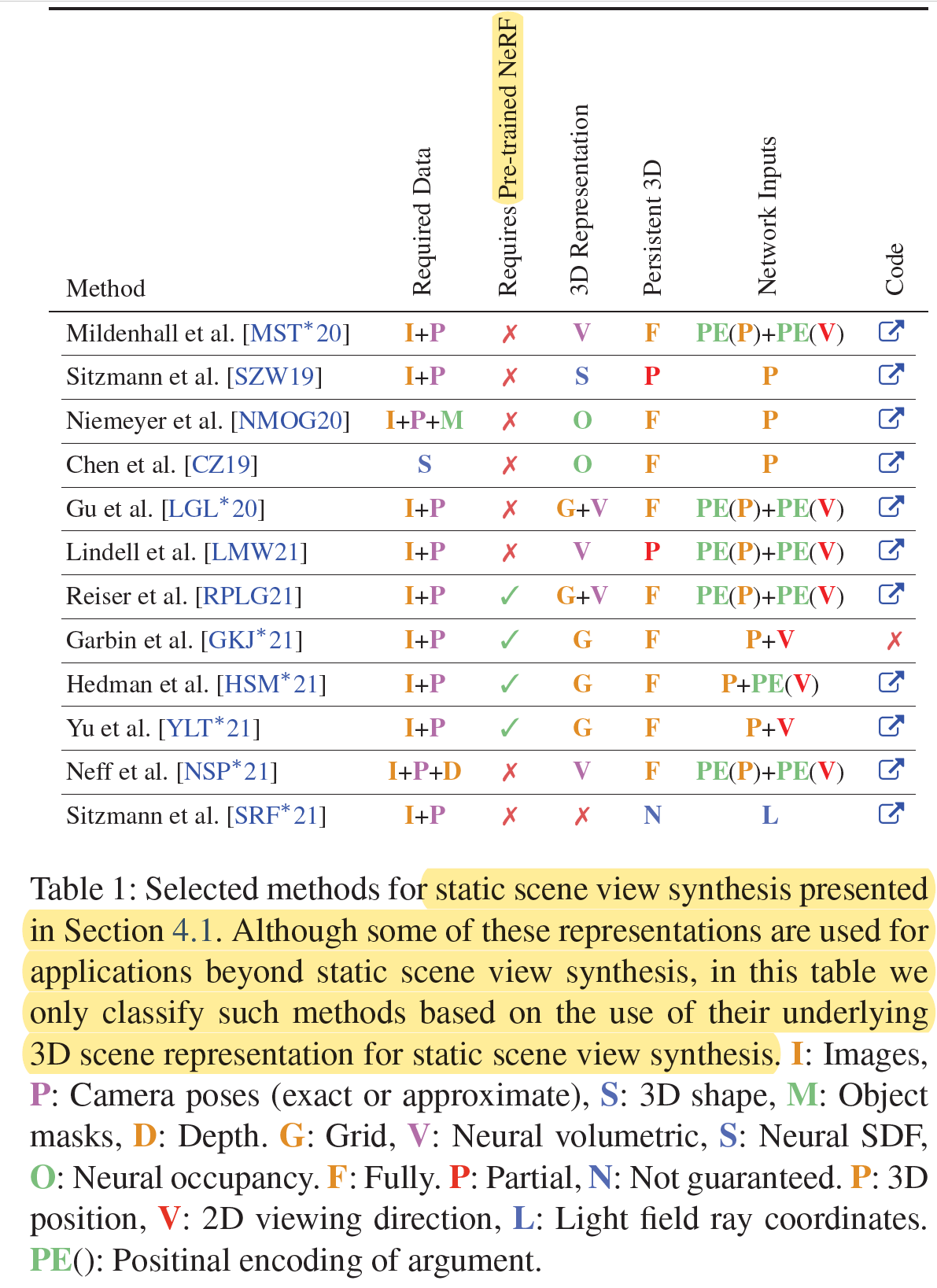
- Camera calibration is often assumed to be a prerequisite, while in practice, this information is rarely accessible, and requires to be pre-computed with conventional techniques, such as **Structure form motion (SfM) **.
- A common SfM frame work is Colmap https://colmap.github.io/
Neural volume rendering refers to methods that generate images or video by tracing a ray into the scene and taking an integral of some sort over the length of the ray. Typically a neural network like a multi-layer perceptron (MLP) encodes a function from the 3D coordinates on the ray to quantities like density and color, which are integrated to yield an image. One of the reasons NeRF is able to render with great detail is because it encodes a 3D point and associated view direction on a ray using periodic activation functions, i.e., Fourier Features.
The impact of the NeRF paper lies in its brutal simplicity: just an MLP taking in a 5D coordinate and outputting density and color yields photoreastic results. The initial model had limitations: Training and rendering is slow and it can only represent static scenes. It “bakes in” lighting. A trained NeRF representation does not generalize to other scenes or objects. All of these problems have since developed further, there are even realtime nerfs now. A good overview can be found in "NeRF Explosion 2020", https://dellaert.github.io/NeRF.
depth_reflower.mp4
https://dellaert.github.io/NeRF/ Source: https://towardsdatascience.com/nerf-and-what-happens-when-graphics-becomes-differentiable-88a617561b5d
A deeper integration of graphics knowledge into the network is possible based on differentiable graphics modules. Such a differentiable module can for example implement a complete computer graphics renderer, a 3D rotation, or an illumination model. Such components add a physically inspired inductive bias to the network, while still allowing for end-to-end training via backpropagation. This can be used to analytically enforce a truth about the world in the network structure, frees up network capacity, and leads to better generalization, especially if only limited training data is available.

Source: Advances in Neural Rendering, https://www.neuralrender.com/
Speed up interactive nerf generation to almost realtime by using CUDA and Hash encoding (described below) making it accessible to a wider audience. Implementation of four neural graphics primitives, being neural radiance fields (NeRF), signed distance functions (SDFs), neural images, and neural volumes. In each case, we train and render a MLP with multiresolution hash input encoding using the tiny-cuda-nn framework.
https://github.com/NVlabs/instant-ngp/raw/master/docs/assets_readme/fox.gif See also https://github.com/3a1b2c3/seeingSpace/wiki/NVIDIA-instant-Nerf-on-google-colab,-train-a-nerf-without-a-massive-gpu
https://betterprogramming.pub/nerf-at-cvpr23-arbitrary-camera-trajectories-5a015cfc9d63

- Practical tip for capturing https://www.linkedin.com/posts/jonathanstephens_how-to-capture-images-for-3d-reconstruction-activity-6979541705494597632-rlRs
https://github.com/ripl/nerfuser


What is PSNR (Peak Signal to Noise Ratio)? What is SSIM (Structural Similarity Index Measure)? What is LPIPS (Learned Perceptual Image Patch Similarity)? What is Whole-scene Average Prediction Error (WAPE)? https://neuralradiancefields.io/what-are-the-nerf-metrics/
Encodings comparison https://docs.nerf.studio/en/latest/nerfology/model_components/visualize_encoders.html
Whereas discrete signal representations like pixel images or voxels approximate continuous signals with regularly spaced samples of the signal, these neural fields approximate the continuous signal directly with a continuous, parametric function, i.e., a MLP which takes in coordinates as input and outputs a vector (such as color or occupancy).
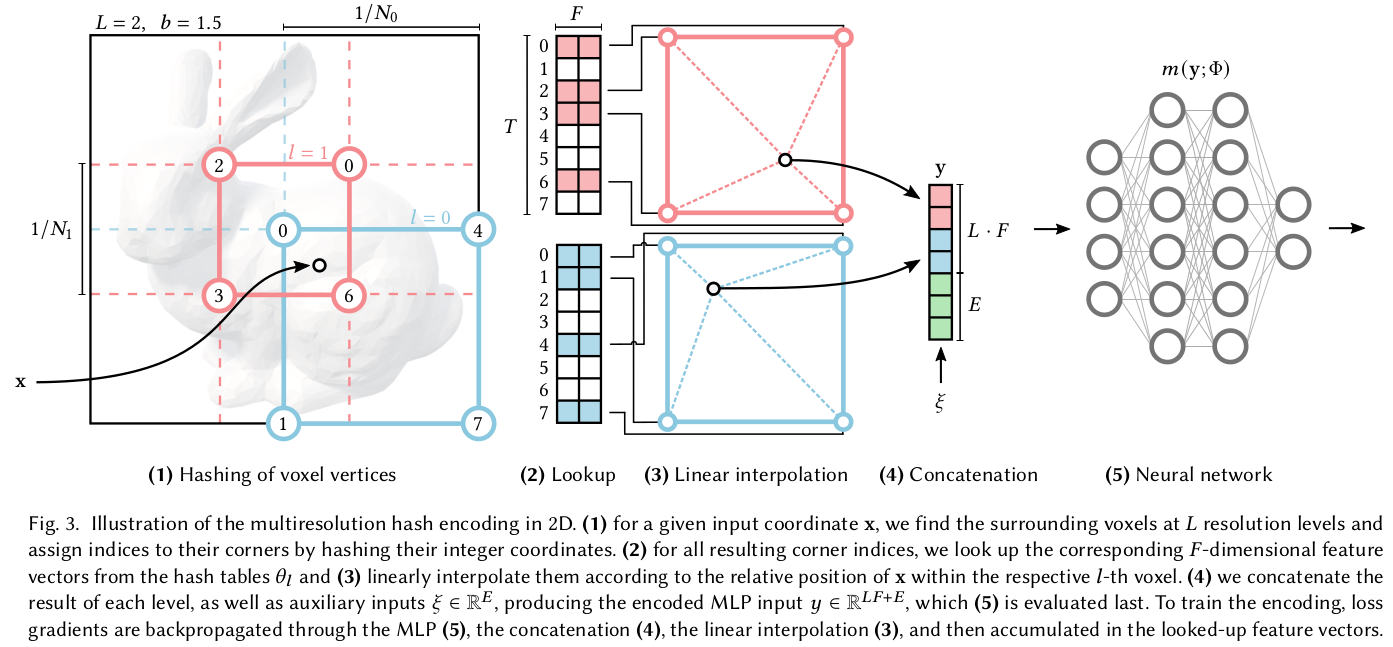
image Neural approximations of scalar- and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids
From Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
A demonstration of the reconstruction quality of different encodings and parametric data structures for storing trainable feature embeddings. Each configuration was trained for 11 000 steps using our fast NeRF implementation (Section 5.4), varying only the input encoding and MLP size. The number of trainable parameters (MLP weights + encoding parameters), training time and reconstruction accuracy (PSNR) are shown below each image. Our encoding (e) with a similar total number of trainable parameters as the frequency encoding configuration (b) trains over 8× faster, due to the sparsity of updates to the parameters and smaller MLP. Increasing the number of parameters (f) further improves reconstruction accuracy without significantly increasing training time.
Comparison of Encodings (from instant nerf paper) A practical introduction https://keras.io/examples/vision/nerf/#setup
The term peak signal-to-noise ratio (PSNR) is an expression for the ratio between the maximum possible value (power) of a signal and the power of distorting noise that affects the quality of its representation

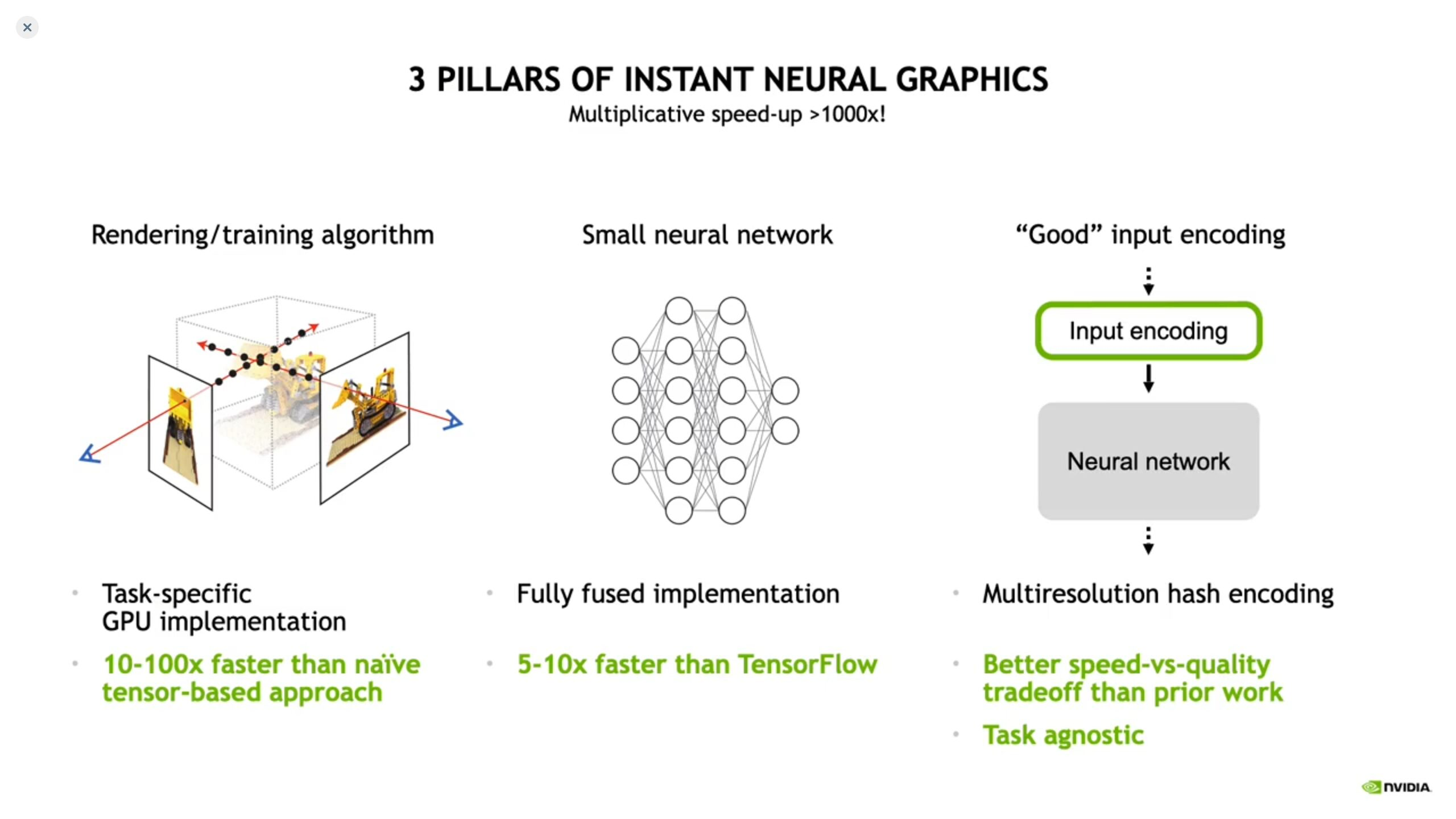
 https://github.com/NVlabs/instant-ngp
https://github.com/NVlabs/instant-ngp
https://neuralradiancefields.io/optimal-camera-placements-for-nerfs-in-subject-free-spaces/

{kind=link}
-
https://github.com/graphdeco-inria/gaussian-splatting
 But what are 3D Gaussians? They are a generalization of 1D Gaussians (the bell curve) to 3D. Essentially they are ellipsoids in 3D space, with a center, a scale, a rotation, and "softened edges". https://www.reshot.ai/3d-gaussian-splatting
But what are 3D Gaussians? They are a generalization of 1D Gaussians (the bell curve) to 3D. Essentially they are ellipsoids in 3D space, with a center, a scale, a rotation, and "softened edges". https://www.reshot.ai/3d-gaussian-splatting
https://research.nvidia.com/labs/dir/neuralangelo/
https://github.com/3a1b2c3/seeingSpace/wiki/Hands-on:-Getting-started-and-Nerf-frameworks
- immersive view https://github.com/3a1b2c3/seeingSpace/wiki/3)-Nerf-for-3d-mapping:-aka-Google-live-view-and-Apple-Fly-around
- Meta research https://www.youtube.com/watch?v=hvfV-iGwYX8&t=4400s
- https://lumalabs.ai/ Result https://captures.lumalabs.ai/me Texture

- Common Sense Machines https://csm.ai/commonsim-1-generating-3d-worlds/

- Google project Starline https://blog.google/technology/research/project-starline-expands-testing/
