,////,
/// 6|
// _|
_/_,-'
_.-/'/ \ ,/;,
,-' /' \_ \ / _/
`\ / _/\ ` /
| /, `\_/
| \'
/\_ /` /\
/' /_``--.__/\ `,. / \
|_/` `-._ `\/ `\ `.
`-.__/' `\ |
`\ \
`\ \
\_\__
\___)
![]()
![]()
runnable is a simplified workflow definition language that helps in:
-
Streamlined Design Process: runnable enables users to efficiently plan their pipelines with stubbed nodes, along with offering support for various structures such as tasks, parallel branches, and loops or map branches in both yaml or a python SDK for maximum flexibility.
-
Incremental Development: Build your pipeline piece by piece with runnable, which allows for the implementation of tasks as python functions, notebooks, or shell scripts, adapting to the developer's preferred tools and methods.
-
Robust Testing: Ensure your pipeline performs as expected with the ability to test using sampled data. runnable also provides the capability to mock and patch tasks for thorough evaluation before full-scale deployment.
-
Seamless Deployment: Transition from the development stage to production with ease. runnable simplifies the process by requiring only configuration changes to adapt to different environments, including support for argo workflows.
-
Efficient Debugging: Quickly identify and resolve issues in pipeline execution with runnable's local debugging features. Retrieve data from failed tasks and retry failures using your chosen debugging tools to maintain a smooth development experience.
Along with the developer friendly features, runnable also acts as an interface to production grade concepts such as data catalog, reproducibility, experiment tracking and secure access to secrets.

More details about the project and how to use it available here.
The minimum python version that runnable supports is 3.8
pip install runnablePlease look at the installation guide for more information.
Your application code. Use pydantic models as DTO.
Assumed to be present at functions.py
from pydantic import BaseModel
class InnerModel(BaseModel):
"""
A pydantic model representing a group of related parameters.
"""
foo: int
bar: str
class Parameter(BaseModel):
"""
A pydantic model representing the parameters of the whole pipeline.
"""
x: int
y: InnerModel
def return_parameter() -> Parameter:
"""
The annotation of the return type of the function is not mandatory
but it is a good practice.
Returns:
Parameter: The parameters that should be used in downstream steps.
"""
# Return type of a function should be a pydantic model
return Parameter(x=1, y=InnerModel(foo=10, bar="hello world"))
def display_parameter(x: int, y: InnerModel):
"""
Annotating the arguments of the function is important for
runnable to understand the type of parameters you want.
Input args can be a pydantic model or the individual attributes.
"""
print(x)
# >>> prints 1
print(y)
# >>> prints InnerModel(foo=10, bar="hello world")The code is runnable without any orchestration framework.
from functions import return_parameter, display_parameter
my_param = return_parameter()
display_parameter(my_param.x, my_param.y)| python SDK | yaml |
|---|---|
Example present at: Run it as: from runnable import Pipeline, Task
def main():
step1 = Task(
name="step1",
command="examples.functions.return_parameter",
)
step2 = Task(
name="step2",
command="examples.functions.display_parameter",
terminate_with_success=True,
)
step1 >> step2
pipeline = Pipeline(
start_at=step1,
steps=[step1, step2],
add_terminal_nodes=True,
)
pipeline.execute()
if __name__ == "__main__":
main() |
Example present at: Execute via the cli: dag:
description: |
This is a simple pipeline that does 3 steps in sequence.
In this example:
1. First step: returns a "parameter" x as a Pydantic model
2. Second step: Consumes that parameter and prints it
This pipeline demonstrates one way to pass small data from one step to another.
start_at: step 1
steps:
step 1:
type: task
command_type: python # (2)
command: examples.functions.return_parameter # (1)
next: step 2
step 2:
type: task
command_type: python
command: examples.functions.display_parameter
next: success
success:
type: success
fail:
type: fail |
No code change, just change the configuration.
executor:
type: "argo"
config:
image: runnable:demo
persistent_volumes:
- name: runnable-volume
mount_path: /mnt
run_log_store:
type: file-system
config:
log_folder: /mnt/run_log_storeMore details can be found in argo configuration.
Execute the code as runnable execute -f examples/python-tasks.yaml -c examples/configs/argo-config.yam
Expand
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: runnable-dag-
annotations: {}
labels: {}
spec:
activeDeadlineSeconds: 172800
entrypoint: runnable-dag
podGC:
strategy: OnPodCompletion
retryStrategy:
limit: '0'
retryPolicy: Always
backoff:
duration: '120'
factor: 2
maxDuration: '3600'
serviceAccountName: default-editor
templates:
- name: runnable-dag
failFast: true
dag:
tasks:
- name: step-1-task-uvdp7h
template: step-1-task-uvdp7h
depends: ''
- name: step-2-task-772vg3
template: step-2-task-772vg3
depends: step-1-task-uvdp7h.Succeeded
- name: success-success-igzq2e
template: success-success-igzq2e
depends: step-2-task-772vg3.Succeeded
- name: step-1-task-uvdp7h
container:
image: runnable:demo
command:
- runnable
- execute_single_node
- '{{workflow.parameters.run_id}}'
- step%1
- --log-level
- WARNING
- --file
- examples/python-tasks.yaml
- --config-file
- examples/configs/argo-config.yaml
volumeMounts:
- name: executor-0
mountPath: /mnt
imagePullPolicy: ''
resources:
limits:
memory: 1Gi
cpu: 250m
requests:
memory: 1Gi
cpu: 250m
- name: step-2-task-772vg3
container:
image: runnable:demo
command:
- runnable
- execute_single_node
- '{{workflow.parameters.run_id}}'
- step%2
- --log-level
- WARNING
- --file
- examples/python-tasks.yaml
- --config-file
- examples/configs/argo-config.yaml
volumeMounts:
- name: executor-0
mountPath: /mnt
imagePullPolicy: ''
resources:
limits:
memory: 1Gi
cpu: 250m
requests:
memory: 1Gi
cpu: 250m
- name: success-success-igzq2e
container:
image: runnable:demo
command:
- runnable
- execute_single_node
- '{{workflow.parameters.run_id}}'
- success
- --log-level
- WARNING
- --file
- examples/python-tasks.yaml
- --config-file
- examples/configs/argo-config.yaml
volumeMounts:
- name: executor-0
mountPath: /mnt
imagePullPolicy: ''
resources:
limits:
memory: 1Gi
cpu: 250m
requests:
memory: 1Gi
cpu: 250m
templateDefaults:
activeDeadlineSeconds: 7200
timeout: 10800s
arguments:
parameters:
- name: run_id
value: '{{workflow.uid}}'
volumes:
- name: executor-0
persistentVolumeClaim:
claimName: runnable-volume
A simple linear pipeline with tasks either python functions, notebooks, or shell scripts

Execute branches in parallel

Execute a pipeline over an iterable parameter.
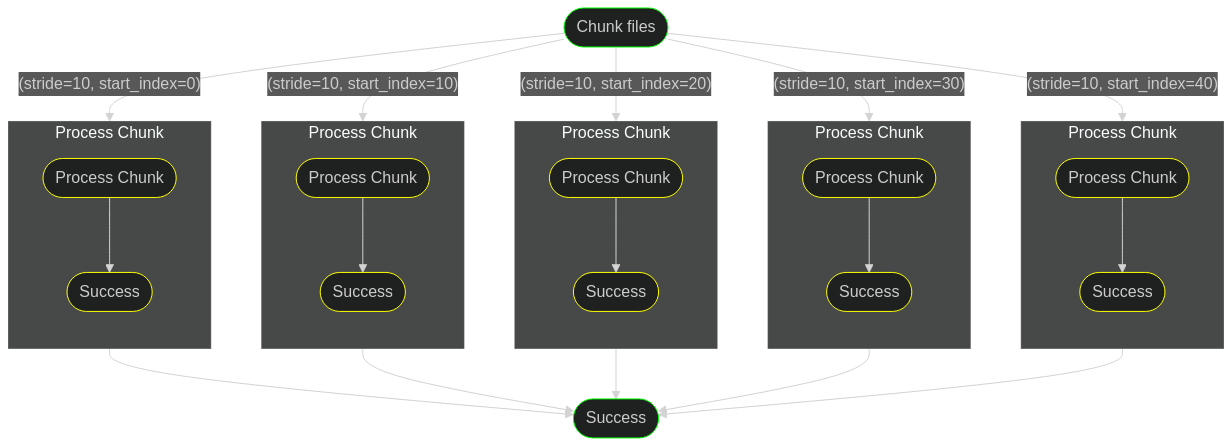
Any nesting of parallel within map and so on.