python3.6
pip install -r requirements.txt
cd code
bash run.sh
The trend in the Machine learning world in the last few years was to get the biggest models, train them on huge amounts of data and then ensemble them in order to get the last few percents of accuracy. One drawback of this approach is that big models or ensembles can be challenging to deploy in a real life application. Their weights size can be too big or their inference time may be too long for any practical use, especially if you are trying to use them on a embedded device or on the client-side of a web application.
There is also active research on how to make models that achieve decent performance while being small and fast, by building custom architectures for mobile like in MobileNets or by weight quantization.
In this post we will demonstrate how we can boost the performance of a tiny neural network by using Knowledge Distillation (From : Distilling the Knowledge in a Neural Network) and MixUp (From : mixup: Beyond Empirical Risk Minimization). The basic idea behind Knowledge Distillation is that you define a Teacher (which can be a single model or an ensemble) and a Student ( Which is the lightweight model you want to use in production), then you train the Teacher on the target task and have the Student try to mimic the Teacher.

We will use the MIT-BIH dataset that is available in a pre-processed state on Kaggle Datasets : https://www.kaggle.com/mondejar/mitbih-database. This dataset contains individual heartbeats that are classified into five classes related to arrhythmia abnormalities.

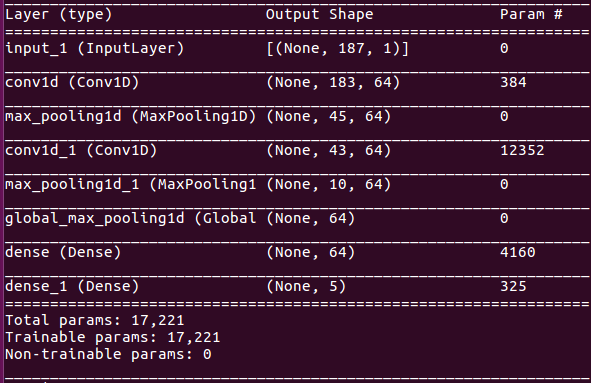
The teacher model is a 1D CNN that has Convolution layers with 64 filters each and two fully connected Layers. It comes to a total of 17,221 trainable parameters.
The student Model has the same structure as the Teacher but with smaller convolution layers. It comes to a total of 3,909 trainable parameters, so 4x smaller than the teacher model.

We train the Teacher model using the categorical cross-entropy applied to the one-hot labels. When applying knowledge distillation the Student model is trained using a mix between the Kullback Leibler divergence and the MAE loss on the soft labels predicted by the Teacher model as target.
The Kullback Leibler divergence measures the difference between two probability distributions, so the objective here is to make the distribution {over the classes} predicted by the Student as close as possible from the Teacher.
Without using any Knowledge distillation the tiny model achieved an F1 score of 0.67 +- 0.02, after using knowledge distillation the performance of the tiny model was boosted to 0.78 +- 0.02. We were able to gain 11 performance points in term of F1 score using the same architecture when using knowledge distillation.
Summary of the results :
- F1 Teacher model : 0.82 +- 0.006
- F1 tiny mode + Knowledge distillation : 0.78 +- 0.02
- F1 tiny mode from scratch : 0.67 +- 0.02
In this post we were able to implement a simple Knowledge Distillation training scheme that was able to boost the performance of a very small model from 0.67 F1 to 0.78 F1 using the exact same architecture. This can be useful when having the smallest model possible with decent performance is important for deployment purposes for example.
There is much to be explored when using this approach, like using an ensemble as a teacher or how the size difference between the Teacher and Student influences the quality of the Knowledge distillation. This will be done in a future post 😃.