Darknet_ros_FP16 Report (1.3x faster) 🔥
This page is a translation of this page into English. Please let me know if there are any mistakes.
Hello everyone.
In this article, I would like to report a light explanation of darknet_ros + ROS2 Foxy + cuDNN and its benchmark results.

If you're reading this article, you're probably already familiar with darknet_ros (or darknet).
Yes, it's the first program you think of when you want to do AI-based object detection with your robot! It is an open-source fast object detection program developed by Joseph Redmon, and it is unique in that it is written in C from the beginning without relying on TensorFlow or Caffe.
The impact of this paper and program was so great that its GitHub page has 20.9k stars and 17.4k forks.
Since then, its derivatives YOLO v4 (Alexey Bochkovskiy), YOLO R and Scaled-YOLO v4 (Kin-Yiu, Wong), and YOLO v5 (Glenn Jocher) have been developed and ported to various languages and libraries such as matlab and OpenCV. It has been ported to various languages and libraries such as matlab and OpenCV.
Let's run that fast object detection algorithm in ROS! Darknet_ros has been developed to run that fast object detection algorithm in ROS, and many articles have been written about it as a standard for ROS+object detection because of its good compatibility with embedded computers such as Jetson. This is a simple example.
This is a brief explanation of darknet and darknet_ros.
As mentioned above, darknet (YOLO v4) is a project led by Alexey Bochkovskiy, and has 16.5k stars as well as the original. The program has been upgraded to C++, and now supports OpenCV4 and cuDNN, making it very easy to use.
However, as of June 2021, darknet_ros is still forked from the original source, and YOLO v4 is still not available. (The developers hope to implement it eventually...)
https://github.com/leggedrobotics/darknet_ros/issues/243#issuecomment-816974717
This is a bit unavoidable.
The first darknet paper was published in 2015, and the library is quite old, so it may not work in the current default environment. (And Joseph Redmon's Darknet was discontinued in 2018...)
An example of how the problem is handled by the version: https://github.com/AlexeyAB/darknet/issues/932
Darknet_ros is also progressing with OpenCV4 and new ROS support, and new pull-links are still being thrown, but YOLO v4 support (i.e. AlexeyAB for submodules) requires very large changes.
By the way, there are a few sites and repositories that support YOLO v4 with ROS1 darknet_ros.
https://github.com/Tossy0423/yolov4-for-darknet_ros
https://www.programmersought.com/article/32007282885/
However, I really wanted darknet_ros to work with ROS2...
So I decided to run YOLO v4 with darknet_ros in late April, and implemented it around May.
https://twitter.com/Ray255Ar/status/1391335986412482564
I published a few articles about it, created a repository on GitHub and released PR, and announced the results on Twitter.
https://github.com/Ar-Ray-code/darknet_ros_fp16
https://qiita.com/Ar-Ray/items/cda557711bda87979ef5
https://ar-ray.hatenablog.com/entry/2021/06/02/180000
https://ar-ray.hatenablog.com/entry/2021/05/25/180000
Thankfully, we've received some reports of it working.
A month and a half after that, I'd like to report with results that we've achieved further speedup and the repository is now close to the speed of the original implementation in darknet_ros.
For speedup, we need to support cuDNN and FP16 (CUDNN_HALF) which is supported by AlexeyAB/darknet in darknet_ros side.
Let me explain a little about cuDNN and FP16 here.
In NVIDIA's CUDA library suite, there is a library called cuDNN that is specialized for deep learning. This is an external library that can further accelerate the dnn module that comes standard in CUDA.
It can be said that cuDNN partially overwrites the original CUDA library, because cuDNN is a library that optimizes deep learning modules that CUDA cannot support, and can be enabled by adding it to Makefile.
FP16 is one of the functions in cuDNN, and it is very strong. Normal CUDA operations deal with single precision floating point. This is almost the same factor as the float of the CPU that we usually use, and it can handle a wide range of numbers. However, since the input color originally has only 256 levels, there is not much point in taking values that wide. So, by using FP16 to halve the representation and precision, we can nearly double the number of operations with the same memory usage. This is said to increase the speed by 1.3 to 1.5 times.
From https://github.com/AlexeyAB/darknet#geforce-rtx-2080-ti
However, FP16 requires hardware support and requires some Volta GPUs and Turing and later GPUs. These GPUs commonly include Tensor Core, so it seems like it would not be out of line to make a selection based on this.
Usable GPUs (anything above cm_70)
- GeForce RTX series (including Laptop)
- Quadro RTX series
- Jetson Xavier (including NX?)
- TITAN V, NVIDIA TITAN RTX
- NVIDIA V100, T4, A-series
Here is a little explanation of the CMakeLists.txt file for cuDNN implementation. cuDNN took a lot of work to enable, so I hope that by showing excerpts, I can make the modifications easier to understand for those who need them.
↓ The GitHub repository of darknet_ros with cuDNN support is here
https://github.com/Ar-Ray-code/darknet_ros_FP16
When describing CMakeLists.txt, you need to do conditional branching with Find command and if command to support any environment.
Hints to find cuDNN are not given from the beginning, so you should use set(CMAKE_MODULE_PATH "${CMAKE_CURRENT_LIST_DIR}/. /darknet/cmake/Modules/" ${CMAKE_MODULE_PATH}), you need to refer to FindCUDNN.cmake in AlexeyAB/darknet. If you want to create an original package, you need to prepare it by yourself.
Then, when it is found, you can associate it with the condition.
#--- Abbreviation ---.
## For benchmarking
set(CUDA_ENABLE ON)
set(CUDNN_ENABLE ON)
set(FP16_ENABLE ON)
#--- abbreviation ---.
## FindCUDNN.cmake
set(CMAKE_MODULE_PATH "${CMAKE_CURRENT_LIST_DIR}/. /darknet/cmake/Modules/" ${CMAKE_MODULE_PATH})
if(CUDNN_ENABLE)
find_package(CUDNN) ## cuDNN search
message(STATUS "cuDNN Version: ${CUDNN_VERSION_STRINGS}")
message(STATUS "cuDNN Libararies: ${CUDNN_LIBRARIES}")
endif()
## If cuDNN is found
if(CUDNN_FOUND)
set(ADDITIONAL_CXX_FLAGS "${ADDITIONAL_CXX_FLAGS} -DCUDNN") # <- cuDNN enabled
endif()
#--- omit ---.
## When using cuDNN
if(CUDNN_FOUND)
## If we also use FP16 of cuDNN
if(ENABLE_CUDNN_HALF)
target_link_libraries(${PROJECT_NAME}_lib
cuda
cudart
cublas
curand
CuDNN::CuDNN ## <-- cuDNN enable
)
target_compile_definitions(${PROJECT_NAME}_lib PRIVATE
-DCUDNN ## <-- cuDNN enable
-DCUDNN_HALF ## <-- FP16 enabled
)
## If not using FP16 for cuDNN
else()
target_link_libraries(${PROJECT_NAME}_lib
cuda
cudart
cublas
curand
CuDNN::CuDNN ## <-- cuDNN enable
)
target_compile_definitions(${PROJECT_NAME}_lib PRIVATE
-DCUDNN ## <-- cuDNN enable
)
endif()
## If cuDNN is not used -- omit --.
endif()
```
### Determining CUDNN_HALF (FP16) by architecture
The most accurate way to enable CUDNN_HALF is to check your GPU and set it manually, but you may compile without noticing it at first, so I've written a shell in CMakeLists.txt that automatically plays out-of-target modules. We use the lspci command to display the GPUs of the target architecture, and if they are not displayed, the system will reject them. Therefore, GPUs such as Jetson AGX Xavier will be rejected by default. In that case, comment out `# set(CMAKE_CUDA_ARCHITECTURES 72)` on line 17.
````Makefile
execute_process (
COMMAND bash -c "lspci | grep NVIDIA | grep -e TU106 -e TU104 -e TU102 -e GA106 -e GA104 -e GA102"
OUTPUT_VARIABLE outVar
)
message ( STATUS " GPU (FP16): " ${outVar} )
if(outVar AND FP16_ENABLE)
set(CMAKE_CUDA_ARCHITECTURES 75)
endif()
if ( 70 IN_LIST CMAKE_CUDA_ARCHITECTURES OR
72 IN_LIST CMAKE_CUDA_ARCHITECTURES OR
75 IN_LIST CMAKE_CUDA_ARCHITECTURES OR
80 IN_LIST CMAKE_CUDA_ARCHITECTURES OR
86 IN_LIST CMAKE_CUDA_ARCHITECTURES)
set(ENABLE_CUDNN_HALF "TRUE" CACHE BOOL "Enable CUDNN Half precision" FORCE)
message(STATUS "Your setup supports half precision (CUDA_ARCHITECTURES >= 70)")
else()
set(ENABLE_CUDNN_HALF "FALSE" CACHE BOOL "Enable CUDNN Half precision" FORCE)
message(STATUS "Your setup does not support half precision (it requires CUDA_ARCHITECTURES >= 70)")
endif()CUDA, CUDNN, and CUDNN_HALF (FP16) can be enabled and disabled. At the moment, if CUDA=OFF, an error occurs. Also, CUDNN is not enabled when CUDA=OFF, and CUDNN_HALF is not enabled when CUDNN is not enabled.
set(CUDA_ENABLE ON)
set(CUDNN_ENABLE ON)
set(FP16_ENABLE ON)
```
## Installation
The dependency environment is shown below.
## Required.
- ROS2 Dashing or later
- OpenCV 3.2 or later
- CUDA 10.0 or later (CUDA 11.0 or later for Ampere and later)
- GPU with 4GB VRAM capable of running the NVIDIA CUDA environment.
### As needed
- cuDNN 7 or later (should match your CUDA version)
- GPU with 6GB VRAM capable of running NVIDIA CUDA environment
- A GPU capable of FP16 operations
Assuming that the above installation has been completed, type the following command.
```bash
source /opt/ros/foxy/setup.bash
mkdir -p ~/ros2_ws/src
cd ~/ros2_ws/src
git clone --recursive https://github.com/Ar-Ray-code/darknet_ros_fp16.git
darknet_ros_yolov4/darknet_ros/rm_darknet_CMakeLists.sh
cd ~/ros2_ws
colcon build --symlink-installWith your webcam connected, type and execute the following command.
source /opt/ros/foxy/setup.bash
source ~/ros2_ws/install/local_setup.bash
ros2 launch darknet_ros demo-v4-tiny.launch.py
If you see cudnn_half=1 while loading, you are good to go.

If you can see the image, it's a success. You did it 🎉🎉🎉!
If you want to quit, use Ctrl+C to stop it.
Now, what was the main topic...? Oh, that's right. How much faster is FP16?
It's better to have a look at the graph.
I tested it in the following environment. We also benchmarked with the following assumptions
-
This is not a verification of the speed ratio between RTX 2080 Ti and Jetson AGX Xavier. It is only to verify the speed ratio in the same model and environment.
-
The model was downloaded and used as is, and no TensorRT or other processing was performed.
-
For the speed, I took the maximum and minimum FPS instead of calculating the average FPS because the values are very blurry and the calculation causes a bottleneck. As a visual impression, the minimum FPS can be calculated by (maximum FPS - minimum FPS) x 0.7 + minimum FPS.
-
Optimization settings such as
-gencode arch=compute_75,code=[sm_75,compute_75]were done manually. -
For the speed, we do not take the maximum and minimum FPS right after the start; the speed reflected after leaving it for one minute is listed as the result.
-
I used this benchmark-only branch.
The following four weight files were used
- YOLOv4x-mish.weights (640)
- YOLO v4.weights (608)
- YOLOv4-scp.weights (512)
- YOLOv4-tiny (416)
| Topics | Spec |
|---|---|
| CPU | Ryzen7 2700X (@3.7GHz x 16) |
| RAM | 16GB DDR4 |
| GPU | NVIDIA GeForce RTX 2080 Ti (GDDR6 11GB) |
| Driver | 465.19.01 |
| Topics | Version |
|---|---|
| Ubuntu | 20.04 LTS |
| ROS | Foxy |
| CUDA | 11.3 |
| cuDNN | 8.2.1 |
| OpenCV | 4.2 |
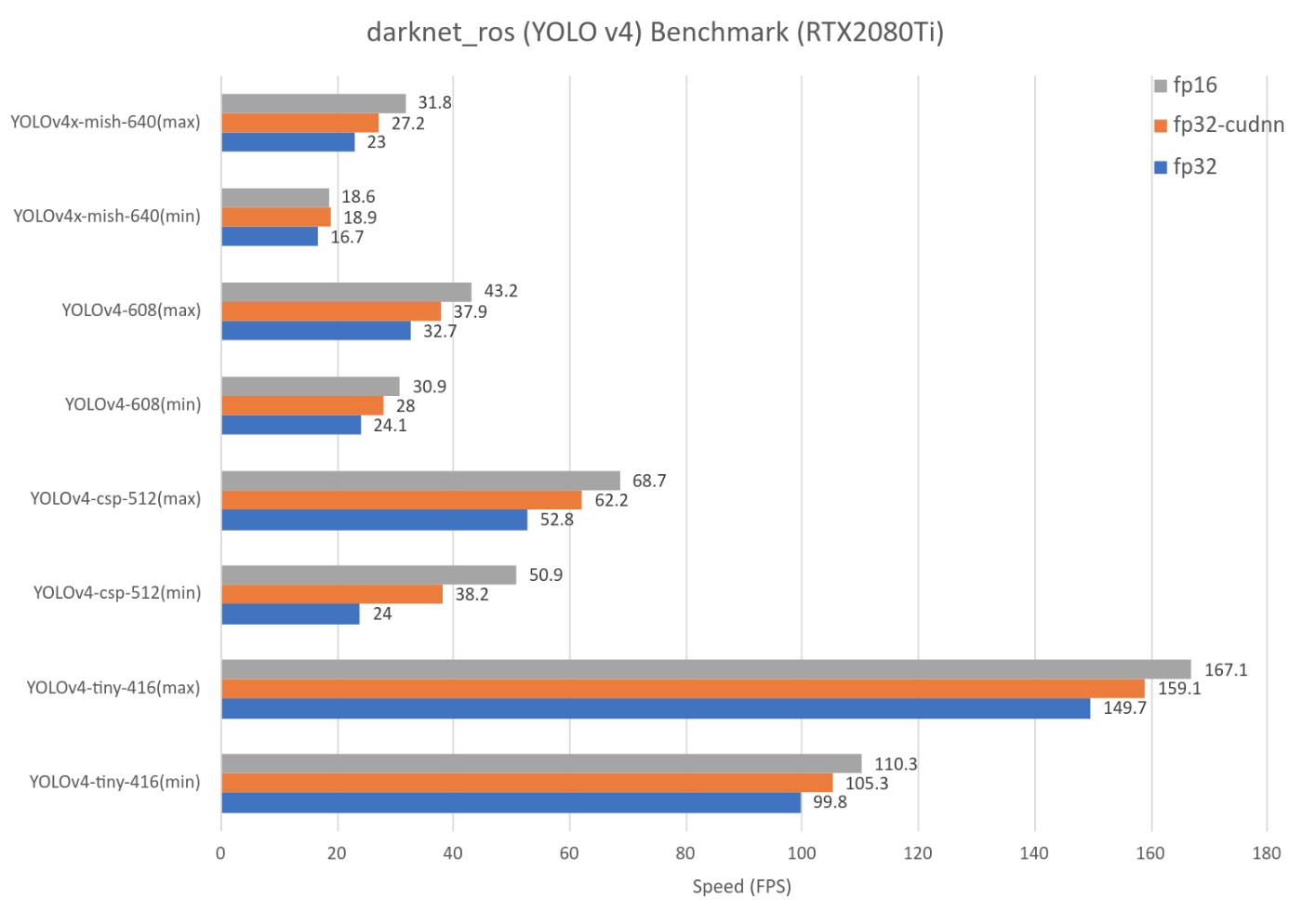
167FPS on YOLOv4-tiny🔥🔥🔥🔥🔥🔥🔥🔥
| Topics | Spec |
|---|---|
| CPU | 8-core ARM v8.2 64-bit CPU, 8MB L2 + 4MB L3 |
| RAM | 32 GB 256-Bit LPDDR4x |137 GB/s |
| GPU | 512-core Volta GPU with Tensor Cores |
| Driver | JetPack 4.4.1 |
| Topics | Version |
|---|---|
| Ubuntu | 18.04 LTS |
| ROS | Dashing |
| CUDA | 10.2 |
| cuDNN | 8.0 |
| OpenCV | 4.1 |
YOLOv4.weights and YOLOv4x-mish could not be executed on Jetson AGX Xavier.
98FPS on YOLOv4-tiny🔥🔥🔥🔥🔥🔥🔥🔥

There are three things that can be said about the RTX 2080 Ti and the Jetson AGX Xavier in common
- FPS increase especially in FP16.
- The heavier the file, the greater the increase in instantaneous FPS.
- Overall, the speed of cuDNN (FP16) is about 1.3 times faster than non-cuDNN.
However, for the Jetson AGX Xavier, we found that when using cuDNN, FP16 must be enabled for it to be of much use.
Recently, many automated applications using object detection have been developed, and AI products are becoming more accessible. And with the rapid evolution of various libraries and the spread of new notations such as ROS2, the porting of various modules is progressing, and I am selfishly assuming that "porting ability" is becoming a much needed skill.
I hope this helps those who want to use the YOLO v4 model in ROS.
If you have any questions or concerns, please don't hesitate to ask me on GitHub or Twitter, and I will do my best to answer them.
https://github.com/Ar-Ray-code/darknet_ros_fp16
https://github.com/pjreddie/darknet
https://github.com/AlexeyAB/darknet
https://github.com/leggedrobotics/darknet_ros