每个题目按照<Map,Reducer,Driver,....,Out>的顺序提交
数据源:
user01,https://www.td.com/,br=Android,deep=1,action=visit,date='2021-01-01:14:12:23' user01,https://www.search.td.com/苹果,br=Android,deep=2,action=visit,date='2021-01-01:15:13:10' user01,https://www.item.com/0001-苹果,br=Android,deep=3,action=visit,date='2021-01-01:16:13:24' user01,https://www.item.com/0002-苹果,br=Android,deep=4,action=visit,date='2021-01-01:16:13:27' user02,https://www.td.com/,br=Android,deep=1,action=visit,date='2021-01-01:14:12:23' user02,https://www.search.td.com/苹果,br=Android,deep=2,action=visit,date='2021-01-01:14:12:59' user02,https://www.item.com/0001-苹果,br=Android,deep=3,action=visit,date='2021-01-01:14:14:42' user03,https://www.item.td.com/0001-可乐,br=Android,deep=3,action=visit,date='2021-01-02:16:12:33' user03,https://www.item.td.com/0002-可乐,br=Android,deep=4,action=visit,date='2021-01-02:17:12:36' user03,https://www.item.td.com/0003-可乐,br=Android,deep=5,action=visit,date='2021-01-02:18:12:42' user03,https://www.item.td.com/0004-可乐,br=Android,deep=6,action=visit,date='2021-01-02:19:12:50' user03,https://www.item.td.com/0005-可乐,br=Android,deep=7,action=visit,date='2021-01-02:20:13:23' user04,https://www.td.com/,br=IOS,deep=1,action=visit,date='2021-01-01:14:12:23' user04,https://www.td.com/,br=IOS,deep=2,action=visit,date='2021-01-01:14:12:24' user05,https://www.td.com/,br=IOS,deep=1,action=visit,date='2021-01-01:14:14:23' user05,https://www.search.td.com/维生素,br=IOS,deep=2,action=visit,date='2021-01-01:14:15:23' user05,https://www.item.td.com/0001-维生素,br=IoS,deep=3,action=visit,date='2021-01-01:14:16:23'
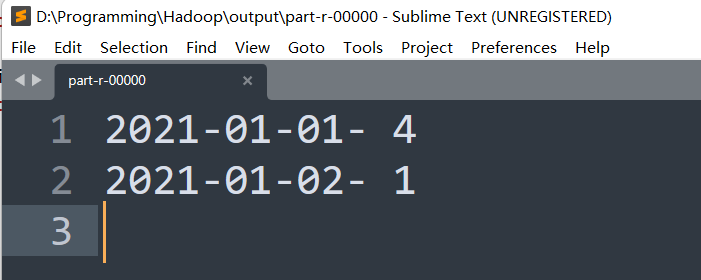
1、 统计每天一共有多少个用户访问了网站(要求输出 : 日期 - 人数) ?
**关键数据:**日期,用户
思路:
-
Map:
- 提取用户对应的日期信息,并设定日期为Key,
-
Reduce:
- 中对同一天的相同用户进行去重,再统计总用户数。
package top.ayden.one;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TestMapper extends Mapper<LongWritable,Text,Text,Text> {
@Override
protected void map(LongWritable key, Text bigDate, Context context) throws IOException, InterruptedException {
String line = bigDate.toString();
String user = line.split(",")[0];
String date = line.split("date='")[1].split(":")[0];
context.write(new Text(date), new Text(user));
}
}package top.ayden.one;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
public class TestReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text Date, Iterable<Text> users, Context context) throws IOException, InterruptedException {
//Date=date,Text=array[user]
HashSet<String> hashSet = new HashSet<>();
for (Text userValue : users) {
hashSet.add(userValue.toString());
}
context.write(new Text(Date+"-"), new Text(String.valueOf(hashSet.size())));
}
}package top.ayden.one;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-2.7.6");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "Mytest");
job.setJarByClass(TestDriver.class);
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("D:/Programming/Hadoop/input"));
FileOutputFormat.setOutputPath(job, new Path("D:/Programming/Hadoop/output"));
job.waitForCompletion(true);
}
}
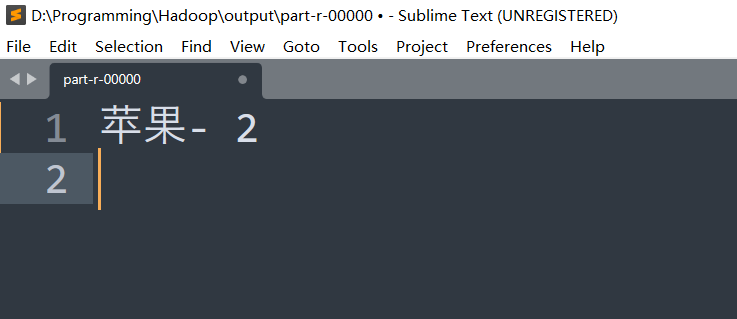
2、 统计苹果一共被搜索了多少次 (要求输出 : 商品 - 次数)?
**关键词:**search,苹果
思路:
-
map:
- 对仅包含search以及苹果的数据进行过滤,并设定url最后被GET的对象为Key,对相同的传递参数为1(传递参数的涵义为:相同参数被搜索了多少次,每一次就在数组中加1)
-
Reducer:
- 对同一关键词下的1进行迭代。计算出相同参数下,被搜索了多少次。
package top.ayden.two;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TestMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text bigData, Context context) throws IOException, InterruptedException {
String line = bigData.toString();
String urlList = line.split(",")[1];
String urlLast = urlList.substring(urlList.lastIndexOf('/') + 1);
if (urlList.contains("苹果") && urlList.contains("search")) {
context.write(new Text(urlLast), new IntWritable(1));
}
}
}package top.ayden.two;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
public class TestReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text objName, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//key=苹果,value=[1,1]
int count = 0;
for (IntWritable value : values) {
count = value.get() + count;
}
context.write(new Text(objName + "-"), new IntWritable(count));
}
}package top.ayden.two;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-2.7.6");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "Mytest");
job.setJarByClass(TestDriver.class);
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:/Programming/Hadoop/input"));
FileOutputFormat.setOutputPath(job, new Path("D:/Programming/Hadoop/output"));
job.waitForCompletion(true);
}
}
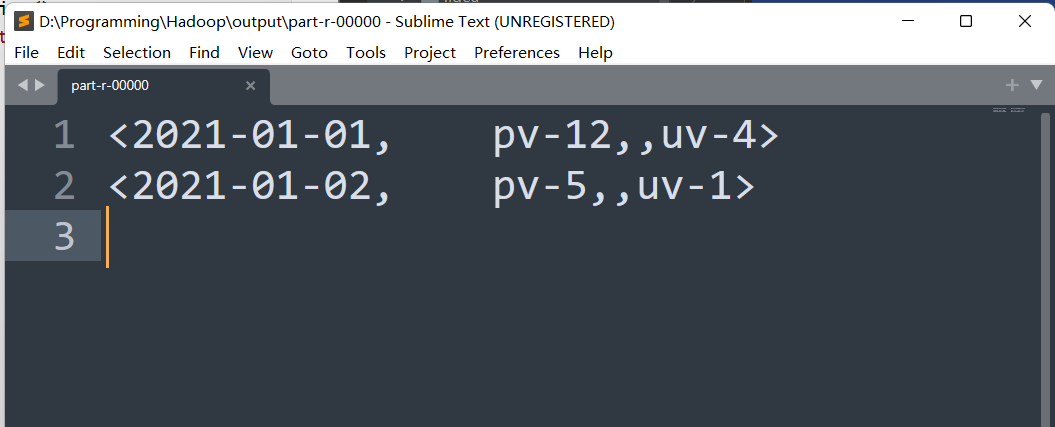
3、 统计【每天】的PV数 和 UV数 ? 【20前】
**关键数据:**日期,用户
思路:
-
Map:
- 提取用户对应的日期信息,并设定日期为Key
-
Reduce:
- 中先对总用户进行迭代得到PV,使用HashSet()对同一天的相同用户进行去重得到UV//size。
package top.ayden.three;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TestMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text bigData, Context context) throws IOException, InterruptedException {
String line = bigData.toString();
String userName = line.split(",")[0];
String date = line.split("date='")[1].split(":")[0];
context.write(new Text(date), new Text(userName));
}
}package top.ayden.three;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
public class TestReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text date, Iterable<Text> users, Context context) throws IOException, InterruptedException {
HashSet<String> uvList = new HashSet<>();
int pvCount = 0;
for (Text user : users) {
pvCount++;
uvList.add(user.toString());
}
context.write(new Text("<" + date + ","), new Text("pv-" + pvCount + "," + ",uv-" + uvList.size() + ">"));
}
}package top.ayden.three;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-2.7.6");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "Mytest");
job.setJarByClass(TestDriver.class);
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:/Programming/Hadoop/input"));
FileOutputFormat.setOutputPath(job, new Path("D:/Programming/Hadoop/output"));
job.waitForCompletion(true);
}
}
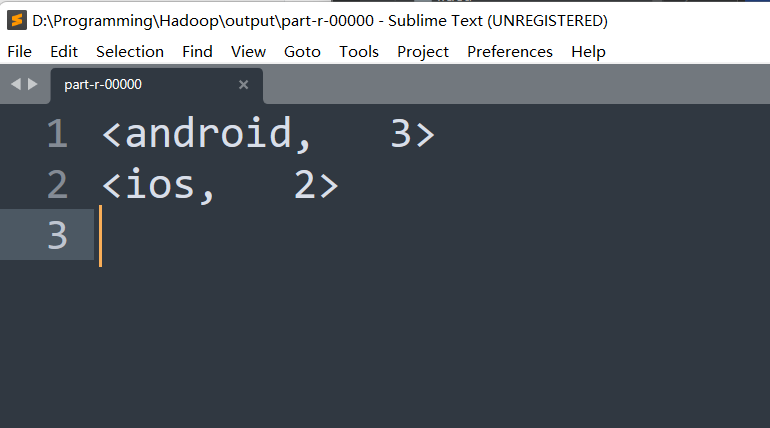
4、 统计访问平台的不同设备数?(原有编码基础上【掌握】)
**关键数据:**设备,用户
思路:
-
Map:
- 提取用户对应的设备,设定android或ios为判断条件,判定类型,并设定设备为Key,用户为Values。
-
Reduce
- 中使用HashSet()对同一天的相同用户进行去重,再统计总用户数//size,即为不同的设备对应的有多少人在使用。
package top.ayden.four;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Locale;
public class TestMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text bigData, Context context) throws IOException, InterruptedException {
String line = bigData.toString();
String dev = line.split(",")[2].split("br=")[1].toLowerCase();
String user = line.split(",")[0];
if (dev.contains("android") || dev.contains("ios")) {
context.write(new Text(dev), new Text(user));
}
}
}package top.ayden.four;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
public class TestReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text devKey, Iterable<Text> users, Context context) throws IOException, InterruptedException {
HashSet<Text> userCount = new HashSet<>();
for (Text user : users) {
userCount.add(user);
}
context.write(new Text("<" + devKey + ","), new Text(userCount.size()+">"));
}
}package top.ayden.four;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-2.7.6");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "Mytest");
job.setJarByClass(TestDriver.class);
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("D:/Programming/Hadoop/input"));
FileOutputFormat.setOutputPath(job, new Path("D:/Programming/Hadoop/output"));
job.waitForCompletion(true);
}
}
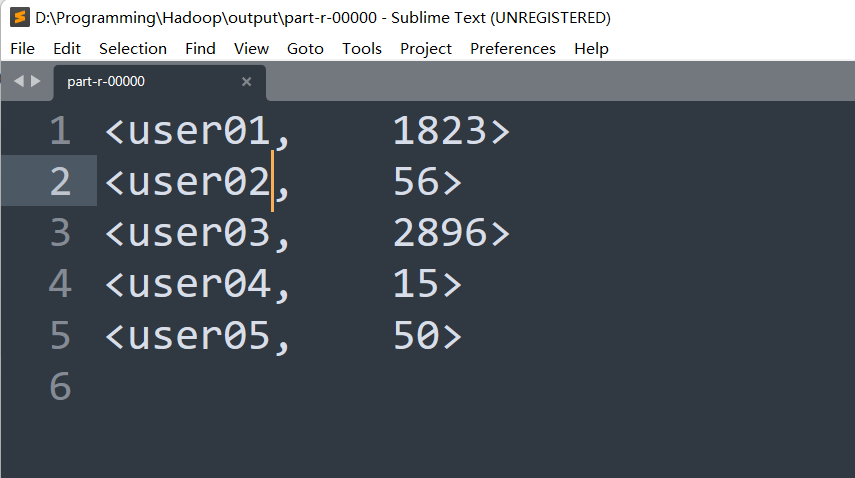
5、 计算每个用户的平均访问时长是多少,结果精确到秒级别?(开发需求)
关键词:时间、用户
思路:
- Map
中对数据进行预处理,先将对应的小时、分钟、秒全部转换为秒,并对其进行相加、将user设定为Key、将values设定为其访问的所有的网站对应的时间。
- Reducer
- 排序
- 接收到map传递的参数后,定义一个列表,传递到这个无限列表中,并对其进行排序。
- 迭代
- 然后从大到小进行迭代,每一次迭代,都用后一项减去前一项,并加上为0的secondAvg。因为最后一个页面为30秒,所以在总秒数上加上30。并除以页面数,得到最后的平均访问时长。
- 排序
package top.ayden.five;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TestMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text bigData, Context context) throws IOException, InterruptedException {
String line = bigData.toString();
String userName = line.split(",")[0];
String allDateToSecond = line.split(",")[5].split("date=")[1].replace("\'", "");
context.write(new Text(userName), new IntWritable(dateToSecond(allDateToSecond)));
}
public static int dateToSecond(String date) {
int hour = Integer.parseInt(date.split(":")[1]) * 60 * 60;
int minute = Integer.parseInt(date.split(":")[2]) * 60;
int second = Integer.parseInt(date.split(":")[3]);
return hour + minute + second;
}
}package top.ayden.five;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
public class TestReducer extends Reducer<Text, IntWritable, Text, Text> {
@Override
protected void reduce(Text users, Iterable<IntWritable> allDateToSecond, Context context) throws IOException, InterruptedException {
//定义一个列表,将所有的秒数传入并排序
ArrayList<Integer> allSecondList = new ArrayList<>();
for (IntWritable value : allDateToSecond) {
allSecondList.add(value.get());
}
Collections.sort(allSecondList);
int secondAvg = 0;
for (Integer i = 0; i < allSecondList.size() - 1; i++) {
secondAvg += allSecondList.get(i + 1) - allSecondList.get(i);
}
secondAvg = (secondAvg + 30) / allSecondList.size();
context.write(new Text("<"+users+","), new Text(secondAvg+">"));
}
}package top.ayden.five;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-2.7.6");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "Mytest");
job.setJarByClass(TestDriver.class);
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:/Programming/Hadoop/input"));
FileOutputFormat.setOutputPath(job, new Path("D:/Programming/Hadoop/output"));
job.waitForCompletion(true);
}
}
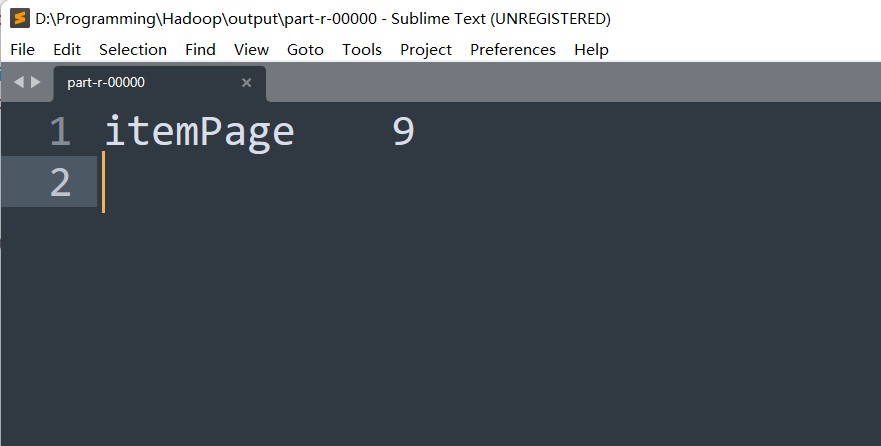
6、 在所有的浏览页面中,访问的商品页面是多少?
**关键词:**item
思路:
-
map
- 对仅包含item的数据进行过滤,并设定itemPage的对象为Key,对相同的传递参数为1(传递参数的涵义为:相同参数被访问了多少次,每一次就在数组中加1),
-
Reducer
- 对itemPage进行迭代。计算出相同参数下,被访问了多少次。
package top.ayden.six;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TestMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text bigData, Context context) throws IOException, InterruptedException {
String line = bigData.toString();
String urlList = line.split(",")[1];
if (urlList.contains("item")) {
context.write(new Text("itemPage"), new IntWritable(1));
}
}
}package top.ayden.six;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
public class TestReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//[1,1]
@Override
protected void reduce(Text objName, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable value : values) {
count += value.get();
}
context.write(new Text(objName), new IntWritable(count));
}
}package top.ayden.six;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-2.7.6");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "Mytest");
job.setJarByClass(TestDriver.class);
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:/Programming/Hadoop/input"));
FileOutputFormat.setOutputPath(job, new Path("D:/Programming/Hadoop/output"));
job.waitForCompletion(true);
}
}
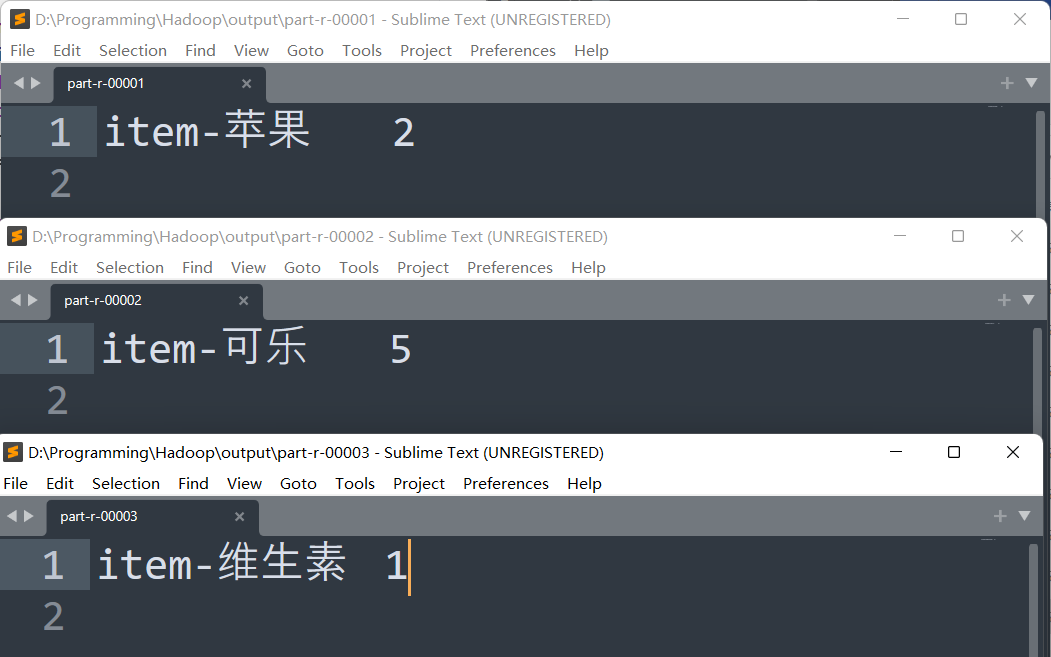
7、 把访问的所有商品详情页的数据存储到不同的文件中,要求一个商品的所有信息写入到一个文件中?
**关键词:**item,商品名
思路:因为要对数据进行分文件输出,所以我们要用到中间类Partitioner进行分区,在Hadoop中,传递的顺序为map-Partitioner-Reducer
- map
- 对仅包含Item以及商品名的数据进行过滤,并设定"item-商品名"的对象为Key,并传递“PageLast”为values.
- Partitioner
- 传递到中间项目Partitioner,进行分区,对"苹果""维生素""可乐",进行分区,分区后传到Reducer中。
- Reducer
- 传递所有values进行迭代,并传递到HashSet中进行去重。输出Map传递过来的Key"item-商品名",以及对应商品名过略后的访问页面有多少个进行输出。
package top.ayden.seven;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TestMapper extends Mapper<LongWritable, Text,Text,Text> {
@Override
protected void map(LongWritable key, Text bigData, Context context) throws IOException, InterruptedException {
String line = bigData.toString();
String[] data=line.split(",");
String[] urlList = data[1].split("/");
String s = urlList[urlList.length-1];
if (data[1].contains("苹果") && data[1].contains("item")){
context.write(new Text("item-苹果"),new Text(s));
}
if (data[1].contains("可乐") && data[1].contains("item")){
context.write(new Text("item-可乐"),new Text(s));
}
if (data[1].contains("维生素") && data[1].contains("item")){
context.write(new Text("item-维生素"),new Text(s));
}
}
}package top.ayden.seven;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
public class TestReducer extends Reducer<Text,Text, Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
HashSet<Text> a = new HashSet<>();
for (Text value:values){
a.add(value);
}
context.write(key, new Text(Integer.toString(a.size())));
}
}package top.ayden.seven;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class TestSuffer extends Partitioner<Text,Text> {
@Override
public int getPartition(Text text, Text text2, int i) {
if (text.toString().contains("苹果")){
return 1;
}
if (text.toString().contains("可乐")){
return 2;
}
if (text.toString().contains("维生素")){
return 3;
}
else {
return 0;
}
}
}package top.ayden.seven;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TestDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-2.7.6");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "Mytest");
job.setJarByClass(TestDriver.class);
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setPartitionerClass(TestSuffer.class);
job.setNumReduceTasks(4);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text .class);
FileInputFormat.setInputPaths(job, new Path("D:/Programming/Hadoop/input"));
FileOutputFormat.setOutputPath(job, new Path("D:/Programming/Hadoop/output"));
job.waitForCompletion(true);
}
}