Go has lots of synchronization mechanisms ranging from language primitives such as mutexes, channels, atomic functions, and to a more complicated components such as context.Context. Unfortunately, using them to solve problems arising in day-to-day programming might be quite challenging, especially for novices.
The goal of the Job design pattern and this implementation is to provide an easy-to-use and solid foundation for solving problems involving concurrent executions and their control. The Job pattern in many cases can be viewed as an alternative to context.Context, though it's not meant to completely replace it.
I know, this is probably the most frequent question a skeptical programmer might ask. "Why should I learn how to use it,
when we already have context.Context, your solution looks like an over-engineered one".
Well, because I have a weakness for Gimp, allow me to retort in a sarcastic way to such criticism:
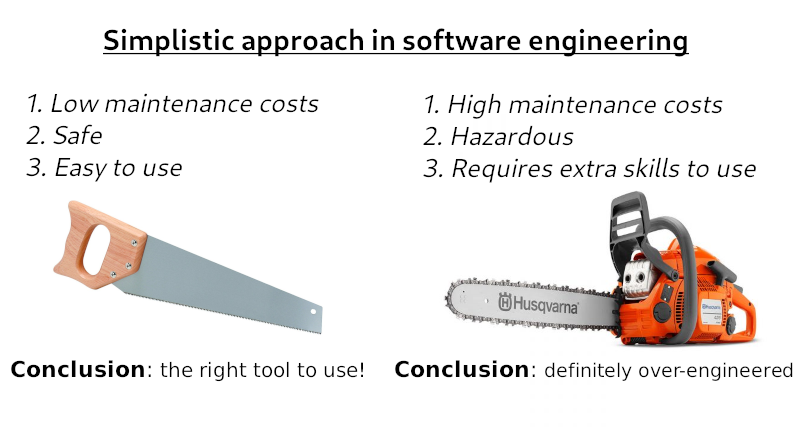
But seriously, simplicity in software engineering is often a reciprocal for productivity. Never underestimate the benefits
of going one abstraction level up.
A job is a set of concurrently running tasks, execution of which depends on each other. If one task fails, the whole job execution fails too.
myjob := job.NewJob(nil)
myjob.AddTask(task1)
myjob.AddTask(task2)
<-myjob.Run()
// Let's process the resultHere is a simple example: https://play.golang.org/p/vec2ybo3ti9. You can compare context.Context example with the same implementation using Job.
A single task consists of the three routines: an initialization routine, a recurrent routine, and a finalization routine:
func (stream *stream) ReadOnStreamTask(j job.Job) (job.Init, job.Run, job.Finalize) {
init := func(task job.Task){
// Do some initialization
}
run := func(task job.Task) {
read(stream, task)
task.Tick()
}
fin := func(task job.Task) {
readCancel(stream, task)
}
return init, run, fin
}The recurrent routine is running in an indefinite loop. It represents well-known for { select { } } statements in
Go. The recurrent routine calls three special methods:
- .Tick() - to proceed task execution.
- .Done() - to finish task execution (or .FinishJob() to finish job execution as well).
- .Idle() - to tell that a task has nothing to do, and as a result it might be finished by reaching the idle timeout.
Tasks can assert some conditions, replacing if err != nil { panic(err) } by a more terse way:
func (m *MyTask) MyTask(j job.Job) (job.Init, job.Run, job.Finalize) {
run := func(task *job.TaskInfo) {
_, err := os.Open("badfile")
task.Assert(err)
}
}Every failed assertion will result in the cancellation of job execution, and invocation of the finalization routines of all tasks of the job being cancelled.
There are two types of tasks: an ordinary task (or recurrent), and an oneshot task. The main purpose of a oneshot task is to start off execution of other recurrent tasks waiting for the oneshot to be finished. You probably heard of such an approach in software design as Design by contract. Here we have similar approach: in the example below recurrent tasks make an assumption that they will be running when a network connection is established and the goal of the oneshot task (mngr.ConnectTask) is to fulfill that precondition, providing reference to the connection in Job value.
mainJob := j.NewJob(nil)
mainJob.AddOneshotTask(mngr.ConnectTask)
mainJob.AddTask(netmanager.ReadTask)
mainJob.AddTask(netmanager.WriteTask)
mainJob.AddTask(imgResizer.ScanForImagesTask)
mainJob.AddTask(imgResizer.SaveResizedImageTask)
<-mainJob.Run()A job can have only one oneshot task.
For data sharing tasks should employ (although it's not an obligation) a ping/pong synchronization using two channels, where the first one is being used to receive data and the second one - to notify the sender that data processing is completed.
run := func(task job.Task) {
select {
case data := <- p.conn.Upstream().RecvRaw(): // Receive data from upstream server
p.conn.Downstream().Write() <- data // Write data to downstream server
p.conn.Downstream().WriteSync() // sync with downstream data receiver
p.conn.Upstream().RecvRawSync() // sync with upstream data sender
}
task.Tick()
}To prevent a task from being blocked for good, be sure to close all channels it's using in its finalization routine.
Now, when you have a basic understanding, let's put the given pattern to use and take a look at a real life example: the implementation of a reverse proxy working as layer 4 load balancer, a backend server resizing images, and a simple client that would scan a specified directory for images and send them through the proxy server for resizing. The code will speak for itself, so that you will quickly get the idea of how to use the given pattern.
- NewJob(value interface{}) *job - creates a new job with the given job value.
- RegisterDefaultLogger(logger Logger) - registers a fallback logger for all jobs.
- DefaultLogLevel int
- AddTask(job JobTask) *task - adds a new task to the job
- GetTaskByIndex(index int) *task - returns a task by the given index.
- AddOneshotTask(job JobTask) - adds an oneshot tasks to the job
- AddTaskWithIdleTimeout(job JobTask, timeout time.Duration) *task - adds a task with an idle timeout
- WithTimeout(duration time.Duration) - sets run timeout for the job.
- Run() chan struct{} - starts the execution of the tasks.
- RunInBackground() <-chan struct{} - runs job's tasks in background. An oneshot task is required. Receives a signal from the returned channel once the oneshot task is finished.
- Cancel(err interface{}) - cancels the job with the given error.
- Finish() - finishes the job.
- Log(level int) chan<- interface{} - writes a log record using fallback or job's logger.
- RegisterLogger(logger Logger) - registers a job logger.
- GetValue() interface{} - returns a job value.
- SetValue(v interface{}) - sets a job value.
- GetInterruptedBy() (*task, interface{}) - returns a task and an error that interrupted the job execution.
- GetState() JobState - returns the job state.
- TaskDoneNotify() <-chan *task - receives *task from the returned channel when a task is finished.
- JobDoneNotify() chan struct{}- receives a signal from the returned channel when the job is finished
- GetIndex() int - returns task index. Oneshot tasks have predefined 0-index.
- GetJob() Job - returns a reference to the task's job.
- GetState() TaskState - returns task state.
- GetResult() interface{} - returns task result.
- SetResult(result interface{}) - sets task result.
- Tick()1 - proceeds task execution.
- Done()1 - marks task as finished and stops its execution.
- Idle()1 - do nothing. Being used for tasks having idle timeouts.
- FinishJob()
- Assert(err interface{}) - asserts that error has zero value.
- AssertTrue(cond bool, err string) - asserts that condition is evaluated to true, otherwise stops
- AssertNotNil(value interface{})
- Being called by the recurrent routine.