Replies: 2 comments
-
It is probably because embeddings work between clip and the diffuser. It's most likely dealing with small values to give big results and the way the loss returns is most likely not entirely appropriate. I assume there is a lot of horizontal drift with the values after a while. I suggested implementing TensorBoard to investigate this further. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you~ Greatly inspired me |
Beta Was this translation helpful? Give feedback.
-
The largest mystery I have encountered when training my Textual Inversion embeddings/Hypernetworks is that although there are no obvious trends in the training loss curve, the images produced are no doubt fitting the training dataset better. That makes loss not a useful metric for evaluating the success of training session.
Is the loss actually decreasing but just hidden by the inherent noise? Or is there some more robust metric we can use by considering more variables? If we can solve these problems, we can more efficiently find training hyperparameters and HN architectures instead of relying on folklore.
What does the loss mean?
The loss as defined in Eq. 3 of the LDM paper is
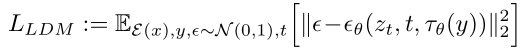
The losses used in TIs/HNs are variants of this. In plain English, that's the expected value of the squared error of the noise predicted by the denoiser. This is the number we are trying to minimize in the training process.
There's a problem though: the loss can only be estimated, and the sample space is huge. Even if we restrict the dataset size to be small, we still have to pick a random timestep$t \in [0, 999]$ (which decides the noise level) and a random latent noise $\epsilon$ .
In the WebUI, the loss reported is the average of the last 32 steps. This number alone is not too meaningful, as the underlying distribution has high variance.
My setup
For training:
[filewords] [name][filewords]every epochFor evaluation:
Overall loss
Perhaps unsurprisingly, the loss highly related to the noise level. Sudden bumps in the loss curve when training might just be unlucky streaks of low timesteps.
Some statistics:
Per-image loss
With the dataset entry fixed, the loss forms unexpectedly nice smooth curves over timesteps. It is also clear that some images are learned better than others.
Effect of trained steps
Now this is the weird part. Despite collecting so many samples, no obvious decrease of the loss is observed over trained steps. The difference of the mean of the losses is in the order of the standard error.
Conclusion
Honestly, I don't really know. I was expecting to see some tiny but measurable decrease of loss, but there doesn't seem to be any. Hopefully someone can be inspired by my crude exploration and find better metrics and develop a quantitative approach to training.
Beta Was this translation helpful? Give feedback.
All reactions