add min_area and pj_crop #3435
add min_area and pj_crop #3435
Conversation
|
@alemelis Hi, Thanks!
|
|
I added param So you can test your additional suggestions scale_min = 0.25 and if you get higher mAP in some cases by using new parameters, then I will be happy to merge your pool request. |
|
@AlexeyAB these are the 6 training logs two things to notice:
The best mAP during training is shown below |


warning: format specifies type 'long' but the argument has type 'uint64_t'
|
this is to reply to your questions above
I also fixed few compilation warnings |
|
@alemelis Thank you very much! Yes, I think scale_min and scale_max are good feature. Yes, I see that pjcrop=2 without minarea, and minarea with pjcrop=0/1 gives some improvements. |
| @@ -380,7 +382,7 @@ void fill_truth_detection(const char *path, int num_boxes, float *truth, int cla | |||
| ++sub; | |||
| continue; | |||
| } | |||
| if ((w < lowest_w || h < lowest_h)) { | |||
| if ((w < lowest_w || h < lowest_h) || (area < min_area)) { | |||
There was a problem hiding this comment.
lowest_w and lowest_h are both calculated relative to the network size.
Interested in why you've used a constant (w.r.t. network size) float, rather than defining it as the (integer) area in input pixels.
There was a problem hiding this comment.
area is expressed in "yolo" units. Hence, this is independent from the network resolution and it is related to the image size
In my dataset, I mainly use 1920x1080px images, and a min_area=0.0001 will ignore all the annotations smaller than 14x14px. These are arguably useful for learning, but I can reintroduce them by changing min_area without touching the annotations.
There was a problem hiding this comment.
A bit more detail on my thinking..
There may be two reasons for ignoring these small annotations:
a) Because of human error annotating the data.
b) Because we assume there is not enough information to accurately detect an object with a bounding area of <min_area
if (a) is true, then more data should surely fix this (law of large numbers etc). If we really want to remove these then this a trivial quick data-cleanup operation on our training images prior to learning.
if (b) is the reason, then shouldn't this filter be applied after data augmentation, based on the amount of data available during training - rather than the amount of data in the input image?
There was a problem hiding this comment.
I agree that is trivial to fix case a) through some data cleaning, but I found that different architectures (v2, v3, tiny v3, etc...) at different resolutions may require a slightly different min_area threshold. I suspect this may indicate that the amount of information in a single annotation may be or not relevant depending on the net we want to train. Hence, I'd be worried of discarding a-priori some annotations only because a certain net couldn't learn anything from it.
This, in turn, links to b).
shouldn't this filter be applied after data augmentation, based on the amount of data available during training - rather than the amount of data in the input image?
Probably this would be viable in case of fixed augmentation, i.e., the images are scaled all the times in the same manner. This is not darkness case as I'm showing in the first comment to this PR.
I hope this make sense :)
What is this?
This PR brings back the data augmentation method implemented in pjreddie's repo.
Related to #3119
It also adds a new parameter,
min_area, to be used during training to filter out detectionsmin_area-.times smaller than the training image (net-work size). This helps with datasets ill-annotated in which too small objects are labelled even if no useful information can be retrieved.Why?
During training the image is randomly cropped and re-scaled to simulate a zoom-in/out effect. This process is different in pjreddie and AlexeyAB repos as these employ statistically different cropping behaviours (Figure 2a)
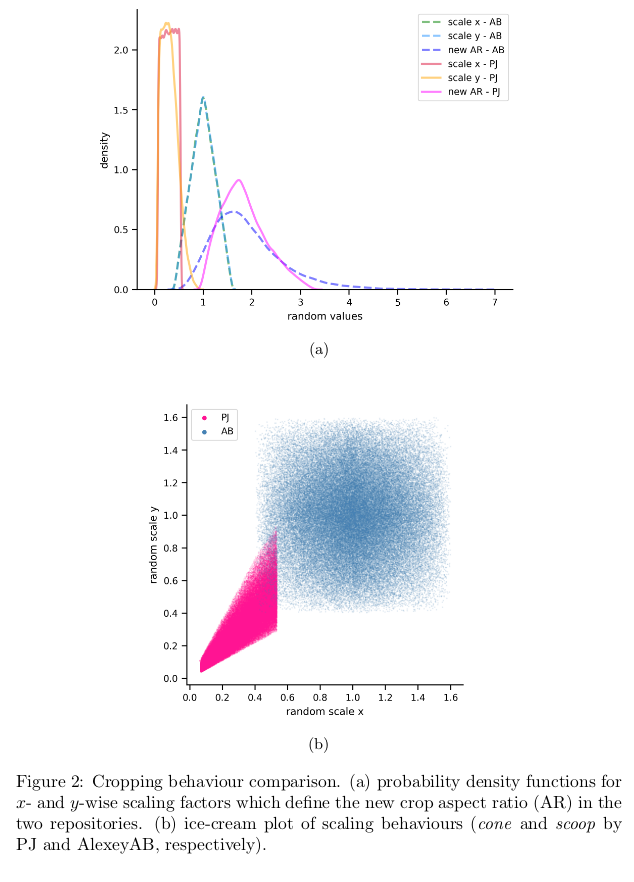
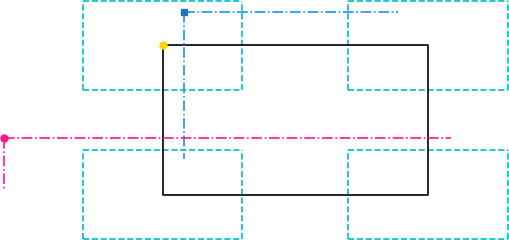
The resulting behaviour is depicted below (blue and pink for AB's and pjreddie's, respectively). AB's method ensure that the corners of the cropped image are always in the dashed regions so that the image centre is always cropped. This goes at the expense of allowing the image orientation to randomly go from landscape to portrait (squeeze effect). pjreddie's method instead allows harsher zoom-in/out while retaining the original orientation (also, the center of the image is not forced to be always in the crop)
How to use
The cropping behaviours are regulated by the following parameters
jitter(which is defined multiple times in the[yolo]layers) is used to identify two deltas (dwanddh) to be used to generate the random crop [6]. In the ice-cream plot, the jitter parameter identify the cone base diameter.scale_minandscale_max(used only in PJ's random cropping strategy) are used to define the random width range (the ice-cream cone length)This PR makes possible to use both cropping methods via
pj_cropswitch:0for AlexeyAB's method1for pjreddie's,2for random between the two on an image-by-image basisChange the .cfg file as in
yolov3-tiny_pjcrop.cfg(provided)