独立な学習者・項目ネットワークをもつ Deep-IRT, 堤+, 電子情報通信学会論文誌, 2021 #459
Comments
モチベーションDeep-IRTで推定される能力値は項目の特性に依存しており、同一スキル内の全ての項目が等質であると仮定しているため、異なる困難度を持つ項目からの能力推定値を求められない。このため、能力パラメータや困難度パラメータの解釈性は、従来のIRTと比較して制約がある。一方、木下らが提案したItem Deep Response Theoryでは、項目特性に依存せずに学習者の能力値を推定でき、推定値の信頼性と反応予測精度が高いことが示されているが、能力の時系列変化を考慮していないため、学習家庭での能力変化を表現できない。これらを解決するための手法を提案。 手法論文中の数式に次元数が一切書かれておらず、論文だけを読んで再現できる気がしない。
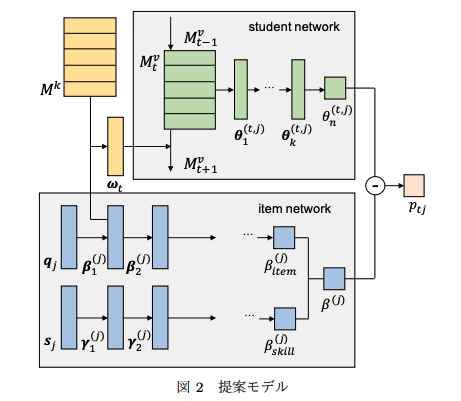
基本的に、生徒の能力値を推定するstudent networkと、スキル/項目の難易度を推定するitem networkに分かれている。ある時刻tでの生徒の能力値はメモリM上の全てのhidden conceptに対するvalueを足し合わせ、足し合わせて得られたベクトルに対してMLPをかけることによって計算している。 item networkも同様に、スキルタグのembedding q_j と 項目のembedding s_j を別々にMLPにかけて、最終的に1次元に写像することで、スキル/項目の難易度パラメータを推論していると思われる。 最終的に下記item response functionによって反応予測を行う。 また、メモリネットワークのmemory valueの更新は #352 と同じ方法である。 予測性能評価
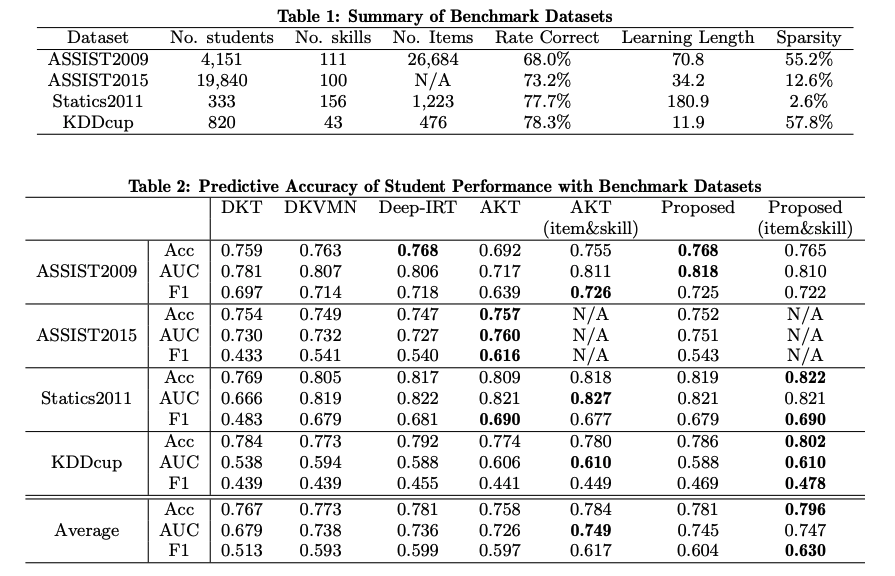
提案手法が全てのデータセットで平均すると最も良い予測性能を示している。IRTもKDDCupデータでは性能が良く、KDDCupデータは回答ログの正答率が非常に高くデータに偏りがあり、加えてデータのスパース率(10 人以下 ちなみにEDM'21論文だと下記のような結果になっている: こちらの結果を見ると、AKTよりも高い性能を示していることがわかる。AKTに勝つのは結構すごそうなのだが #456 でのAKTの性能に比べ、DKT等の手法に対するAKTの性能の伸びが小さいのが非常に気になる。何を信じたら良いのか分からない・・・。 解釈性評価実験についてDeepIRTとのパラメータの能力パラメータ、困難度パラメータの解釈性の検証をしているようだが、所感に書いてある通りまずDeepIRTの能力値パラメータを正しく採用できているのかが怪しい。困難度パラメータについては、シミュレーションデータを用いて提案手法がDeepIRTと比べて真の困難度に対する相関が高いことを示しているが、詳細が書かれておらずよくわからない・・・。一応IRTと同等の解釈性能を持つと主張している。 所感解釈性の評価実験において下記の記述があるが、
ここでどのような操作をしているのかがいまいち分からないが、時刻tのメモリM_tが与えられたとき、DeepIRTは入力ベクトルq_tに対応する一次元の能力値を返すモデルのはずで、q_tを測定したい能力のスキルタグに対するone-hot encodingにすれば能力値推移は再現できるのでは?「θ (t,j) 3を多次元で出力した値」というのは、1次元のスカラー値を出力するのではなく、多次元のベクトルとしてθ (t,j) 3を出力し、ベクトルの各要素をスキルに対する能力値とみなしているのだろうか。もしそういう操作をしているのだとしたらDeepIRTが出力する能力値パラメータとの比較になっていないと思う。 θ_n^(t, j)を学習者の能力値ベクトルとしてみなすと論文中に記述されているが、実際にどの次元がどのスキルの習熟度に対応しているかは人間が回答ログに対する習熟度の推移を観察して決定しなければならない。これは非常にダルい。 |
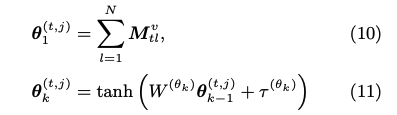
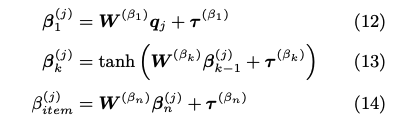
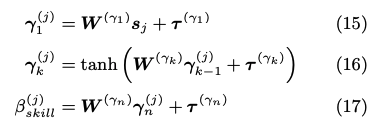
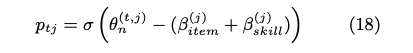
http://www.ai.lab.uec.ac.jp/wp-content/uploads/2021/06/2020JDP7061.pdf
https://files.eric.ed.gov/fulltext/ED615529.pdf
The text was updated successfully, but these errors were encountered: