Everyday we use a keyboard to communicate with our devices. We use them as a mean of communication with our PCs, but also with our smartphones and tablets (through software keyboards). More often than not they are all based on QWERTY, or its derivative, layout.
Throughout the last few decades, there have been attempts to increase the comfort of typing and typing speed, such as 'Dvorak', 'Colemak' or 'Workman'.
In this project, I propose yet another one layout (later on referred to as 'Optimized Layout'). Its aim is not to replace any previously mentioned, but simply to see how it relates to famous QWERTY layout.
The main assumption here is, that the easiest row to type on is the middle row and the most dominant fingers are index fingers. With these assumptions, we could say that the most comfortable letters to type are 'f' and 'j' (later on 'd' and 'k' etc.). Another assumption that it is easier to type using the top than the bottom row, and our dexterity in fingers decreases going outward (index, middle, ring, pinky). The below figure (Fig. 1.1) Should somehow give the feeling about those assumptions.

Fig. 1. The figure represents arbitrary ease of hitting each key - the darker the key, the easier is to hit.
The additional assumption is we use the touch typing technique, so we try to position our fingers as in the below picture (Fig. 1.2.).

We could also build a network (Fig. 1.3.) that would help us to visualize the above assumptions. Notice that connections weights between keys are based on how much certain keys overlap in non-ortholinear keyboards.
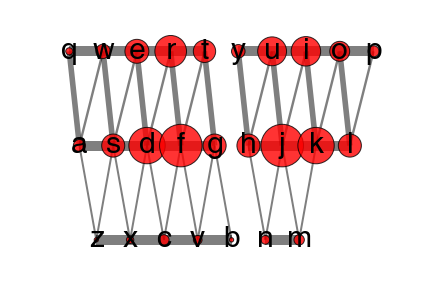
Fig 1.3. Network based on QWERTY non-ortholinear keyboard. The bigger the circle, the easier certain key is to type. Also the thicker the line that connects two keys, the more those keys overlap on Y or X axis.
First, we need some data to figure out how to relabel each key on the keyboard. In order to do this, I parsed 100 English books to find most occurrent letters (unigrams) and letter pairs (bigrams). Unigrams are to serve as analogy to 'the ease' of pressing a certain key - we would like to the most occurrent letter is the easiest to type, and cooccurrence (bigrams) serve as an analogy to key overlapping - it would be nice to have letters that frequently occur in pairs next to each other.
Thanks to the harvested data I was able to produce the below network (Fig 2.1.). Note that the bigger the circle with a certain letter, the more occurrent the letter is in the analyzed books and the thicker the line between letters, the more frequently those letters co-occur in the books' corpora.
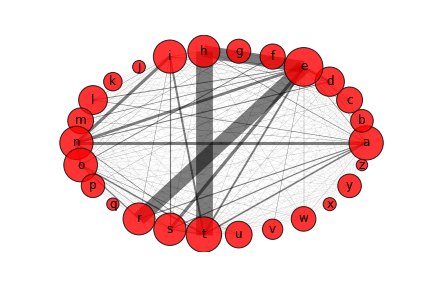
Fig. 2.1. Letters network.
We can see that the letter 'e' occurs much more frequently than the letter 'j', or that the letter 't' has a high chance to appear next to the letter 'h'.
Now it's time to combine the letters network (Fig. 2.1.) with the keyboard network (Fig. 1.3.). The expected product is the new (remapped) layout.
I started in the order of the easiest keys to type ('f', 'j', 'k' etc. - look at Fig. 1.1.) as they have the biggest weights to them. Now, one-by-one, each key was remapped to the highest scoring letter according to the criterion:
$max(\sum_{letter} \sum_{edge} [KN(key, edge)LN(letter, edge)] + 3KN(key)*LN(letter))$
where KN is keyboard network and LN is letters network. In other words we sum all the weights products (edges, connections) between keyboard keys and analogous letters (ie. we multiply the weight of the edge between certain key and its neighbour with the candidate letter and the neighbour), and we add the product between the key's relative importance and the letter's relative frequency with the weight of 3, so the dominant criterion is the frequency, not the 'neighbourhood'.
The results are satisfactory, as the new layout resembles the one in Fig. 1.1. Nevertheless, there are some differences. First of all the assumed layout doesn't follow the same distribution, as the real-life letters. Second of all certain letters, even with lower relative frequency, may be favoured over those with higher frequency, because they can have high co-occurrence with another letter - see 'r' and 'e' in the optimized layout (Fig. 3.1.).
The below illustration was based on 3 books that weren't used to produce results.
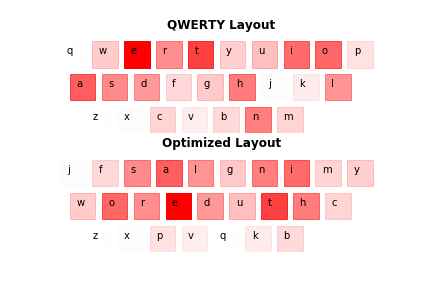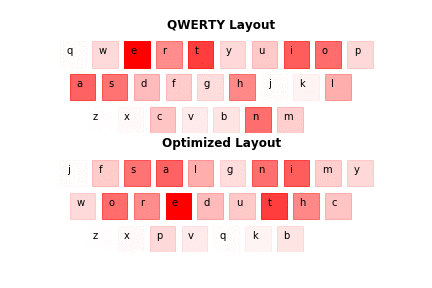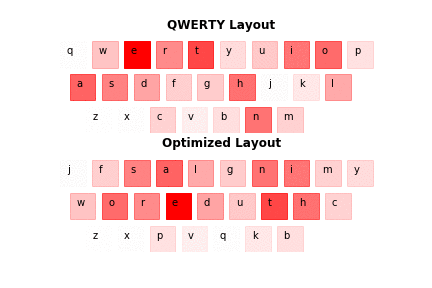
Fig. 3.1. Layout comparison.
As it is in the case of Fig. 1.1. darker keys reflect higher relative frequency in a text corpus.