Windows :
pip3 install gym
pip3 install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
pip3 install gym-retro(may requires certain access rights) Linux :
pip3 install gym
pip3 install -e 'gym[atari]'
pip3 install gym-retroThen go in the folder 'Roms' and :
python3 -m retro.import .Launch the code :
python main.py training render get_saved_model simple_dqn
The parameters are booleans. 1 for True, 0 for False
- training: True for training False for directly test
- render: True for displying the environment while training
- get_saved_model: True for start train or test with a saved model (in models/saves) False for starting with a new model
- simple_dqn: True for using the DQN algorithm. False will use all the improvements we implemented (DDQN, Per Memory)
Example :
python main.py 1 0 0 1
We used a simple architecture : three convolutional layers + 2 parralel set of two fully connected layer, one computing V, the value of states, that is how much good it is to be in that state, one computing A(s,a), that represent how good it is to take action a in state s:
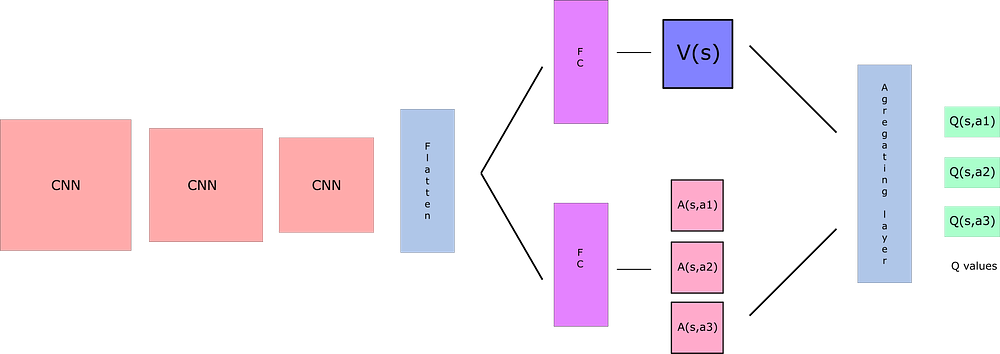
We take as input a modified version of the screen as pixels (we scrap some uninteresting part, we take it in black and white to reduce dimensions etc...)
This modification of the basic architecture 3 cn + 2 fc is called Dueling DQN. (DQN stands for Deep Q-Network)
In terms of learning, we learn by looking at memories that we sample from a pool. While training, we add every experience to that pool.
That allows to not unlearn things that you learned in the past if the environnement changes (like going in a new level in some video games) or in the present case being hidden behind a shield or not.

The sampling isn't done uniformly, we use an optimization called PER : we prioritize experiences that have a huge loss, because there is much more to learn from them. The sampling is still done at random of course. But since that introduces a bias (we may learn too much from certain samples, which might lead to overfitting) so we decrease the priority of experiences according to how much we did those.
We also deal with a bit more problems with Deep Q-learning is that the target we are trying to reach is moving at the same time we progress since it's supposedly computed with the network, so we use a trick called Q-fixed target that adds a network that computes the target but is updated less frequently than the 'main' network. We also use this second network to decouple the choice of action and evaluation of q-valued (dueling dqn).
--
Sources :