A text-file based method of updating stash scene metadata.
Stash scene metadata import using YAML files.
Generate YAML files that associate scene files with metadata and then use them to update your stash.
Suppose you had a directory with two files:
C:\Videos\Jane Doe - My First Scene (2021.10.11).mp4
C:\Videos\Jill, Jack - Another Scene (2021.11.08).mp4
The contents of a blank mapping file generated from this directory looks like:
C:\Videos\Jane Doe - My First Scene (2021.10.11).mp4:
performers:
- name: ''
url: ''
date: ''
title: ''
url: ''
C:\Videos\Jill, Jack - Another Scene (2021.11.08).mp4:
performers:
- name: ''
url: ''
date: ''
title: ''
url: ''Once you fill in the mapping file with the metadata you want, use it to update your stash scenes by running the process mapping task with the update stash option, or running from the command line with the update stash option. See the walkthrough section below for details.
- All the fields are optional (
name,url,date,title). You can leave them empty and they will just be ignored when the mapping file is used to update stash.
A mapping file can be generated with metadata already filled in by parsing filenames. A mapping file generated with filename parsing enabled looks like:
C:\Videos\Jane Doe - My First Scene (2021.10.11).mp4:
performers:
- name: Jane Doe
url: ''
date: '2021-10-11'
title: My First Scene
url: ''
C:\Videos\Jill, Jack - Another Scene (2021.11.08).mp4:
performers:
- name: Jill
url: ''
- name: Jack
url: ''
date: '2021-11-08'
title: Another Scene
url: ''You can also add performers to the mapping, just add more name, url entries. Note: Correct indentation is important.
- name:
url:
- name:
url:
You can fill in the performer urls yourself, or the mapping process can automatically fill in urls from names if the names exist in stash.
The mapping process can create new performers by scraping urls if there's a supported stash scraper for them. If there's no scraper, a new performer with just name and url is created.
If you're only interested in mapping performers to files, there is a simplified format:
C:\Videos\Jane Doe - My First Scene (2021.10.11).mp4:
- name: Jane Doe
url: ''
C:\Videos\Jill, Jack - Another Scene (2021.11.08).mp4:
- name: Jill
url: ''
- name: Jack
url: ''Python 3.6+
The mapper can be used as a plugin which launches a GUI window or it can be run as a command line script.
I've tested the plugin on Windows. Linux and Mac compatibility is unknown. If you're using stash on Docker or the plugin doesn't work, just use the command line script.
Place the stash_metadata_mapper folder in your stash plugins folder
Fill in config.py with the path to your stash database file (by default stash-go.sqlite)
Run pip install -r requirements.txt in the stash_metadata_mapper folder
Fill in config.py with the absolute path to your stash database file (by default it should be something like /path/to/stash/root/stash-go.sqlite), stash api key, and stash url
Run pip install -r requirements.txt in the stash_metadata_mapper folder
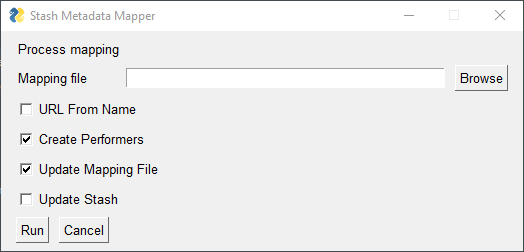
Run the tasks and a GUI window will appear. The options in the GUI correspond to the script command line arguments described below

The command line script is cli.py
-d,--directory<path to folder>Generate a YAML mapping file from files in given directory-p,--process<path to file>Process the given YAMl mapping file-o,--output<path to file>YAML file output destination--input_zip<path to stash export zip>Generate a YAML mapping file from a stash export zip--input_json<path to stash export mappings.json>Generate a YAML mapping file from a stash export mappings.json--api_keyStash API key--server_urlStash server URL--performer_onlyGenerate a performer only mapping file. Useful if you are only interested in updating scenes with performers and no other scene metadata--parse_filenamesParse filenames for metadata according to a pattern. If your filenames follow a pattern, i.e.{performer} - {title} ({date}).{ext}, parsing filenames can prefill the mapping--filename_patternRegex pattern describing how to parse filenames--url_from_namePopulate performer urls in mapping by looking up names in stash for existing performers--create_performersCreate missing performers in stash by scraping performer url--update_stashUpdate stash scene metadata according to mapping--no_update_mapfileDon't modify the input mapping file. Processing a mapping file may modify it, i.e. theurl_from_nameoption fills in the mapping performer urls based on performer names. Use no_update_mapfile to prevent the mapping file from being updated.
Note: you may need to replace py with python or python3 when you run commands, depending on your setup
-
Generate a mapping file:
-
From a directory of files
py cli.py --directory C:\Videos --parse_filenames --filename_pattern patternmapping.yamlwill be created inC:\Videos -
From a stash export zip
py cli.py --directory C:\export20211112-185658.zip --parse_filenames --filename_pattern patternmapping.yamlwill be created inC: -
From a stash export mappings.json
py cli.py --directory C:\export20211112-185658\mappings.json --parse_filenames --filename_pattern patternmapping.yamlwill be created inC:\export20211112-185658
-
-
Fill in performer urls in mapping from performer names in mapping:
py cli.py --process C:\Videos\mapping.yaml --url_from_name -
Create missing performers from performer urls:
py cli.py --process C:\Videos\mapping.yaml --create_performers -
Review
mapping.yamland fill in an missing data or make corrections. You can repeat steps 2 and 3 as needed. Both options can be used at the same time as well:py cli.py --process C:\Videos\mapping.yaml --url_from_name --create_performers -
Update stash scenes according to mapping:
py cli.py --process C:\Videos\mapping.yaml --update_stash- Note: Up to this point, the files in the mapping don't need to have been scanned into stash yet. But you will need to scan your files into stash for
update_stashto work.
- Note: Up to this point, the files in the mapping don't need to have been scanned into stash yet. But you will need to scan your files into stash for
detailsaren't included when generating a full mapping, but you can add them in and they will be processed, i.e.
C:\Videos\Jane Doe - My First Scene (2021.10.11).mp4:
performers:
- name: Jane Doe
url: ''
date: '2021-10-11'
title: My First Scene
url: ''
details: This is a description of the sceneThe filename_pattern option allows you to pass a regex pattern describing how to parse filenames for metadata.
The parser checks for the following named capture groups: studio, title, date, performers
Parsing support is currently limited as it's been developed with my own particular file-naming conventions in mind. Feel free to open an issue describing the filename parsing support you need and I'll try to implement it.
--filename_pattern "^(?P<date>\d{4}\-\d\d\-\d{2}) (?P<title>.*?)$" would parse filenames in the form {YYYY-MM-DD} {title}
If no filename_pattern is given, these are how the capture groups are defined:
studio: \[(?P<studio>[a-zA-Z0-9]+)\] alphanumeric, no spaces, surrounded by brackets
title: (?P<title>.*?) match any string of characters, non-greedy
performers: (?P<performers>[a-zA-Z0-9 ,']+) alphanumeric + spaces, comma-separated
date: \((?P<date>\d{2,4}\.\d\d\.\d{2,4})\) some variation of (XX.XX.XXXX), (XXXX.XX.XX) or (XX.XX.XX). parser tries to convert to YYYY-MM-DD if unambiguous, otherwise date is not used
If no filename_pattern is given, then the parser will try to match against a few default patterns constructed from the named capture groups defined above
{studio} {performers} - {title} {date}
{studio} {performers} - {title}
{studio} {performers} {date}
{studio} {performers}
{performers} - {title} {date}
{performers} - {title}
{title} {date}