Resque workers start hanging with activated ddtrace #466
Comments
|
@NobodysNightmare Thanks for the report... I'm bummed to hear this is happening. I'll take a look into this, see if we can figure out what's going on. Also the detail you provided is really helpful! We'll follow up here with more questions as we dig in deeper. |
|
Could you tell me more about what these jobs are roughly doing? How long do they run? What integrations are they expected to trace? If you were able to estimate how many spans they generate, what would that number be? Anything that can help us replicate the bug will make this immensely easier and quicker to fix. |
|
It really is a mixed bag of jobs that blocks. For example calculation jobs or mail delivery jobs. All are interacting with a SQL database in one way or another. The expected integrations for those jobs:
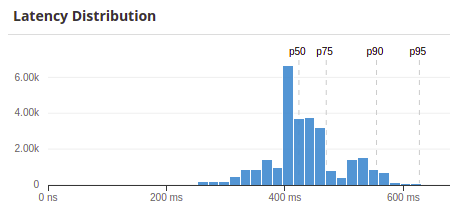
Span countFor one job class I clicked through the traces and it uses either 14 or 22 spans. So nothing extraordinary large. To clarify: The jobs run fine until they get blocked, this is why I can look up their span counts. RuntimeRegarding runtime: They are usually well below one second (this is the job class I clicked through earlier): Though above the 99th percentile (1.8 seconds) the times go up to a maximum of a minute. The hightest trace sample I could get was at 1.7 seconds and had the "usual" 22 spans, so nothing extra ordinary there either :( Note: This specific class of jobs is enqueued once per day and then we have a few ten thousand jobs queued up. More bisectingWe are currently evaluating whether I will also try to reproduce the error in a different application. |
|
@NobodysNightmare Maybe rbspy can help you identify what your workers are doing when they hang. |
|
We've also experienced problems with resque. Web requests and spans worked as expected. We tried enabling this integration when installing the 0.12 beta gem. Since it wasn't something we had enabled before I just disabled it and moved on until I could take another look at it, as it was only a "nice to have" feature then. Jobs that normally takes a couple of ms to complete took forever to finish (but I think they actually finished eventually and wasn't timed out). Sometimes the jobs completes as expected and sometimes not. Since it was a few months ago I don't have any numbers or traces available anymore. As far as I can remember there's no typical kind job that fails. Some jobs do http requests, some connect to redis, some to mysql and some sending emails etc. Our config at the time: Datadog.configure do |c|
c.tracer env: Rails.env, enabled: (Rails.env.production? || Rails.env.staging?)
c.use :resque
c.use :grape
c.use :rails
c.use :graphql, schemas: [HittamaklareSchema]
end |
|
@delner edit: I could provoke lockups with 0.11.4 now too. The only difference that's left for me is which integrations we had enabled before... I am now going to try and gradually disable/enable integrations. Stay tuned... |
|
We were still able to reproduce the issue with Datadog.configure do |c|
c.tracer enabled: yml_config[:enabled]
c.use :rails, service_name: yml_config[:service_name]
c.use :resque, service_name: service.call('resque'), workers: [ApplicationJob]
endand so far it did not occur again using Datadog.configure do |c|
c.tracer enabled: yml_config[:enabled]
c.use :rails, service_name: yml_config[:service_name]
endI would give it a few more hours to validate the error is gone and then probably try re-enabling other integrations again. I am still not sure whether this is about a specific integration or more about having multiple of them active at the same time. We did not yet test another application, hopefully that will start tomorrow... |
|
Thanks for such detailed report and for continued debugging @NobodysNightmare! If you would be able to provide us with a backtrace of locked thread in a hung worker that would be of great help. I think this gem could be of some assistance - https://github.com/frsyuki/sigdump - it traps a signal, and outputs all threads backtraces to a file. With However if the Ruby VM is locked. Then in such case its still possible to extract some information using |
|
To give some update for today:
|
|
Thanks for checking it @NobodysNightmare! If |
|
Hey there, we did some more experimental rollouts. While we could not see the bug on every project we deployed, we could reproduce it (in production) on the following environments: |
|
@NobodysNightmare thanks for continuing working on this! While I still wasn't able to reliably cause worker to hang locally. After looking at the code closely I have a strong suspicion that this could be caused directly or indirectly by our special trace writer we only use in Resque - and this problem seems to only show up in Resque integration. Its the only special component ( I've created this PR #474 that disables that special writer and instead flushes all data at the job exit. The difference is that its uses less resources (in some cases - a lot less) than the special If you would be able to try out the changes from that PR and see if the problem still persists, it would allow us to eliminate one possible source. |
|
@pawelchcki I am going to include that branch in our Gemfile and see if the error can still be reproduced. Please make sure not to remove the branch and the tip commit without letting us know, since our |
|
Will do @NobodysNightmare. |
|
I have bad news: Whatever the cause is, apparently we did not yet find it. Thank you very much for your continued support. |
|
We now obtained a dump using |
|
@NobodysNightmare Thanks! Its in locked state as per line 3 (pthread_mutex_lock) and its caused by calling In general that lock probably happens quite rarely but if every freshly spawned worker tries to resolve the agent hostname, then it increases the probability of this bug showing up. By default we try to resolve 'localhost' as agent hostaname. It can be overriden by using tracer options If you set hostname to |
|
This would explain why we do not see it in one of our apps. There we
configure the agent using its ip. So this is very possible.
I will confirm that tomorrow.
Pawel Chojnacki <notifications@github.com> schrieb am Di., 26. Juni 2018,
16:37:
… @NobodysNightmare <https://github.com/NobodysNightmare> Thanks!
Looks like the backtrace of the second thread confirms lingering suspicion
I had that the workers might block on resolving DNS hostname.
#0 0x00007f827a76bd5c in __lll_lock_wait () from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f827a7673a9 in _L_lock_926 () from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f827a7671cb in pthread_mutex_lock () from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f82732dd4a4 in _nss_files_gethostbyname2_r () from /lib/x86_64-linux-gnu/libnss_files.so.2
#4 0x00007f8279c00e75 in gethostbyname2_r () from /lib/x86_64-linux-gnu/libc.so.6
Its in locked state as per line 3 (pthread_mutex_lock) and its caused by
calling gethostbyname2_r which in turn was executed by Ruby trying to
resolve the hostname.
In general that lock probably happens quite rarely but if every freshly
spawned worker tries to resolve the agent hostname, then it increases the
probability of this bug showing up.
By default we try to resolve 'localhost' as agent hostaname. It can be
overriden by using tracer options
<https://github.com/DataDog/dd-trace-rb/blob/master/docs/GettingStarted.md#tracer-settings>
If you set hostname to 127.0.0.1 then ruby will not need to resolve
hostnames.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#466 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAbr0HBZ2C4dMWYEmV0jTBJZ7vOlr_c8ks5uAkcugaJpZM4UrklV>
.
|
|
I configured the hostname of the tracer to be We will still observe our natural load closely and see if anything unexpected happens. (Update: a day later we still do not see any issues :)) So how do we proceed here? Should we use |
|
Great that its working stable now! As for next steps, I'd suggest keeping using As for addressing underlying issue, upgrading I don't think the bug is something we can fix on our side, however if you would provide info which |
|
@NobodysNightmare since the underlying cause was identified and we've got a working workaround for systems which exhibit this bug, I'm going to close this issue. Thanks for great help with diagnosing this! |
**What does this PR do?**: This PR adds the "Resque workers hang on exit" issue discussed in #3015 to the "Known issues and suggested configurations" section of our docs. **Motivation**: This issue seems to come up a few times, e.g. in: * #466 * #2379 * #3015 ...so I've decided to document the issue and the best-known workaround so that other customers than unfortunately run into it may find our suggested solution. **Additional Notes**: N/A **How to test the change?**: Docs-only change.
We are currently in the process of rolling out datadog over our applications. However, we encountered a quite severe issue which we believe we tracked down to the
ddtracegem.Observed behaviour
Resque workers will eventually end in a state where they are deadlocked. This means the worker is alive, but the processing of the current job never finishes.
Subjectively this happens faster for workers that process lots of jobs (always have a full queue) than for workers that have not as much to do.
stracetells us, that the deadlocked processes are waiting for a user space mutex. One example:When we remove the
ddtracegem and its configuration from our project, we don't get any deadlocking resque workers.So far we observed this behaviour only on resque workers. We got no timeouts whatsoever for our web servers.
Environment
These are the versions of a few gems in that project:
These are the specs for the application where we observed this issue, I will try to reproduce it in another environment with more recent ruby/rails versions.
edit: Reproduced the error on more environments by now
This is our datadog initializer:
Bisecting
We updated
ddtracefrom0.12.0to0.12.1when encountering the issue, so both versions are affected for us.Before the problems started we already had
ddtracerunning on the affected application, but in version0.11.4and without explicitly activating any integration (thus just rails + whatever that loads automatically were active). In that state we have not had any problems.Thanks for your support, tell me if you need any further information.
The text was updated successfully, but these errors were encountered: