Lessons Schedule is a project that can be used to calculate the expected release date of all lessons grades at Electrical and Computer Engineering department of National Technical Univercity of Athens. This Project contains implementation of Web Scraping, Probabilities and Randomized Algorithms.
I collected my data from the official forum of my department SHMMY using a well known lib BeautifulSoup4 using the following code.
#Track Information From "shmmy.ntua.gr"
Release_dates_of_posts = []
Content_of_Posts = []
def Track_shmmy_Data (page_id, no_of_pages):
global Release_dates_of_posts
global Content_of_Posts
headers = {"User-Agent": 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.2 Safari/605.1.15' }
next_page = 0
while (next_page <= no_of_pages):
URL = 'https://shmmy.ntua.gr/forum/viewtopic.php?f=290&t='+ page_id + '&start=' + str(next_page)
page = requests.get(URL, headers = headers)
soup = BeautifulSoup(page.content, 'html.parser')
date = soup.findAll( "p", {"class": "author"})
for author in date:
Release_dates_of_posts.append(author.text)
post = soup.findAll ( "div", {"class" : "content"})
for content in post:
Content_of_Posts.append(content.text)
next_page += 20I also extracted dates of release grades using regular expressions
#Function return dates
Months = ['ιαν', 'φεβ', 'μαρ', 'απρ', 'μαιος', 'ιουν', 'ιουλ', 'αυγ', 'σεπ', 'οκτ','νοεμ', 'δεκ']
def Aux_Define_Dates (word):
global Months
return (word in Months)
def Define_dates (list_of_words):
global Months
only_month = list(filter(Aux_Define_Dates, list_of_words))
day = int(re.sub("[^0-9]", "", list_of_words[list_of_words.index(only_month[0]) + 1]))
month = int(Months.index(only_month[0]) + 1)
year = int(re.sub("[^0-9]", "", list_of_words[list_of_words.index(only_month[0]) + 2]))
return [day, month, year]
Which creates a list with all post contents and a list with all the released dates of posts.
In order to collect the data from pdfs I converted them into excel files using a web service and then I used the lib xlrd to process data. The following code describes the module.
#Read and Extract from Excel
Excel_Cell_Values = []
def Extract_From_Excel (folder):
book = xlrd.open_workbook("/Users/alexandroskyriakakis/MyProjects/Python_Projects/Project_One/EXAMS SCHEDULE/" + folder + "/excel/Read_Info.xlsx")
global Excel_Cell_Values
for book_sheet_i in range(book.nsheets):
current_sheet = book.sheet_by_index(book_sheet_i)
for row_j in range(current_sheet.nrows):
for column_k in range(current_sheet.ncols):
current_cell = current_sheet.cell(row_j,column_k)
if (current_cell.value != '' and type(current_cell.value) is str):
Excel_Cell_Values.insert(len(Excel_Cell_Values),current_cell.value)
A bit challenging was the recognition of dates of exams but I used regex's once more.
#Tracking the dates on excel ----day/month/year----
Excel_lessons_date_of_exam = []
def Track_Dates_in_posts (list_of_strings):
current_date_of_exam = [0,0,0]
for cell_i in list_of_strings:
# print (cell_i,type(cell_i))
a = re.search("\d\d/\d\d/\d\d\d\d", cell_i)
if (a == None): Excel_lessons_date_of_exam.append(current_date_of_exam)
else:
current_date_of_exam = a.group().split('/')
current_date_of_exam = list(map(int, current_date_of_exam))
Excel_lessons_date_of_exam.append(current_date_of_exam)
Firstly I normalized everything removing accents meaningless words and make everything lower case letters.
#Function to keep only letters
def Keep_only_letters (list_of_words):
only_letters_list = []
for word_i in list_of_words:
word_i.replace("-"," ")
word_i.replace("\n"," ")
word_i.replace("\b"," ")
current_word = ''.join(filter(str.isalpha, word_i))
if (current_word == ''): list_of_words.remove(word_i)
else: only_letters_list.append(current_word)
return only_letters_list
#Function that removes accents (') in a given string
def remove_accents(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str)
return u"".join([c for c in nfkd_form if not unicodedata.combining(c)])
#Remove some meaningless words
Meaningless_Words = ['εξαμηνο','για','ηλ', 'αμφ', 'αιθ','και','η','το','τα','ο','οι','&','\n','της','των','απο','στα','στο','στη','επι', 'πτυχιο', 'πτυχιω', 'θεματα', 'με','την']
def Remove_Meaningless_Words (words):
global Meaningless_Words
return list(w for w in words if w not in Meaningless_Words)
def Remove_words_greater_than_six (Input_list_of_words):
Output_list_of_words = []
index = 0
while (index < len(Input_list_of_words) and index < 8):
Output_list_of_words.append(Input_list_of_words[index])
index += 1
return Output_list_of_words
#Do the changes, input string return list
def Normalize (Input_String):
a = (remove_accents(Input_String.lower())).split() #Lowercase, remove accents, make list of words
a = Remove_Meaningless_Words (a)
return aFinaly, I matched the values using an O(n^3) algorithm. At first I parse all the excel contents through all the post contents. For every common word I catch the number of common letters and then I sort the matched list based on the cardinality of common letters. Then I consider that the match with the most common letters is valid, and I remove the values from both lists. In the end I repeat this idea n times until all values get a match.
#For a lesson search a post for common words and returns the number of letters in common words
def Max_common_letters_in_words (lesson, posts_content):
max_sentence_size = 0
for lesson_word_i in lesson:
max_word_size = 0
for post_word_j in posts_content:
if (lesson_word_i == post_word_j):
length_of_common_letters = len(lesson_word_i)
if (length_of_common_letters > max_word_size): max_word_size = length_of_common_letters
max_sentence_size += max_word_size
return max_sentence_size
#For each one of excel cells we put in the list the post with the most common letters with the cell
CommonLetters_Post_CellValue_Date = []
def Create_List_with_all_data(Content_of_Posts_copy):
for Excel_value_j in Excel_Cell_Values:
max_common_letter_post = 0
for Post_i in Content_of_Posts:
a = Max_common_letters_in_words (Excel_value_j,Post_i)
if (max_common_letter_post <= a):
max_common_letter_post = a
if (a != 0):
exam_date = Excel_lessons_date_of_exam[Excel_Cell_Values_Copy.index(Excel_value_j)]
grades_release_date = Release_dates_of_posts[Content_of_Posts_copy.index(Post_i)]
CommonLetters_Post_CellValue_Date.append([a , Post_i , Excel_value_j, exam_date, grades_release_date])
def Repeat_Idea ():
global CommonLetters_Post_CellValue_Date
Repeated_list = []
while ((Excel_Cell_Values != [] and Content_of_Posts != []) ):
Create_List_with_all_data(Content_of_Posts_copy)
CommonLetters_Post_CellValue_Date.sort(key=itemgetter(0))
CommonLetters_Post_CellValue_Date.reverse()
if (CommonLetters_Post_CellValue_Date == []): break
current_max_value = CommonLetters_Post_CellValue_Date.pop(0)
#print (current_max_value)
if (current_max_value[2] in Excel_Cell_Values):
Excel_Cell_Values.remove(current_max_value[2])
if ((current_max_value[1] in Content_of_Posts)):
Content_of_Posts.remove(current_max_value[1])
Repeated_list.append(current_max_value)
CommonLetters_Post_CellValue_Date = []
CommonLetters_Post_CellValue_Date = Repeated_list
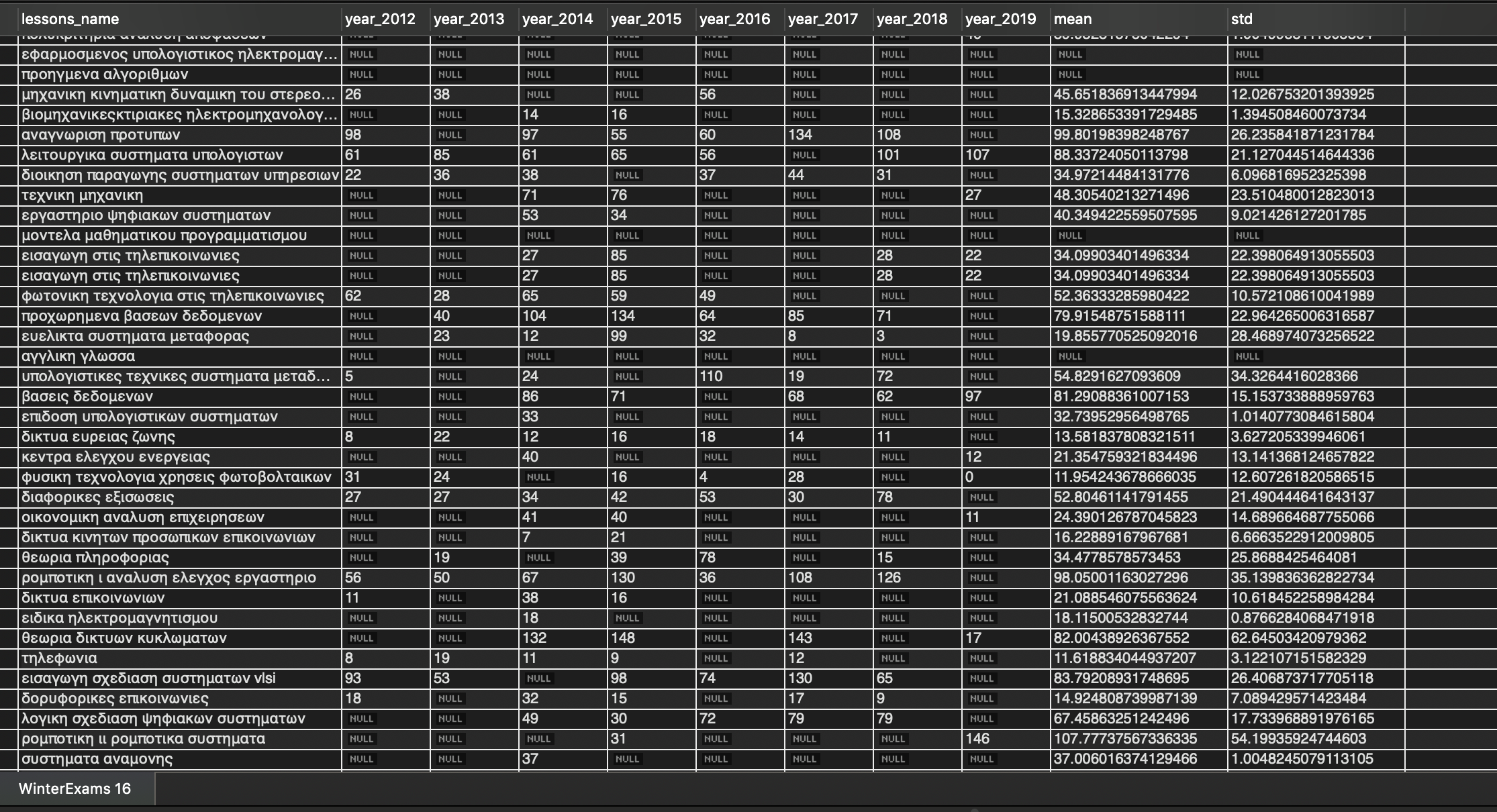
Then we created and upload data to data base with project2.py which looked like this
In order to have more realistic mean results I applied the Harmonic Series to the result as frequency of the values starting from the latest. So the latest the most participating weight on the mean.
#Apply Harmonic Series to results
def Harmonic_Series (lista):
if (len(lista) == 0): return lista
if (len(lista) == 1): return np.random.normal(lista[0], 1, 100)
else:
Result_list = []
lcm = 0
freq_list = Aux_Series(lista) # [33,45,67] -> [3,2,1]
if (len(lista) == 2): lcm = 2
else: lcm = np.lcm.reduce(freq_list) # lcm = 6
for i in freq_list:
for j in np.random.normal(lista[freq_list.index(i)], 1, 100*(lcm//i)): #Randomize the result
Result_list.append(j) #6/3 = 2 -> [33,33,45,45,45,67,67,67,67,67,67]
return Result_list
def Aux_Series (lista):
result = []
for i in lista:
result.append(len(lista) - lista.index(i))
return resultThe naive way to do this is by adding n times the latest element and n/2 the second latest etc.
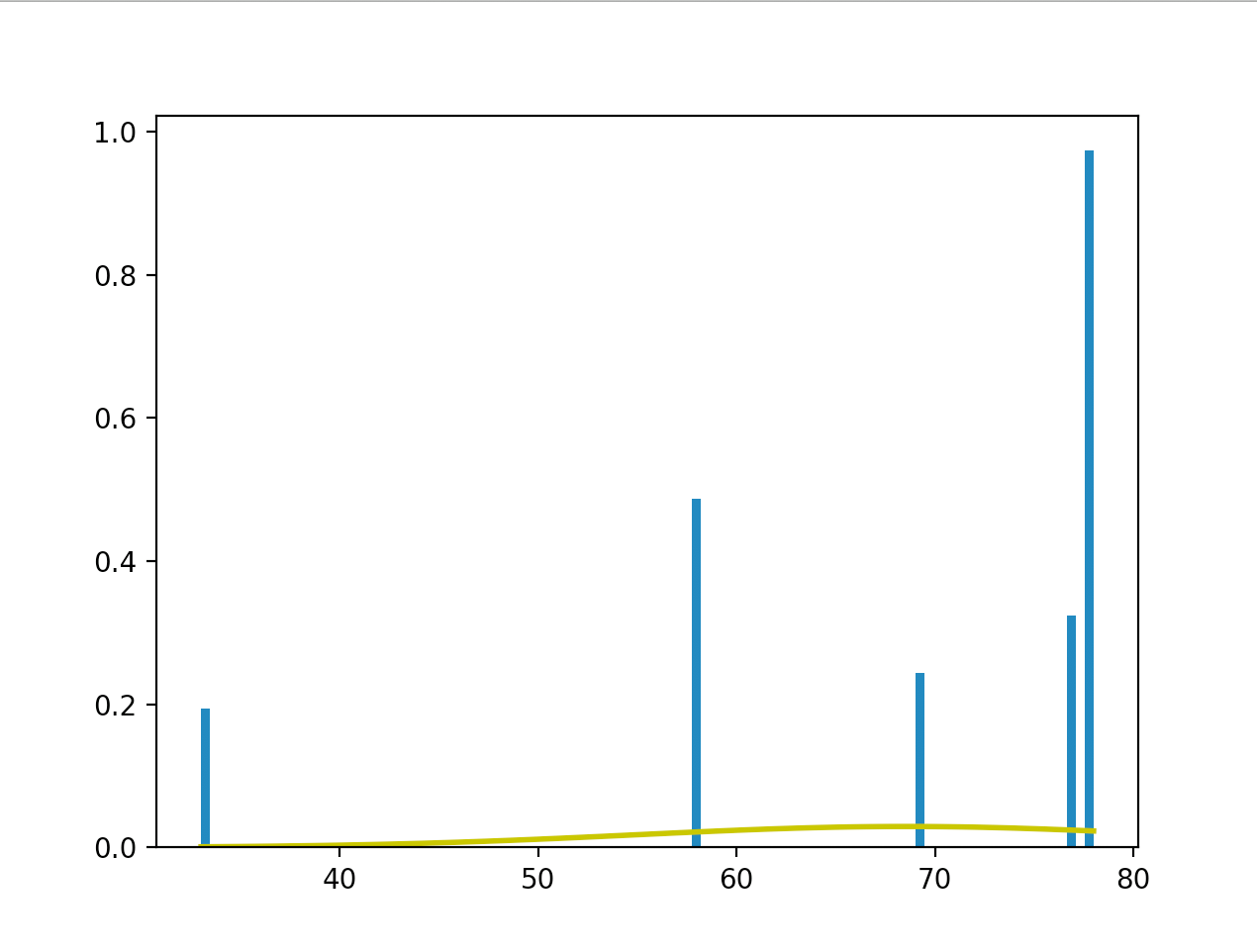
But instead I took the values taking a normal random variable with mean on the current value for n times.
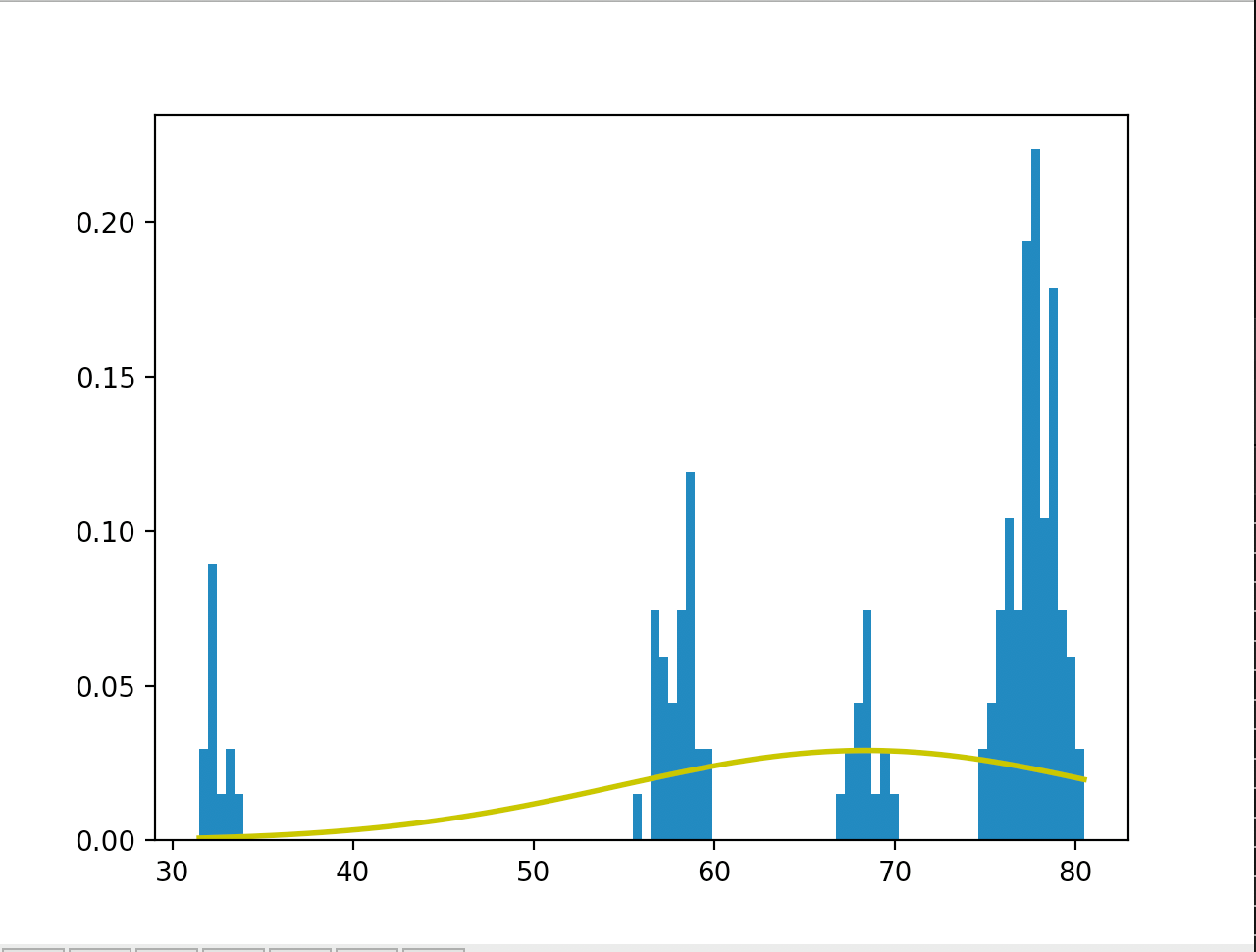
So following these steps I calculated the Mean Values and the STD's.
As for the web page, I used the code from a react exaple on git and I changed the content using test32.py and deploy it using git pages. Every day after the Expected date of release the Probability of Grade's Release is growing above 50%.
Project's inner purpose was to get comfortable with python and it's libraries, trying web scrapping and make something usefull for my impatient classmates...
Have Fun!