YOLO ("you only look once") is a popular algoritm because it achieves high accuracy while also being able to run in real-time. This algorithm "only looks once" at the image in the sense that it requires only one forward propagation pass through the network to make predictions. After non-max suppression, it then outputs recognized objects together with the bounding boxes.
-
Inputs and outputs
- The input is a batch of images, and each image has the shape (m, 608, 608, 3)
- The output is a list of bounding boxes along with the recognized classes. Each bounding box is represented by 6 numbers (pc,bx,by,bh,bw,c)(pc,bx,by,bh,bw,c) as explained above. If you expand cc into an 80-dimensional vector, each bounding box is then represented by 85 numbers.
- The input is a batch of images, and each image has the shape (m, 608, 608, 3)
-
Anchor Boxes
- Anchor boxes are chosen by exploring the training data to choose reasonable height/width ratios that represent the different classes. For this assignment, 5 anchor boxes were chosen for you (to cover the 80 classes), and stored in the file './model_data/yolo_anchors.txt'
- The dimension for anchor boxes is the second to last dimension in the encoding: (m,nH,nW,anchors,classes)(m,nH,nW,anchors,classes).
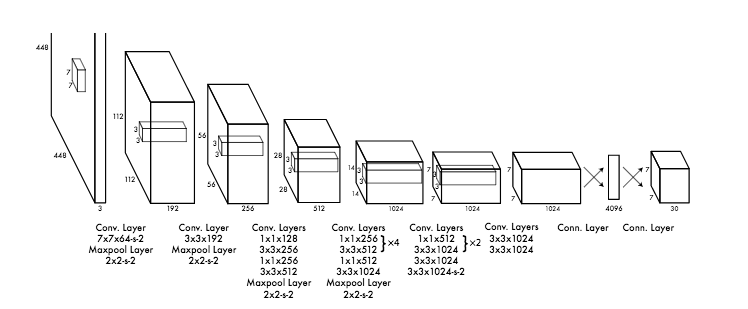
- The YOLO architecture is: IMAGE (m, 608, 608, 3) -> DEEP CNN -> ENCODING (m, 19, 19, 5, 85).
- Anchor boxes are chosen by exploring the training data to choose reasonable height/width ratios that represent the different classes. For this assignment, 5 anchor boxes were chosen for you (to cover the 80 classes), and stored in the file './model_data/yolo_anchors.txt'
- To generate yolo.h5 file go to this link. Place that in model_data folder.
- Input images are in the images directory and the correcponding output images are in the out directory.