{kind=link}
{kind=link}
A simulator for a superscalar out-of-order processor in python.
To simply run an benchmark program, try:
python processor.py ../benchmark_kernels/fib.asm
For more information try:
python processor.py --help
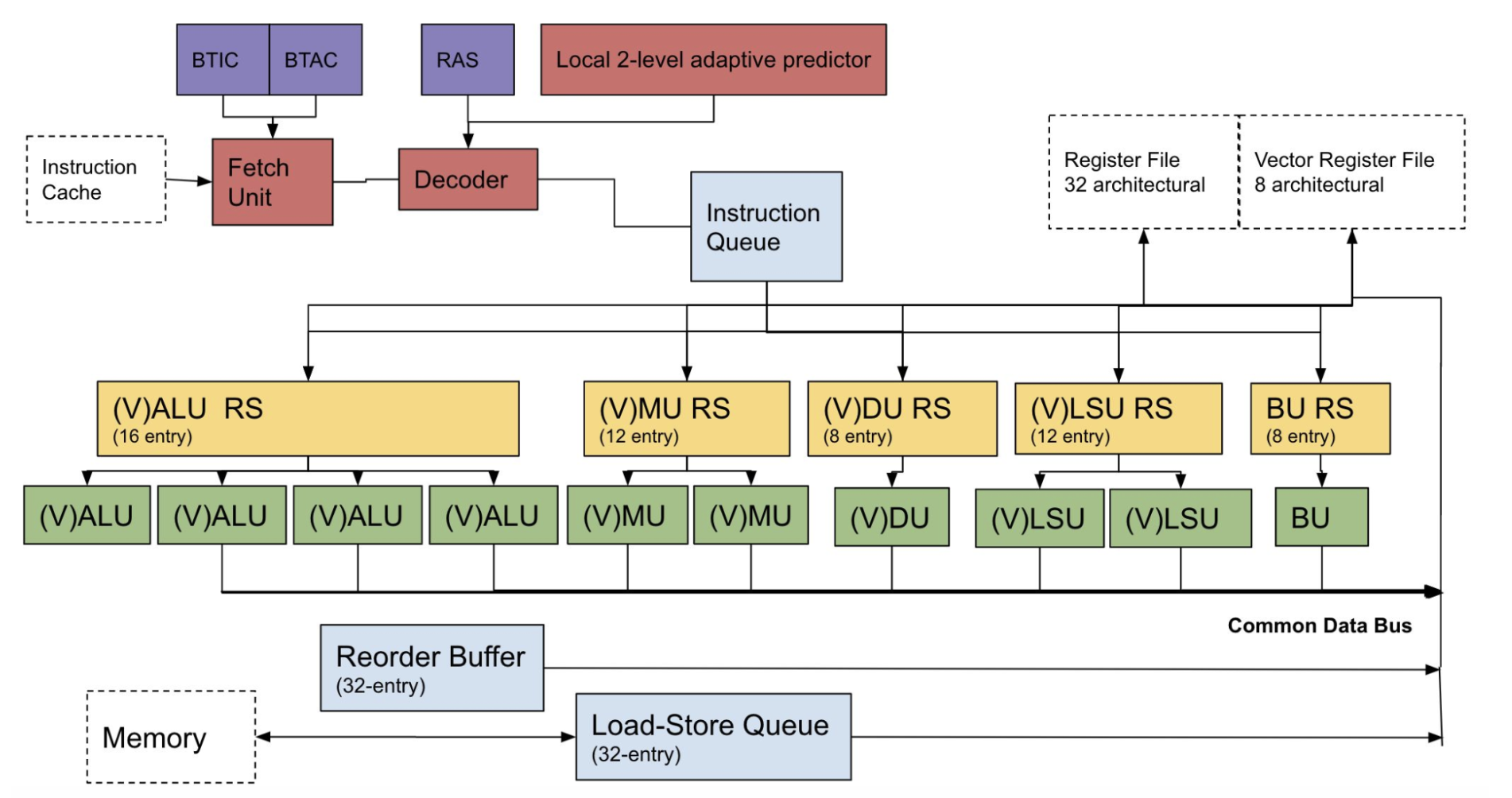 with a Register Alias Table (RAT) and Reorder Buffer (ROB)
with a Register Alias Table (RAT) and Reorder Buffer (ROB)
- Supports Arithmetic, Load and Store, Unconditional Jumps (e.g. jump and link, system call), Conditional Jumps (e.g. branch if equal)
- Support multi-cycle instructions
- Only supports integer operation (no float point i.e. FPU)
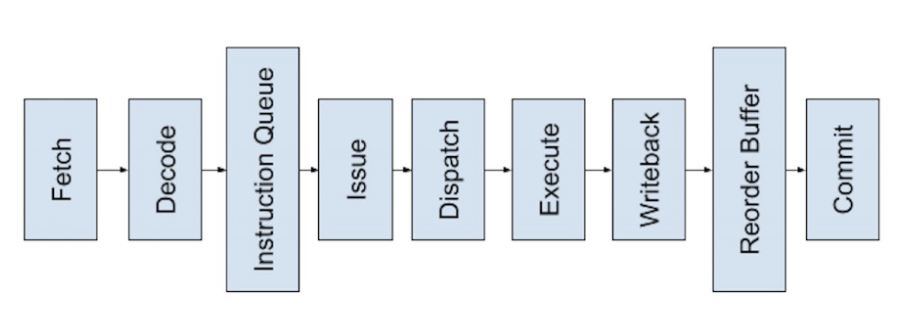
- 7 stage pipeline - fetch, decode, issue, dispatch, execute, writeback, commit
- Execution Units - ALU (Arithmetic Logic Unit), MU (Multiplication Unit), DU (Division Unit), LSU (Load Store Unit)
- Decouples fetch-decode and writeback-commit with instruction queue and reorder buffer.
- Execution units of multi-cycle instructions are fully pipelined (bar the DU, which cannot be pipelined)
- Priority writeback - prioritises the retirement of slow multi-cycle instructions when more options than the pipeline width are available
- Speculative execution with infinite levels of speculative depth
- Implements a Two-level local dynamic/adaptive predictor for conditional branch prediction
- Implements a N-bit local pattern history (N = 2 default)
- Implements a 2^N entry branch history register table with S-bit saturating counters (S = 2 default)
- Implements a Branch Target Address Cache and Instruction Cache (BTAIC) to cache branch speculations
- Implements a Return Address Stack (RAS) to return from multiple nested function calls
- Uses a checkpointing mechanism to recover from failed branch speculation
- Recovers from mispredicted branches by flushing at commit
- N-way superscalar where N is configurable
- Implements Tomasulos Algorithm - for out-of-order execution of instructions that writeback to registers
- Implements a Load Store Queue (with store-to-load forwarding) - for out-of-order execution of instructions that writeback to memory
- Recovers from a wrongly speculatively loaded value of memory addresses by flushing at commit
- Implements Register Renaming with a Register Alias Table (RAT) and Reorder Buffer (ROB)
- configurable vector length - default 16 (AVX2 ISE) .
- Vector ISA - Vector Arithemetic Operations, Vector Load and Store Operations, Vector Mask Operations, Vector Blend Operations