Home
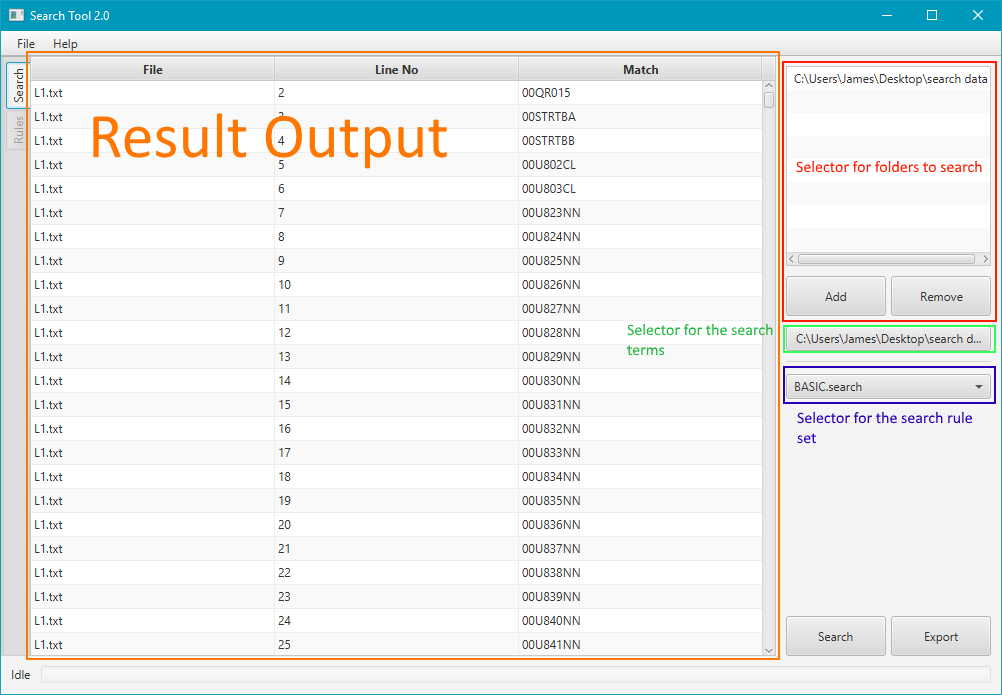
- Select the folder or folders to search in, the tool will traverse all subdirectories in each folder.
- Select the file that contains the terms to search for.
- Select the search rule file to use, this file dictates what data is collected while searching. The tool searches the
./rulesdirectory for files matching*.searchand attempts to parse the file. Any invalid files in this directory will cause subsequent files not to be read and an error message to be generated.
The rule files are a flat text format made of rules separated by a line as shown in the example below.
EXCLUDE_FILE
.
INCLUDE_FILE
.*.txt
GROUP_TAG
^--(?<category>)
category
EXCLUDE_LINE
.
INCLUDE_LINE
=
EXCLUDE_LINE
^--
SEARCH_MATCH
(/w+) = %search%(\W|$)
parameter=1
| Name | Description |
|---|---|
| EXCLUDE_FILE | Excludes a file from the search |
| INCLUDE_FILE | Includes a file that was excluded |
| EXCLUDE_LINE | Excludes a line from the search |
| INCLUDE_LINE | Includes a line that was excluded |
| GROUP_TAG | Keeps track of a category that each match is a part of |
| SEARCH_MATCH | Specifies the exact format of the match and extra data to extract from that line |
| START_SEARCH_STATE | Specifies whether or not the searcher starts enabled at the start of the file |
| SWITCH_ON | Switches the searcher on for lines following a match |
| SWITCH_OFF | Switches the searcher off for the lines following a match |
Each rule is defined by an identifier, which must be typed exactly as it is shown above, and several lines of data that governs its function. A line must be left between each rule, this rule is not read and can be used for comments if desired.
START_SEARCH_STATE takes one line of input 'ON' or 'OFF' this rule can be effected by file level excludes and includes but not line level rules.
All of the EXCLUDE_X, INCLUDE_X and SWITCH_X rules are defined by just one line of data, a regex expression that is used to match the file names or lines that they apply to.
The GROUP_TAG and SEARCH_MATCH rules have two lines of data, a regex that is used to match and a second line naming the columns that they add to the results table. Each one of these column names must match a corresponding named group in the regex expression, as seen in the example file. Also the SEARCH_MATCH rule uses the special string %search% to mean the search term found, it is guaranteed to match that and only that. If you need to write %search% without it meaning that surround part of it in a closure group e.g. %(search)%. Note that if there are no columns to add for the SEARCH_MATCH or GROUP_TAG rules the data line for them must contain a single comma, as seen below.
Use EXCLUDE_X rules to remove as much as possible for the best performance.
The order of all the rules matter, the EXCLUDE_X, INCLUDE_X and SWITCH_X rules can be used as if statements to apply certain rules to certain files or lines.
EXCLUDE_FILE
\.java$
SEARCH_MATCH
( |^)%search%( |$)
,
EXCLUDE_FILE
.
INCLUDE_FILE
\.java$
SEARCH_MATCH
(\W|^)%search%\.
,
This rule file will cause the (\W|^)%search%\. rule to be used for java source files and ( |^)%search%( |$) to be used for every other extension type.
This tool uses the syntax called regex to match text and extract data. For a reference to the regex syntax there are many sources easily found via google. This tool uses the Java syntax of regex, which may or may not differ from other dialects. In addition to that I found this site very useful for testing expressions, although it does not support the named groups needed to extract data.