Reference:
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
Steps from 0 to 16 in transformer.ipynb(for data_small) & transformer_L.ipynb(for data_large: translation2019zh) are following:
-
1).data_small
baidudisk link: https://pan.baidu.com/s/1W16jPrdrP-uvzv4ZqYIvlw?pwd=n5ka code:n5ka
-
2).data_large
google drive link: https://drive.google.com/u/0/uc?id=1EX8eE5YWBxCaohBO8Fh4e2j3b9C2bTVQ&export=download
baidudisk link: https://pan.baidu.com/s/1KMHiroCl9wq8E4pRO_2oqw?pwd=6qts code:6qts
Above 3 X during the calculating Q, K, V will be same if SelfAttention else different.
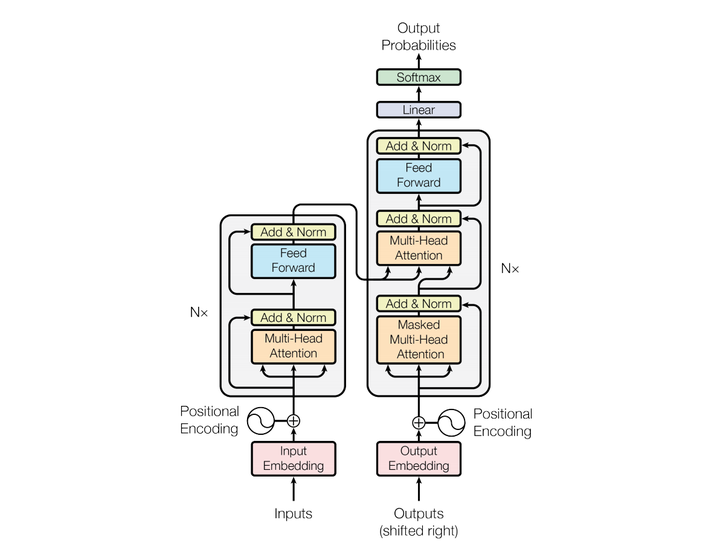
- 1).InputEmbedding + PositionalEncoding
- 2).MultiHeadSelfAttention
- 3).SublayerConnection + Norm
- 4).PositionwiseFeedForward
- 5).Repeat 3)
-
6).Repeat 2) ~ 5) * N
Let the output of previous 5) be the input of next 2), repeating N times.
- 1).InputEmbedding + PositionalEncoding
- 2).MultiHeadSelfAttention
- 3).SublayerConnection + Norm
- 4).MultiHeadContextAttention
- 5).Repeat 3)
- 6).PositionwiseFeedForward
- 7).Repeat 3)
-
8).Repeat 2) ~ 7) * N
Let the output of previous 7) be the input of next 2), repeating N times.
The lr increases linearly with a fixed warmup_steps, decreases proportional to the inverse square root of step_num when it reached warmup_steps(here is 4000).
The base optimizer is Adam with beta1=.9, beta2=.98, epsilon=1e-9.