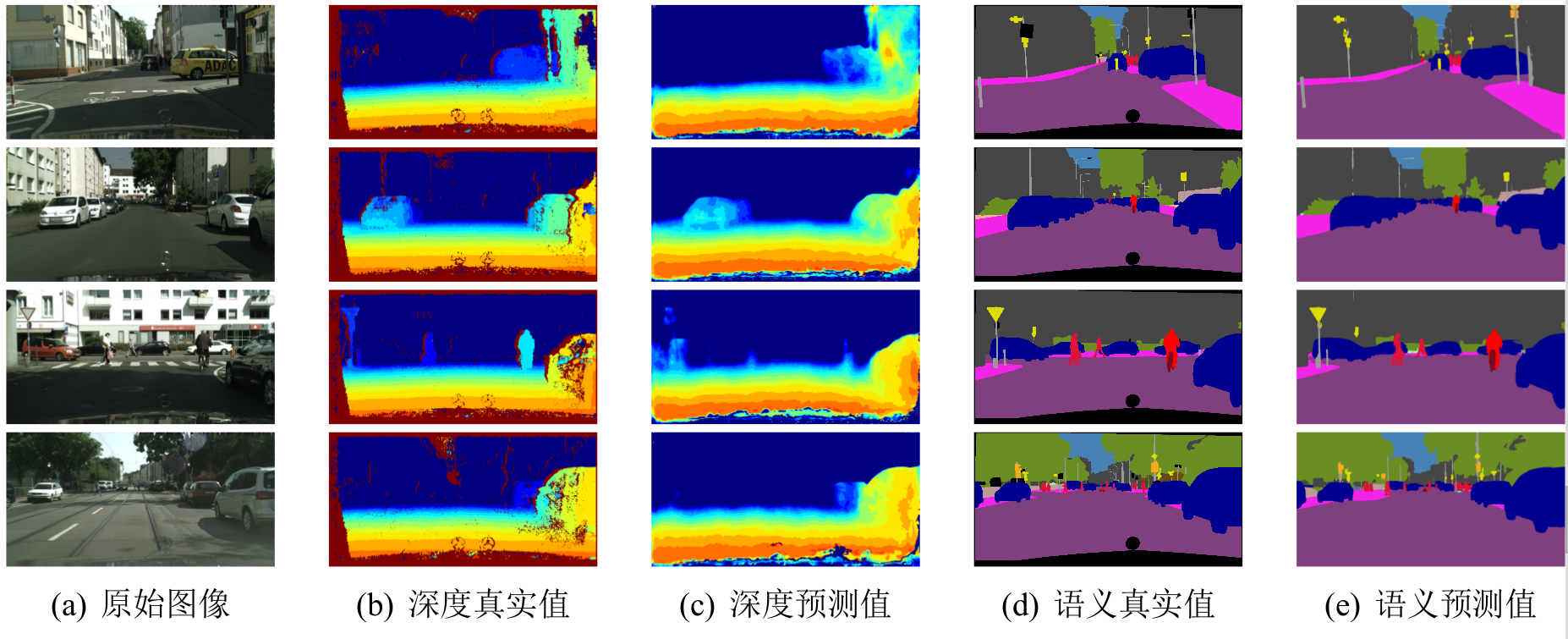
本项目旨在实现车辆前方行车环境的实时解析。具体通过对行车记录仪的图像、视频数据的语义分割和深度估计实现。要实现的目标如下图所示:
本项目在实现行车环境场景语义分割和深度估计实时解析的过程中,尝试使用了不同的模型,有复现文献中提出的网络框架TRL、也有在语义分割ICNet的基础上增加深度分支,最后自己搭建了一个轻量化的模型。
TRL(Joint Task-Recursive Learning for Semantic Segmentation and Depth Estimation)是ECCV 2018上一个同时实现语义分割和深度估计的网络。网络框架如下图所示:
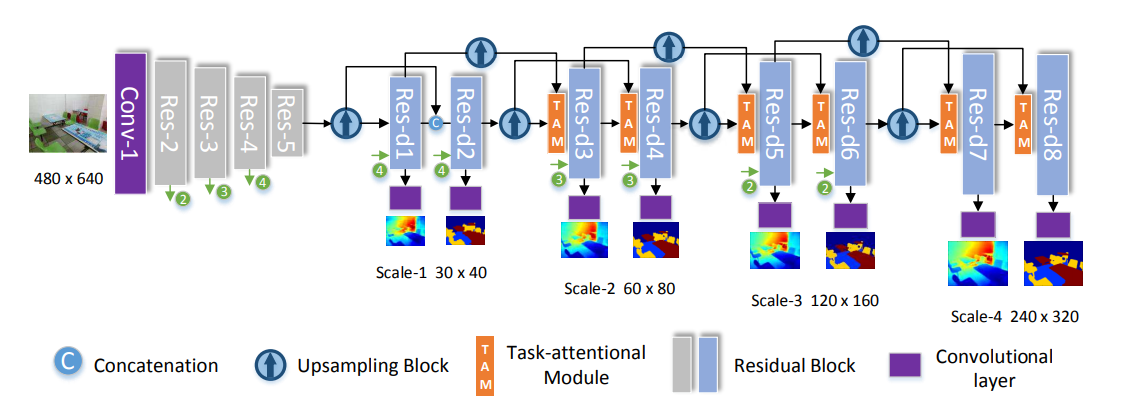
TRL network整体上是一个Encoder-Decoder的结构。 输入的RGB图像通过ResNet被处理成了不同尺度的特征图,这些特征图随后被输入到Decoder模块中处理得到语义信息和深度信息。在Decoder中,总共有4个语义预测分支和4个深度估计分支,二者交替进行。每一分支在进行预测时,都会综合前面已经提取的语义特征和深度特征,因为语义和深度存在一定的关系,二者特征的融合有利于提升精度。
但是在复现完论文后发现,网络的参数量高达(150)341M,发现原网络在多处对通道数为2048的特征图进行了多尺度的卷积操作,有$11,33,55,77$,因为卷积操作的参数量、计算量与卷积核尺寸、通道数成正比,$55,77$的大卷积核大大增加了参数量和计算量。先用1×1的卷积降维,再用3×3的空洞卷积替代5×5、7×7的卷积,减少了参数量,同时也提高了计算速度。
ICNet是在PSPNet基础上改进的语义分割网络,旨在提高语义分割的速度。网络包含三个分支,不同分支上网络深度和特征图的尺寸不一样。在较小的特征图上充分提取语义信息,再和高分辨率分支提取的特征相融合补充细节信息。本项目在ICNet的基础上,在输出语义预测的模块并行增加了深度估计分支。
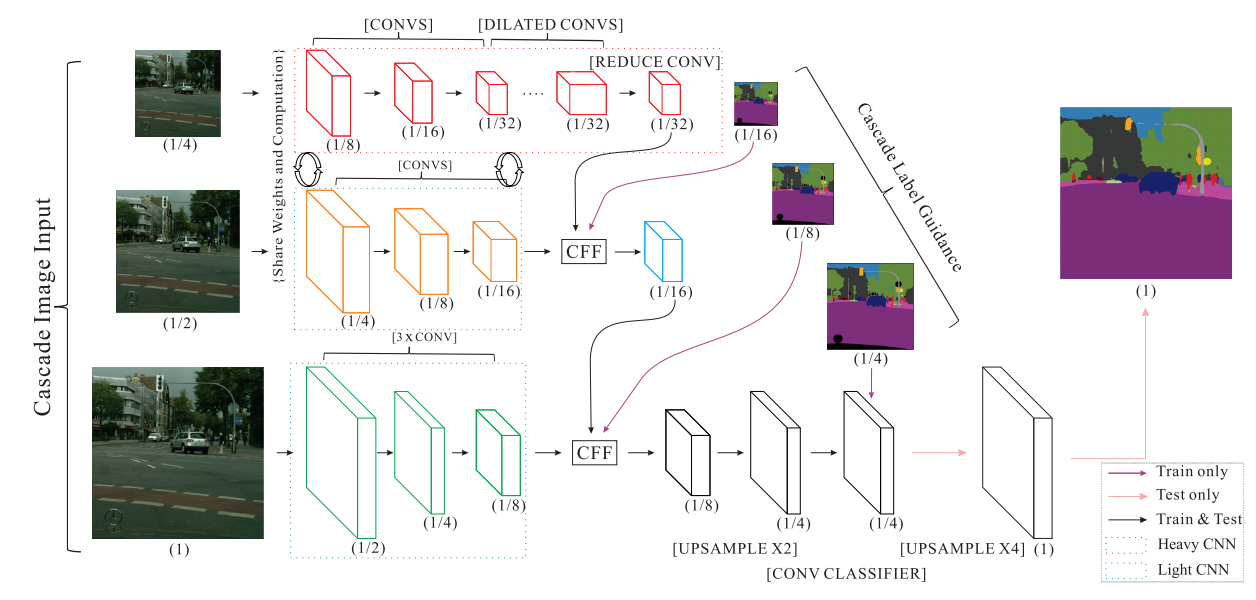
网络结构图
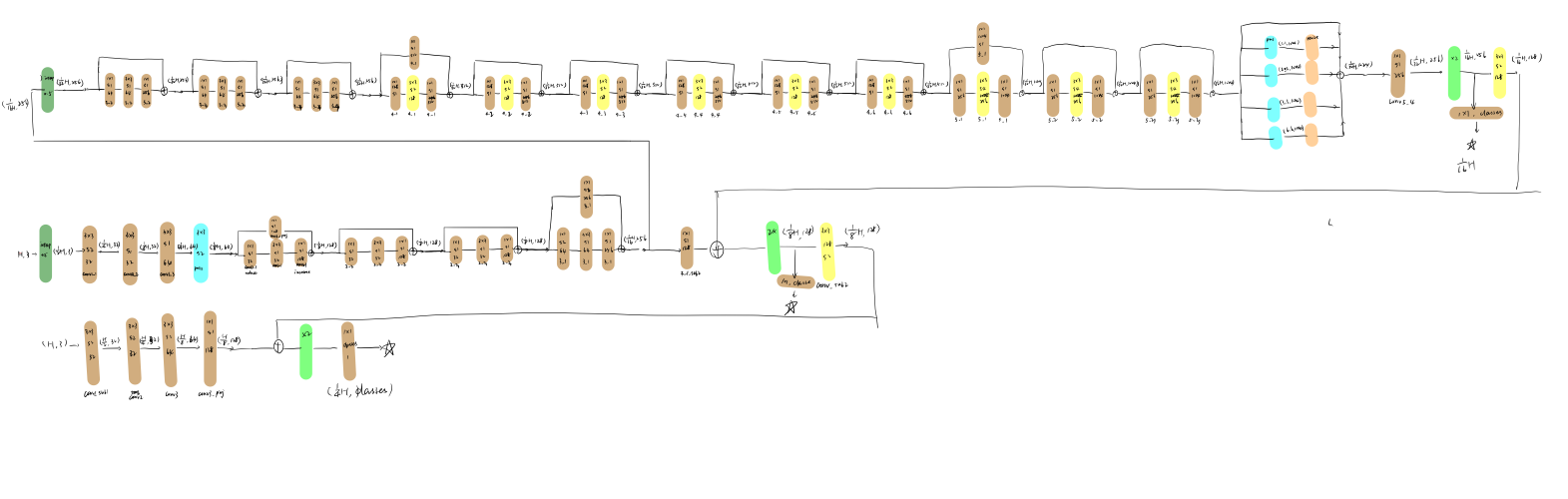
手绘网络结构细节图
SPNet的网络结构如图所示:
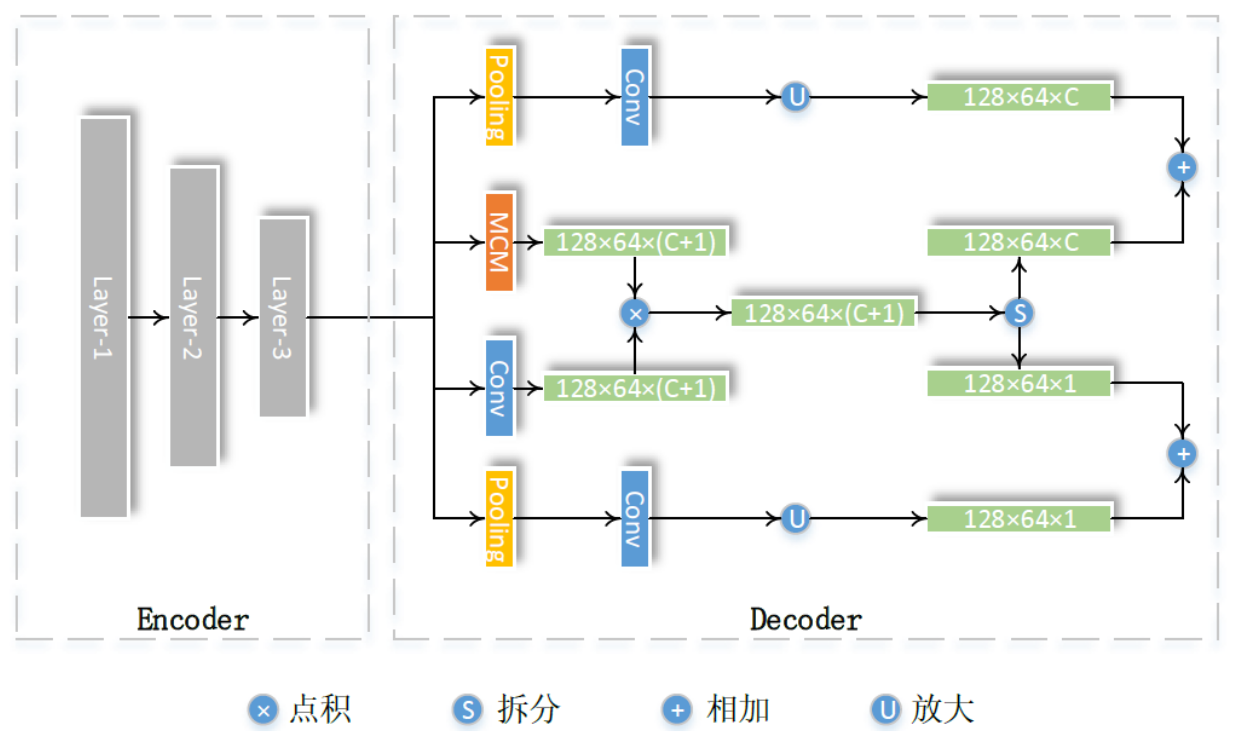
网络整体上也是一个Encoder-Decoder结构。
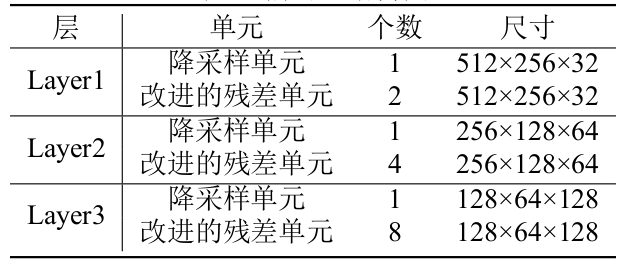
Encoder部分由降采样单元和改进的残差单元组成。
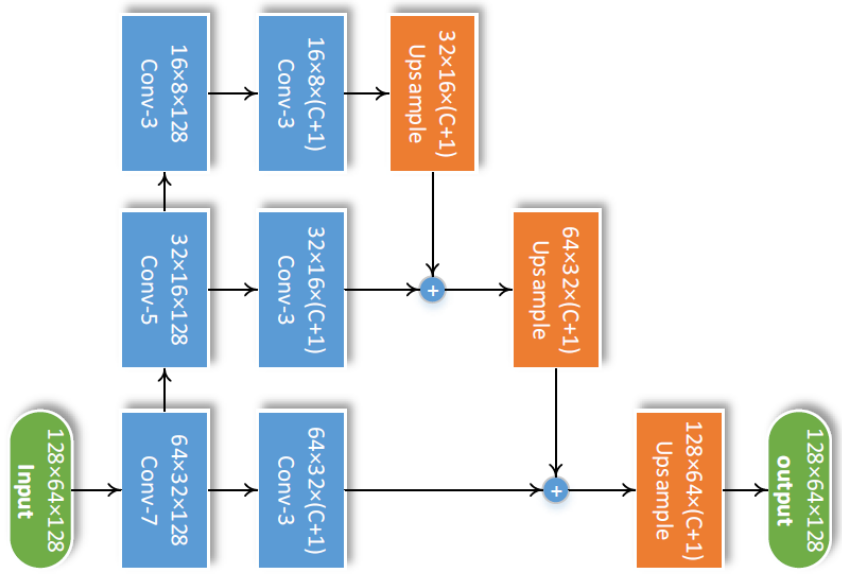
对于残差单元改进有以下几点:
- 首先将输入在通道维度上一分为二,分别进入两个不同的卷积分支,实现输入通道$N_{in}$和输出通道的减小$N_{out}$的减小。
- 其次,将卷积分支上$3\times3$的卷积拆分成$3\times1$和$1\times3$卷积核,减小了卷积核的大小。
- 最后,级联两个分支的输出,恢复了通道数,并与原始输入直接相加,维持残差结构。由于通道拆分会导致不同分支之间的通道无法进行特征的组合,因此在单元最后增加一个通道的重组,重新分布通道的顺序,保证通道间特征的交流。
Decoder部分由两部分组成,第一部分是中间两个分支,用于捕捉语义信息与深度信息的共同点。两个分支分别是多尺度卷积模块(Multi-scale Convolution Module)分支和普通的卷积运算分支。两个分支输出的通道个数均为$C+1$,其中$C$个通道为语义通道,$1$个通道为深度通道。 第二部分是旁路的两个分支,用于捕捉语义和深度各自独特的信息。多尺度卷积模块如下图所示:
模型的效果就是介绍开始贴的图示。
-
环境:我自己使用的环境是
- Ubuntu 16.4
- Pytorch 1.0
- cuda 10
- 显卡 2080ti
-
数据准备:数据集到Cityscapes上下载,其中深度数据集需要额外发邮件申请,没法直接下载。
-
配置文件:修改配置文件
config/spnet-cityscapes.yml中的内容,将数据集位置改为自己数据集的路径。 -
执行
train.py即可
- 修改配置文件
config/spnet-cityscapes.yml中test部分模型的保存位置 - 将图像放到
inputs文件夹中 - 执行
demo.py文件