Dynamic Key-Value Memory Networks for Knowledge Tracing, Yeung+, WWW'17 #352
Comments
|
DeepなKnowledge Tracingの代表的なモデルの一つ。KT研究において、DKTと並んでbaseline等で比較されることが多い。 |
|
DKVMNと呼ばれることが多く、Knowledge Trackingができることが特徴。 |
|
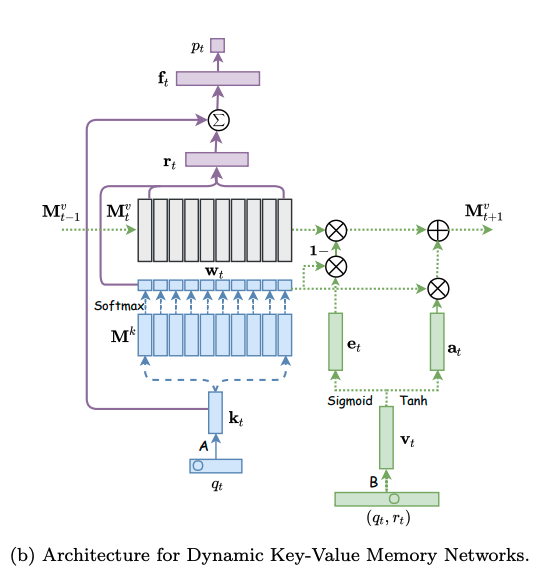
モデルは下図の左側と右側に分かれる。左側はエクササイズqtに対する生徒のパフォーマンスptを求めるネットワークであり、右側はエクササイズqtに対する正誤情報rtが与えられた時に、メモリのvalueを更新するネットワークである。
メモリとは生徒のknowledge stateを保持している行列であり、keyとvalueのペアによって形成される。keyとvalueは両者共にdv次元のベクトルで表現される。keyはコンセプトを表し、valueがそれぞれのコンセプトに対する生徒のknowledge stateを表している。ここで、コンセプトとスキルタグは異なる概念であり、スキルタグを生成される元となった概念のことをコンセプトと呼んでいる。コンセプトは基本的には専門家がタグ付しない限り、観測できない変数だと思われる。すなわち、コンセプトとはsynthetic-5データでいうところのc_t(5種類のコンセプト)に該当し、個々のコンセプトによって生成された50種類のexerciseがエクササイズタグに相当する。ASSISTments15データでいうところの、100種類のスキルタグがエクササイズタグで、それぞれのスキルタグのコンセプトはデータに明示されていない。 ptの求め方ptを求める際には、エクササイズqt(qtのサイズはエクササイズタグ次元Q; エクササイズタグが何を指すかは分かりづらく、基本的にはスキルタグのことだが、synthetic-5のように50種類のquestion_idをそのまま利用することも可)のembedding kt(dk次元)を求め、ktをメモリのkey M^k(N x dk次元)とのmatmulをとることによって、各コンセプトとのcorrelation weight w を求める。 read contentベクトルrは、各キーのcorrelation weight w(scalar)とメモリのvalueベクトル(dv次元)との積をメモリサイズ(コンセプト数)Nでsummationすることによって求められる。 read contentベクトルを求めたのち、生徒のqtに対するmastery levelと取り組む問題qtの難易度を集約したサマリベクトルftをfully connected layerによって求める。求める際には、rとkt(qtのembedding)をconcatし、fully connected layerにかける。 最終的にサマリベクトルftを異なるfully connected layerにかけることによって、エクササイズqtに対するレスポンスを予測する。 メモリの更新方法エクササイズqtとそれに対する正誤rtが与えられたとき(qt, rt)、この情報のembedding vtを求める。求める際は、2Q x dv次元のembedding matrixをlookupする。このvtは、生徒がエクササイズに回答したことによってどれだけのknowledge growthを得たかを表している。 その後、knowledge growth vt から、新たなtransformation matrix D(dv x dv)を用いて、adding vector aが計算される。 最終的に、メモリの各valueは、adding vectorに対してcorrelation weightの重み分だけ各elementの値が更新される。 このような erase-followed-by-addな構造により、生徒の忘却と学習のlearning processを再現している。 予測性能DKVMNが全てのデータセットにおいて性能が良かった。が、これは後のさまざまな研究の追試によりDKTとDKVMNの性能はcomparableであることが検証されているため、あまりこの結果は信用できない。 learning curveDKTとDKVMNの両者についてlearning curveを描いた結果が下記。DKTはtrainingとvalidationのlossの差が非常に大きくoverfittingしていることがわかるが、DKVMNはそのような挙動はなく、overfittingしにくいことを言及している。
Concept DiscoveryFigure4がsynthetic-5に対するConcept Discovery, Figure5がASSISTments15に対するConcept Discoveryの結果。synthetic-5は5種類のコンセプトによって50種類のエクササイズが生成されているが、メモリサイズNを5にすることによって完璧な各エクササイズのクラスタリングが実施できた(驚くべきことに、N=50でも5つのクラスタにきっちり分けることができた)。ASSISTments15データについても、類似したコンセプトのスキルタグが同じクラスタに属し、近い距離にマッピングされているため、コンセプトを見つけられたと主張している。
Knowledge State DepictionSynthetic-5に対する、各コンセプトのmasteryを可視化した結果が下図。 個々のコンセプトのmasteryを可視化する手順は下記の通り。 所感スキルタグの背後にある隠れたコンセプトを見つけ、その隠れたコンセプトに対する習熟度を測るという点においてはDKTよりもDKVMNの方が優れていそう。 追記:DKVMNのDKTと比較して良い点は、メモリネットワーク上にknowledge stateが保存されていて、inputはある一回の問題に対するtrialの正誤のみという点。DKTなどでは入力する系列の長さの上限が決まってしまうが、原理上はDKVMNは扱える系列の長さに制限がないことになる。この性質は非常に有用。 |
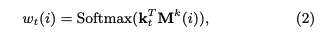
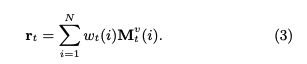


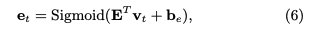
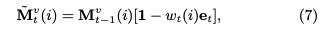






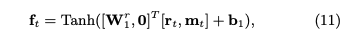
https://dl.acm.org/doi/pdf/10.1145/3038912.3052580
The text was updated successfully, but these errors were encountered: