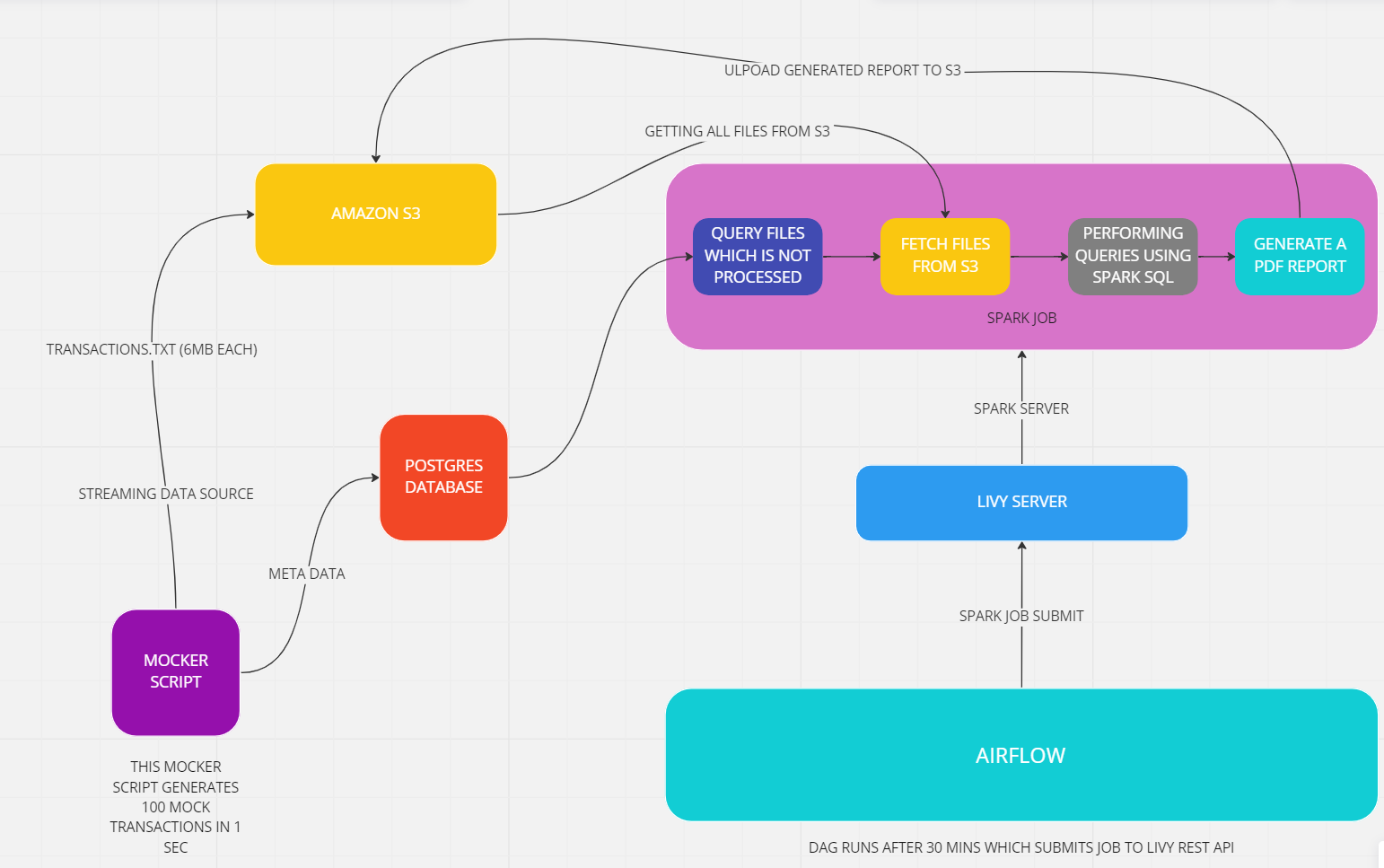
- There is a mocker script which is generating random 100 transactions every second . This transactions will be stored temporarily in assets/temp folder. after every 1 seccond file will be opened in append mode after adding the transaction size of file is checked if size of files 6mb then this file will be uploaded in s3 and meta data of that file like file name and boolean 'is_processed=false' is added to postgres db.
- Parallelly airflow is running which will schedule a dag after every 30 minutes.The task of dag is to submit the spark job using livy rest api.
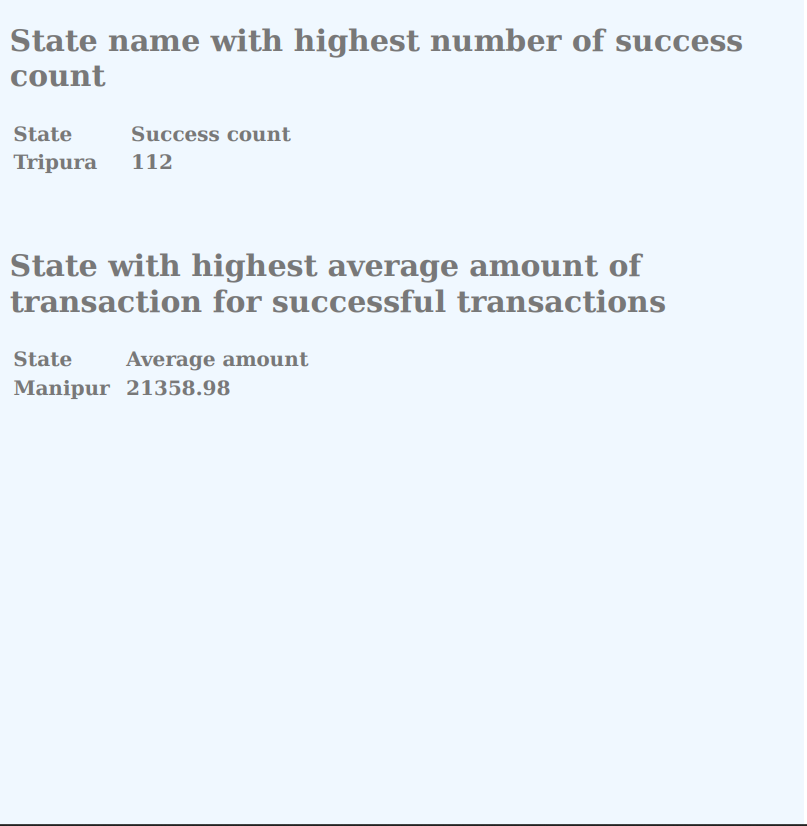
- After dag submit the spark job files will get loaded from hdfs like *.egg and some dependencies. First that job query a table from postgres named file_audit_entity and query the all files which is not processed yet. this include name of file_name .Then this file_names is used to get all the files from s3.After getting all the file this files will get combined in one .txt file this file will loaded into a dataframe after converting into dataframe we will perform some queries .
- After performing queries writin this data into a pdf and uploading to back into s3 bucket. after uploading the pdf report updating the table attribute 'is_processed'=true
- Hadoop 2.9.x
- Spark 3.3.0
- Apache livy 0.7.1
- Docker
- This project used python 3.9.7 so we have to setup that first. there is script in scripts folder named as setup-python.bash run that script using bash script/setup-python.bash
- Create and activate the pyenv enviroment using pyenv virtualenv 3.9.7 [env_name]
- After we have install dependencies. using pip install -r requirements.txt --no-cache-dir
- Now we have setup the airflow so we have run airflow-setup script using bach scripts/airflow-setup.bash
-
create a .env file in root of project
and paste this
-
AWS_ACCESS_KEY_ID=[ur-access-key]
AWS_SECRET_KEY_ID=[ur-secrep-key]
AWS_REGION=[ur-region]
DEV_BUCKET_NAME=[ur-s3-bucket-name]
HOST=[UR-HOST]
USERNAME=[UR-USERNAME]
PASSWORD=[UR-PASSWORD]
DATABASE=[UR-DATABASE]
PORT=[UR-PORT]
FILE_SIZE=6664093
-
start all services
- $HADOOP_HOME/start-all.sh
- $SPARK_HOME/start-all.sh
- $LIVY_HOME/bin/livy-server
- start airflow using bash scripts/start-airflow.sh
- run a postgres image in docker
- run mock_stream_gpay_transaction_data_producer.py file
- go to airflow and start the spark-job-submit dag