Following the Triple Pattern Fragments (TPF) approach, intelligent clients are able to improve the availability of the Linked Data. However, data availability is still limited by the availability of the TPF servers. Although some existing TPF servers belonging to different organizations already replicate the same datasets, existing intelligent clients are not able to take advantage of replicated data to provide fault tolerance and load-balancing.
In this paper, we propose Ulysses, an intelligent TPF client that takes advantage of replicated datasets to provide fault tolerance and load-balancing. By reducing the load of a server, Ulysses improves the overall Linked Data availability and reduces data hosting cost for organizations. Ulysses relies on an adaptive client-side load-balancer and a cost-model to distribute the load among heterogeneous replicated TPF servers. Experimentations demonstrate that Ulysses reduces the load of TPF servers, tolerates failures and improves queries execution time in case of heavy loads on servers.
Keywords: Semantic Web, Triple Pattern Fragments, Intelligent client, Load balancing, Fault tolerance, Data Replication
An online version of the Ulysses query engine is available at http://ulysses-demo.herokuapp.com/. Please use the http version of this website, and not the https version, due to Heroku hosting policy.
Requirements
- Node.js version 8.* or higher
npm install -g ulysses-tpf
Usage: ulysses-tpf <servers...> [options]
Execute a SPARQL query against several servers using adaptive Ulysses
Options:
-q, --query <query> evaluates the given SPARQL query
-f, --file <file> evaluates the SPARQL query in the given file
-t, --timeout <timeout> set SPARQL query timeout in milliseconds (default: 30mn)
-c, --catalog <json-file> a custom catalog contained in a JSON file
-h, --help output usage information
We use one instance of the Waterloo SPARQL Diversity Test Suite (WatDiv) synthetic dataset with 10^7 triples, encoded in the HDT format.
Online versions of the generated dataset are available at:
- http://34.212.44.110/watDiv_100
- http://34.216.147.78/watDiv_100
- http://35.167.12.122/watDiv_100
- http://35.160.176.165/watDiv_100
We generate 50,000 DISTINCT queries from 500 templates (STAR, PATH, and SNOWFLAKE shaped queries). Next, we eliminate all duplicated queries, and then pick 100 random queries to be used in our experiments. Queries that failed to deliver an answer due to a query engine internal error with the regular TPF client are excluded from all configurations.
Generated queries are available on Github.
| Number of servers | p-value | Completeness |
|---|---|---|
| 1 server | 2.83019e-17 | 100% |
| 2 servers | 9.0472e-12 | 100% |
| 3 servers | 5.05541e-12 | 100% |
We executed our 100 random queries using Ulysses using one, two and three homogeneous TPF servers. As a baseline, we also executed our queries with the reference TPF client, with one TPF server. In all configurations, Ulysses is able to produce the same answers as the baseline for all queries.
To confirm that Ulysses does not deteriorate query execution time, a Wilcoxon signed rank test for paired non-uniform data was run for the query execution time results obtained by Ulysses, using up to three servers, with the following hypothesis:
- H0: Ulysses does not change SPARQL query execution time compared to the reference TPF client.
- H1: Ulysses does not increase SPARQL query execution time compared.
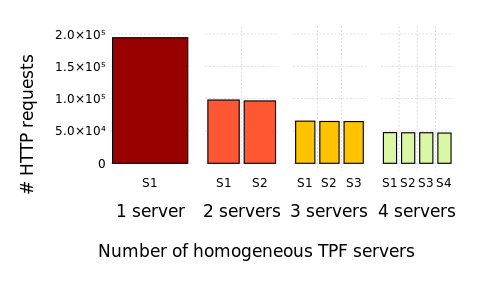
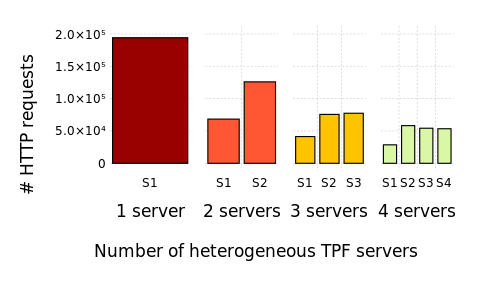
Average number of HTTP requests received by servers after evaluation of WatDiv queries with total replication.
All servers have same capabilities (homogeneous servers)
S1 is three times slower than the others (heterogeneous servers)
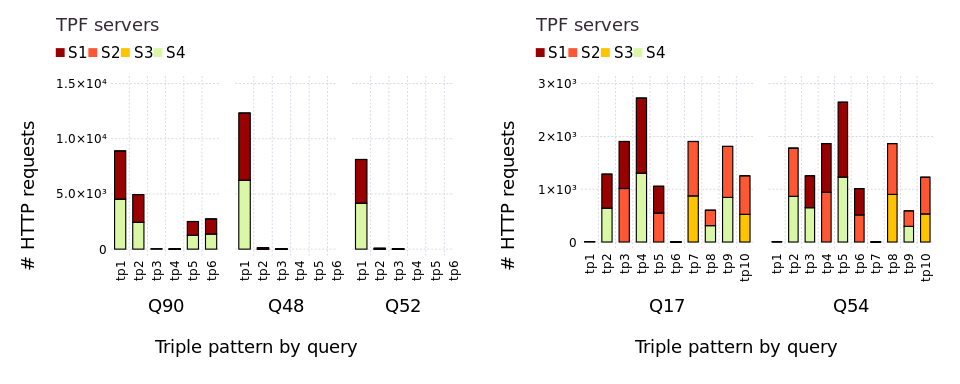
Average number of HTTP requests received by servers after evaluation of The five queries that generate the most HTTP requests, with partial replication and homogeneous servers.
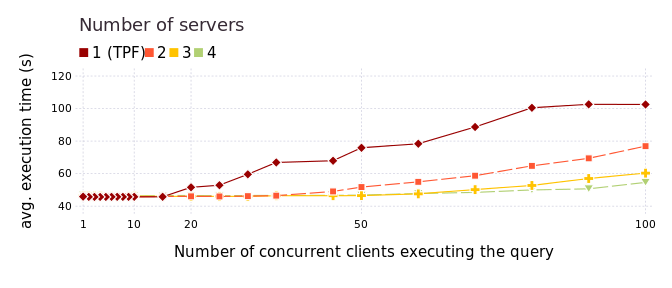
Average query execution time with an increasing number of concurrent clients and available servers, using Ulysses client.
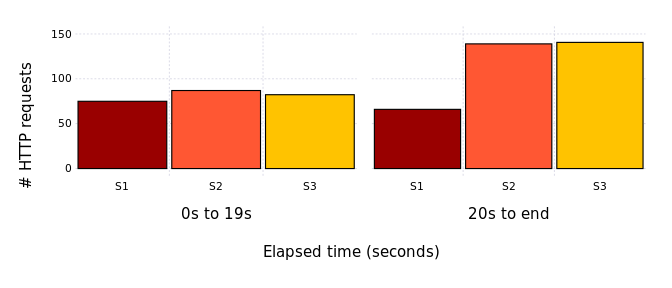
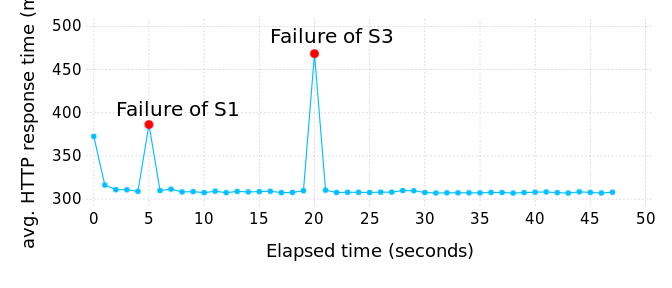
Average HTTP response time when evaluating query 72 using three homogeneous servers (S1, S2, S3) in presence of failures: S1 fails at 5s and S3 fails at 20s.
Average number of HTTP requests received by servers S1, S2, S3 during evaluation of query 72. Servers start homogeneous, then S1 access latency is tripled at 20s.