https://www.datafountain.cn/competitions/334/details 赛题的baseline开源
标签: 2019数字中国创新大赛
本文使用EAST模型作为文字框检测模型https://github.com/argman/EAST , 在文字识别OCR模型上使用西安交通大学人工智能实践大赛第一名@ yinchangchang 的方案https://github.com/yinchangchang/ocr_densenet
本文代码均已开源在且已经修改成了可以在ModelArts训练的格式,可以对比开源的EAST和OCR代码,查看修改了哪些地方。 本文在OCR模型上花6个小时,仅训练了10个epoch,在排行榜A榜得到0.42的F1,笔者目测再训练久一点F1>0.80是肯定有的。
在ModelArts上训练的注意事项: 1.需要修改文件保存、修改、读取的方法,具体请看1.2节; 2.训练是将OBS上的启动文件所在目录下载到GPU机器上运行,GPU机器用户路径为/home/work/,如需要下载数据到机器上,推荐下载到/cache/目录下(机器上的所以数据在一次训练作业完成后,都会清空); 3.请及时查看作业运行状态,以免造成代金券浪费;
为了节省优惠券以及线上操作时间,在上ModelArts之前,先将数据处理完成后再上传。解压所有下载的数据包。
ModelArts使用注意点:
1.如果发现没有某个python库,需要在训练脚本里加上“os.system(‘pip install xxx’)”,系统会自动安装这个库;
2.无法直接使用open方法读写OBS上的文件,需要使用moxing.Framework.file.File代替open,如open(‘input.txt’,’r’)-> moxing. Framework.file.File(‘input.txt’,’r’);
3.Glob也需要moxing.Framework.file.glob;
4.一般情况下,ModelArts的每个引擎都对保存checkpoint方法做了对OBS路径的适配,如果发现不能保存也可以将checkpoint路径设置为”./xxx”或者“/cache/xxx”,然后再使用mox.file.copy('./model.ckpt', 's3://ckpt/model.ckpt')
将EAST代码上传到OBS:
使用ModelArts创建训练作业,注意不能使用notebook创建,notebook里没有GPU资源,而且使用notebook也只能暂时保存数据,一旦关闭后,数据都会清空,而且不关闭notebook,会消耗大量代金券。但是使用OBS存储的数据不会清空,使用创建作业方式训练可以节省代金券。
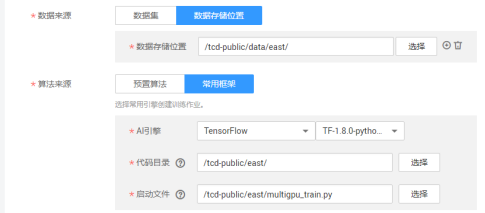
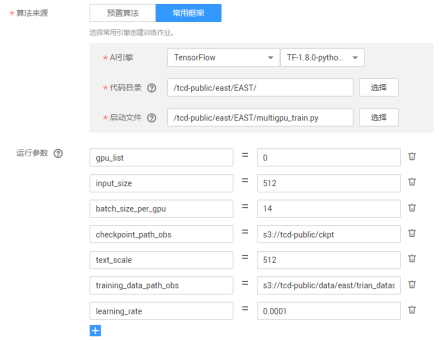
参数列表:
gpu_list=0
input_size=512
batch_size_per_gpu=14
checkpoint_path_obs=s3://tcd_public/ckpt
text_scale=512
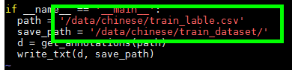
training_data_path_obs=s3://tcd_public/data/east/
geometry=RBOX
learning_rate=0.0001
num_readers=24
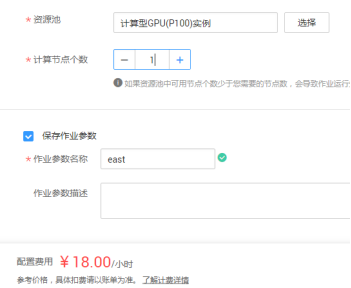
选择计算资源,并保存作业参数,以便下次使用,就可以开始运行了(18块钱真的贵)。
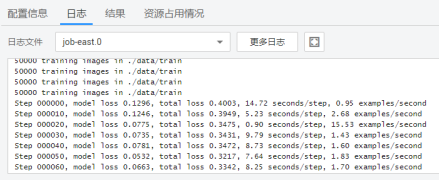
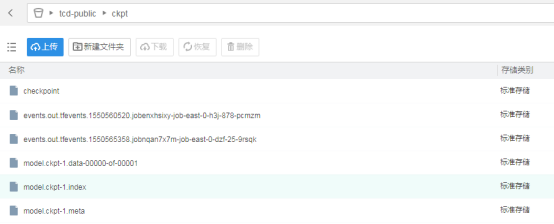
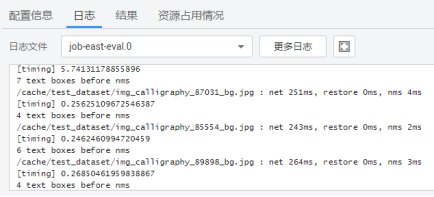
在训练到一定精度后,就可以测试了。同样创建作业,选择test数据集,使用EAST里的eval.py脚本,输入必要参数,就可以开始运行。
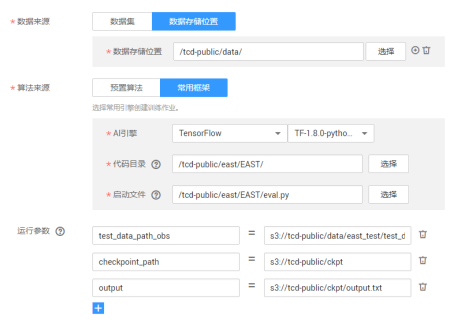

数据主要包含以下要求:
- 1.开源的第一名代码需要使用一个train.csv,包含name和content两个字段的文件
- 2.训练OCR需要截取原图的数据中的每一列文字,这里只简单使用最大的xy坐标截取;
- 3.生成测试数据集;
- 4.所有数据集均保存到data/dataset/train/和test/下,可以少改些代码;
本文只使用了训练数据集,没有将验证集加入训练,如要取的更高的精度,应该将验证集也加入训练。
在线下使用ocr中的makedata.py生成训练所需要的数据格式,替换makedata.py里数据的相关路径。其中目标路径最好填写为ocr/data/dataset/train/和ocr/data/dataset/test/,input_file是指文字检测模型的推理输出output.txt,output_file是作品样例提交文件。


再在code中的preprocessing下运行map_word_to_index.py和analysis_dataset.py对数据做分析和文字提取,这个操作会在ocr/file/下生成训练的文字和图片的相关文件。 处理完数据就可以将ocr下所有代码和数据都上传OBS了。 当然如果觉得线下数据上传到OBS速度较慢,可以选择使用ModelArts的notebook,此时需要先下载原数据到notebook的机器上,如data_path=’/cache/data’, from moxing.framework import file file.copy_parallel(data_path_obs, data_path) 处理完数据后,再上传到OBS上, file.copy_parallel(你在/cache/下处理完后的数据路径, ocr需要的数据路径如/ocr/data/dataset/train/)
训练策略几乎与开源的方案一样,但是比赛使用的数据是竖排的,这里简单在dataloader.py里使用transpose转置成横向的。
创建作业,输入参数:
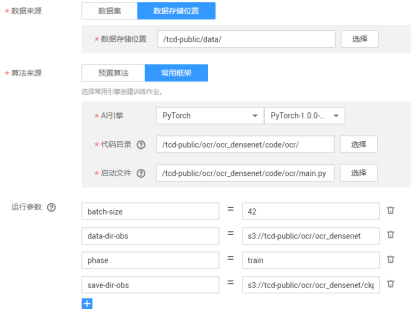
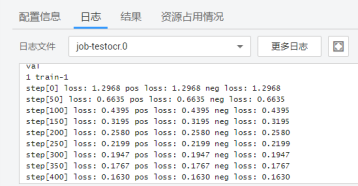
这里设置每一个epoch保存一次ckpt,在save-dir-obs路径下可以看到ckpt文件。
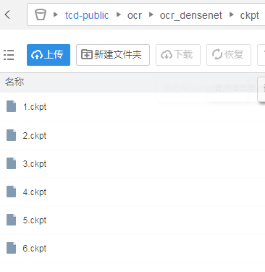
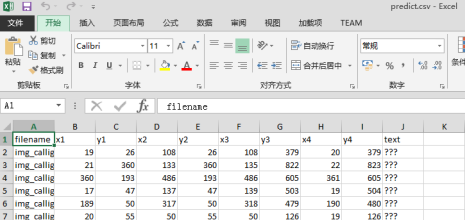
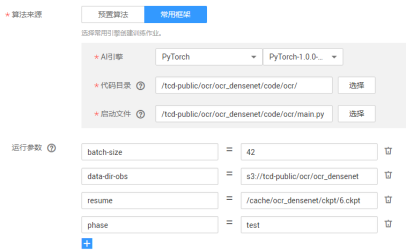
用main.py做预测,设置phase为test,设置resume参数使用的ckpt路径,设置为GPU机器上的/cache/路径,参数如图,
最终可以在OBS路径上看到predict.csv的文件,下载就可以上传到比赛官网了。