Streaming hashing is broken #816
Comments
|
Hi @smarchini , I've also confirmed your issue. |
|
Great point indeed, Just verifying that one-shot and streaming variants output the same value could be done very quickly, without even a need to pre-record the expected values. |
|
I copied @smarchini's test as a gist file for testing. cd
git clone https://github.com/Cyan4973/xxHash.git xxHash-issue-816
cd xxHash-issue-816
curl -JOL https://gist.githubusercontent.com/t-mat/63b391d628980d5d276a002cc578136f/raw/xxHash-issue-816.c
git checkout 3f5c75c
git log -1
cc xxHash-issue-816.c && ./a.out && echo OK || echo Error
# OK
git checkout 44bb94e
git log -1
cc xxHash-issue-816.c && ./a.out && echo OK || echo Error
# Error |
|
Hmmm...looks like an off by one then. I'll take a look. This is totally my fault sooo 😅 So the error seems to happen when |
|
Got it, it should be |
yeah we really need this test for QEMU platforms. |
|
Draft version of sanity check for direct vs streaming hash functions.
// cli/xsum_sanity_check.c
static void XSUM_XXH32_testDirectVsStreaming(const void* data, size_t dataSizeInBytes, XXH32_hash_t seed) {
XXH32_hash_t directHash;
XXH32_hash_t streamingHash;
XXH32_state_t *state = XXH32_createState();
XXH32_reset(state, seed);
XXH32_update(state, data, dataSizeInBytes);
streamingHash = XXH32_digest(state);
XXH32_freeState(state);
directHash = XXH32(data, dataSizeInBytes, seed);
if (directHash != streamingHash) {
XXH32_canonical_t directCanonical;
XXH32_canonical_t streamingCanonical;
const unsigned char* du8s = directCanonical.digest;
const unsigned char* su8s = streamingU8s.digest;
XXH32_canonicalFromHash(&directCanonical, directHash);
XXH32_canonicalFromHash(&streamingCanonical, streamingHash);
XSUM_log("\rError: Simple direct vs streaming loop test: %zd bytes, Internal sanity check failed. \n", dataSizeInBytes);
XSUM_log("\rDirect { 0x%02X, 0x%02X, 0x%02X, 0x%02X }, Streaming { 0x%02X, 0x%02X, 0x%02X, 0x%02X } \n",
du8s[0], du8s[1], du8s[2], du8s[3],
su8s[0], su8s[1], su8s[2], su8s[3] );
exit(1);
}
}
XSUM_API void XSUM_sanityCheck(void)
{
size_t i;
#define SANITY_BUFFER_SIZE 2367
XSUM_U8 sanityBuffer[SANITY_BUFFER_SIZE];
...
/* XXH32 simple loop test for direct and streaming API */
for (i = 0; i < SANITY_BUFFER_SIZE; i++) {
XSUM_XXH32_testDirectVsStreaming(sanityBuffer, i, 0);
}
...
} |
Possibly, though note that the current size would have been large enough to detect issue #816. There must be a limit anyway. I'm slightly concerned about test runtime on weaker systems if the nb of lengths to test becomes really high. So an extended limit should probably stay within the ~ 4 KB range. Maybe
Possibly, |
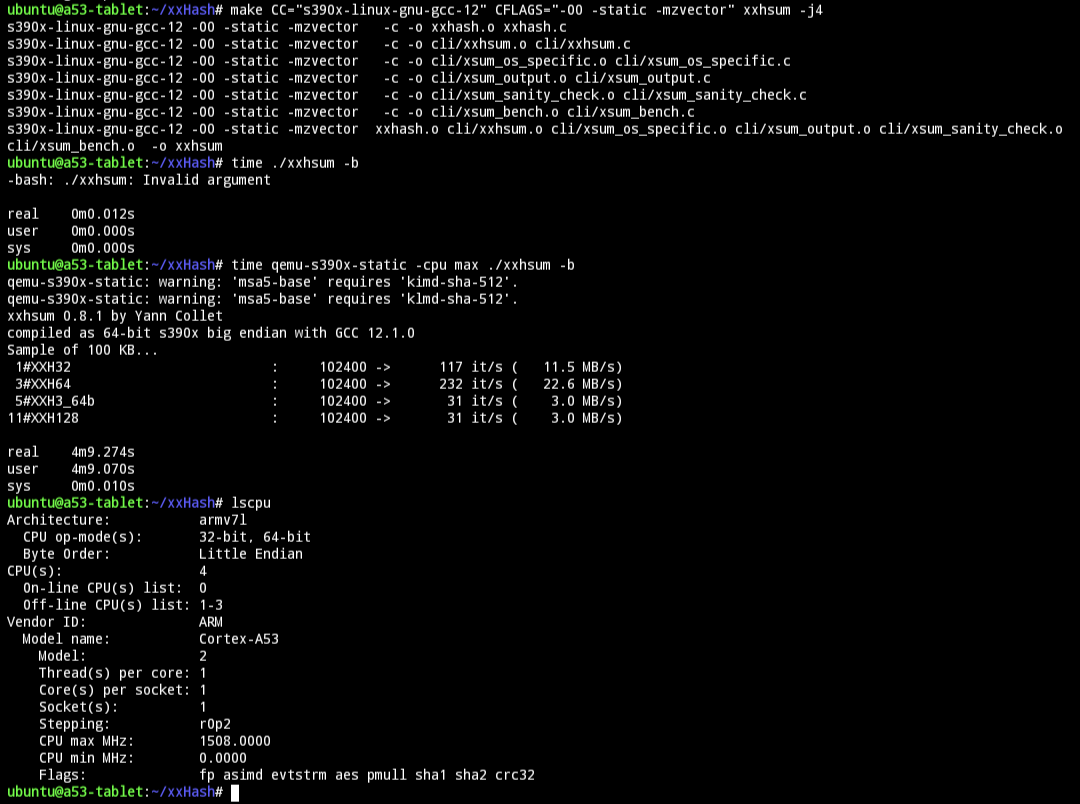
I mean you say that but you also "conservatively" assume 300 MB/s in the benchmark that this test would presumably run with. If I go to an extreme (my 1.5 GHz Cortex-A53 running s390x -O0 in qemu) I get as low as 10 MB/s. 🤷♀️ I say that we should assume that you are running the test on a competent platform or make the self test separate from xxhsum -b. Edit: XD
Also we have |
|
We should probably set it as a dedicated test program, so that we are free of runtime considerations within |
|
As a starting point, I wrote dumb (and huge) test vector generator: Please let me know we can go ahead this direction or not. Also, should we separate test vector generator and actual sanity test program? |
Fix off-by-one in XXH3_consumeStripes() (Fixes #816)
to detect off-by-one scrambling error like #816
This is a great start @t-mat !
Probably ? |
|
@Cyan4973 , @easyaspi314 |
Since 44bb94e, incremental hashing (i.e., the XXH*_update functions) produce a different output than the stateless functions. I tested them in their 64bits variant, here's how to reproduce:
The first mismatch happens at 2049 bytes, then they realign after 64 bytes. The the second mismatch is happens at 3073 bytes, so 1024 bytes after the first one. The pattern repeats. In 3f5c75c everything works fine.
The text was updated successfully, but these errors were encountered: