{kind=link}
Chess reinforcement learning by AlphaGo Zero methods.
This project is based on these main resources:
- DeepMind's Oct 19th publication: Mastering the Game of Go without Human Knowledge.
- The great Reversi development of the DeepMind ideas that @mokemokechicken did in his repo: https://github.com/mokemokechicken/reversi-alpha-zero
- DeepMind just released a new version of AlphaGo Zero (named now AlphaZero) where they master chess from scratch: https://arxiv.org/pdf/1712.01815.pdf. In fact, in chess AlphaZero outperformed Stockfish after just 4 hours (300k steps) Wow!
See the wiki for more details.
Note: This project is still under construction!!
- Python 3.6.3
- tensorflow-gpu: 1.3.0
- Keras: 2.0.8
Using supervised learning on about 10k games, I trained a model (7 residual blocks of 256 filters) to a guesstimate of 1200 elo with 1200 sims/move. One of the strengths of MCTS is it scales quite well with computing power.
Here you can see an example of a game I (white, ~2000 elo) played against the model in this repo (black):

I've done a supervised learning new pipeline step (to use those human games files "PGN" we can find in internet as play-data generator). This SL step was also used in the first and original version of AlphaGo and maybe chess is a some complex game that we have to pre-train first the policy model before starting the self-play process (i.e., maybe chess is too much complicated for a self training alone).
To use the new SL process is as simple as running in the beginning instead of the worker "self" the new worker "sl". Once the model converges enough with SL play-data we just stop the worker "sl" and start the worker "self" so the model will start improving now due to self-play data.
python src/chess_zero/run.py slIf you want to use this new SL step you will have to download big PGN files (chess files) and paste them into the data/play_data folder (FICS is a good source of data). You can also use the SCID program to filter by headers like player ELO, game result and more.
To avoid overfitting, I recommend using data sets of at least 3000 games and running at most 3-4 epochs.
This AlphaGo Zero implementation consists of three workers: self, opt and eval.
selfis Self-Play to generate training data by self-play using BestModel.optis Trainer to train model, and generate next-generation models.evalis Evaluator to evaluate whether the next-generation model is better than BestModel. If better, replace BestModel.
Now it's possible to train the model in a distributed way. The only thing needed is to use the new parameter:
--type distributed: use mini config for testing, (seesrc/chess_zero/configs/distributed.py)
So, in order to contribute to the distributed team you just need to run the three workers locally like this:
python src/chess_zero/run.py self --type distributed (or python src/chess_zero/run.py sl --type distributed)
python src/chess_zero/run.py opt --type distributed
python src/chess_zero/run.py eval --type distributeducilaunches the Universal Chess Interface, for use in a GUI.
To set up ChessZero with a GUI, point it to C0uci.bat (or rename to .sh).
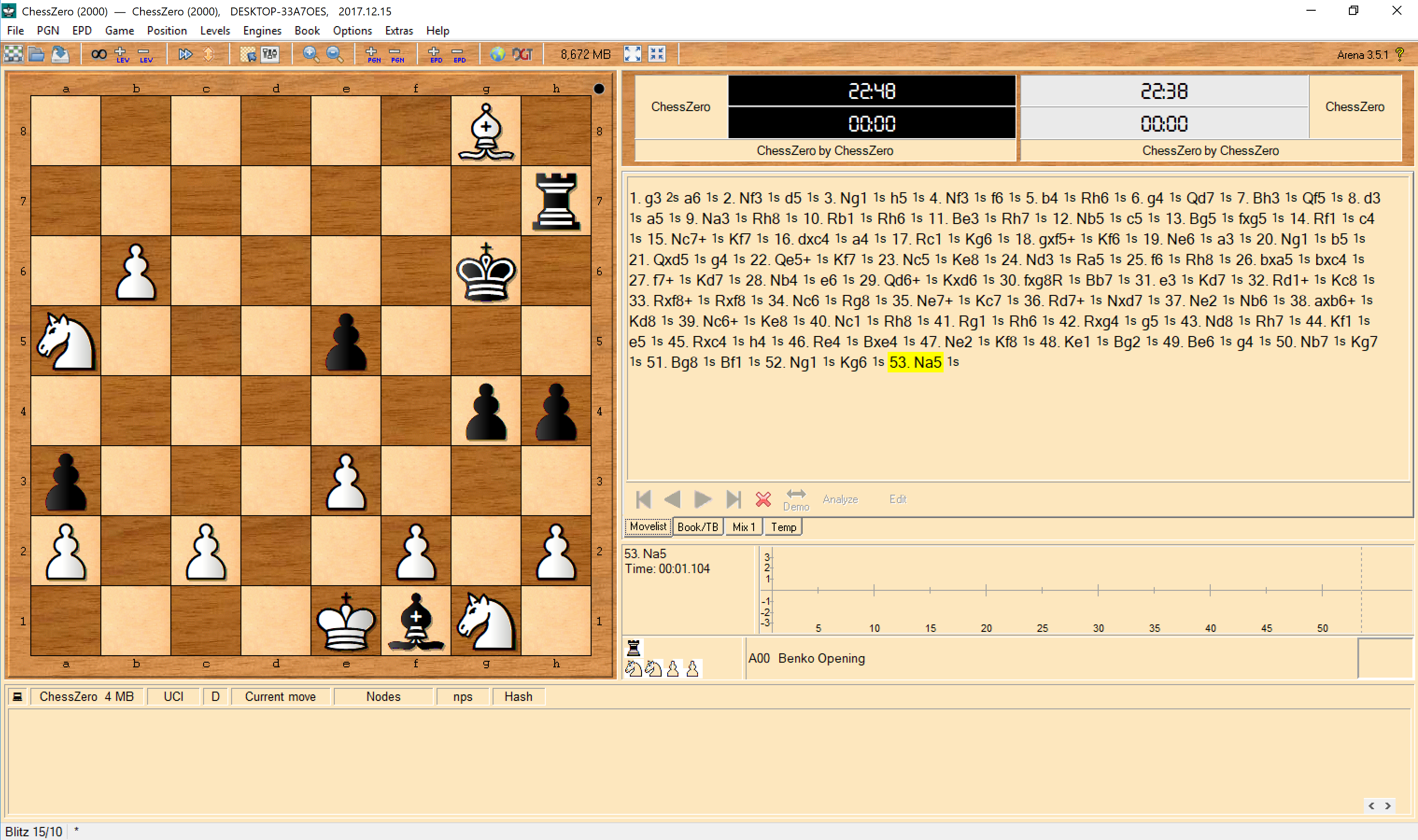
For example, this is screenshot of the random model using Arena's self-play feature:
data/model/model_best_*: BestModel.data/model/next_generation/*: next-generation models.data/play_data/play_*.json: generated training data.logs/main.log: log file.
If you want to train the model from the beginning, delete the above directories.
pip install -r requirements.txtIf you want to use GPU,
pip install tensorflow-gpuMake sure Keras is using Tensorflow and you have Python 3.6.3+.
For training model, execute Self-Play, Trainer and Evaluator.
python src/chess_zero/run.py selfWhen executed, Self-Play will start using BestModel. If the BestModel does not exist, new random model will be created and become BestModel.
--new: create new BestModel--type mini: use mini config for testing, (seesrc/chess_zero/configs/mini.py)
python src/chess_zero/run.py optWhen executed, Training will start. A base model will be loaded from latest saved next-generation model. If not existed, BestModel is used. Trained model will be saved every epoch.
--type mini: use mini config for testing, (seesrc/chess_zero/configs/mini.py)--total-step: specify total step(mini-batch) numbers. The total step affects learning rate of training.
python src/chess_zero/run.py evalWhen executed, Evaluation will start. It evaluates BestModel and the latest next-generation model by playing about 200 games. If next-generation model wins, it becomes BestModel.
--type mini: use mini config for testing, (seesrc/chess_zero/configs/mini.py)
Usually the lack of memory cause warnings, not error.
If error happens, try to change vram_frac in src/configs/mini.py,
self.vram_frac = 1.0Smaller batch_size will reduce memory usage of opt.
Try to change TrainerConfig#batch_size in MiniConfig.