Erdős Institute Data Science Boot Camp, Fall 2023.
- View our 5-minute presentation
The recent advances in deep learning, neural networks, and the hardware to support it have provided fertile ground for creating fake images. This new technology, if left unchallenged, creates a risk in multiple areas, including journalism, law enforcement, and knowledge itself. In the words of the KPMG chair in organizational trust at the University of Queensland , Nicole Gillespie:
“How do we know what’s true or not true any more? That’s what’s at stake.”
We tackle this problem by constructing two multi-classification models (single-channel and dual-channel) to discern between images which are real, that is, not generated by AI, and those which are generated by AI, and to determine which generative algorithm was used. Our model is trained on a publicly available dataset [1] of ≈90000 images. This dataset contains real images as well as images generated by 13 different CNN-based generative algorithms.
Our precision and recall on validation sets for the dual-channel model are shown below:


Our models are a single-channel and dual-channel Convolutional Neural Networks.
Here the architecture of the single-channel CNN is outlined.
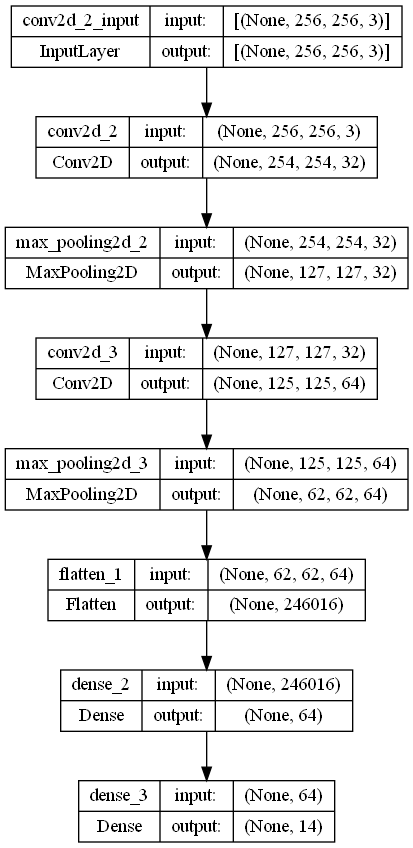
- Activation Function for Hidden Layers: ReLU
- Activation Function for Output Layer: Softmax
- Optimizer: Adam
- Loss Function: Categorical Cross-Entropy
- Filter Applied to Input: High Pass Filter Using Gaussian Blur (see below)
Here the architecture of the dual-channel CNN is outlined.
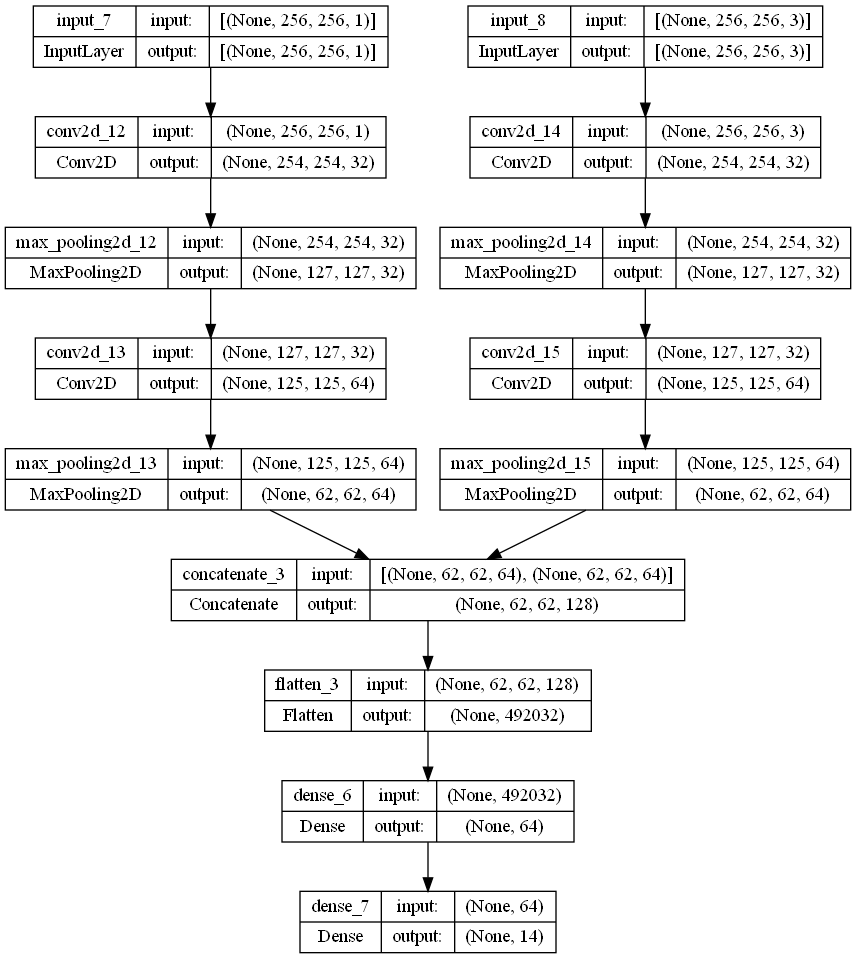
- Activation Function for Hidden Layers: ReLU
- Activation Function for Output Layer: Softmax
- Optimizer: Adam
- Loss Function: Categorical Cross-Entropy
- Filter Applied to Input: One copy of the image has a High Pass Filter while the other copy has a Log-Scale and Normalized Discrete Cosine Transform
Three filters were used in this project. The code for the filters is found in
Filters.py
We use a python script which discards images below a certain dimension as well as grayscale images. Furthermore, it saves the files into a new folder which contains the newly processed images, with filenames that include the necessary output material.
Since loading all the images into memory before training the neural network is not feasible, we create a custom Sequence element which reads the paths, and puts the images in memory on a "need-to-know" basis. In other words, on any given batch, only that batch is loaded into memory.
Since Keras does not natively support precision and recall metrics when more classes than two are involved, we write our own metrics.
We've written a web app that showcases our model.
Here is an example run.

-Krizhevsky, A., & Hinton, G. (2009). Learning multiple layers of features from tiny images.
-Bird, J.J., Lotfi, A. (2023). CIFAKE: Image Classification and Explainable Identification of AI-Generated Synthetic Images. arXiv preprint arXiv:2303.14126.