Chem-FINESE: Validating Fine-Grained Few-shot Entity Extraction through Text Reconstruction
Accepted by Findings of the Association for Computational Linguistics: EACL 2024
Table of Contents
=================
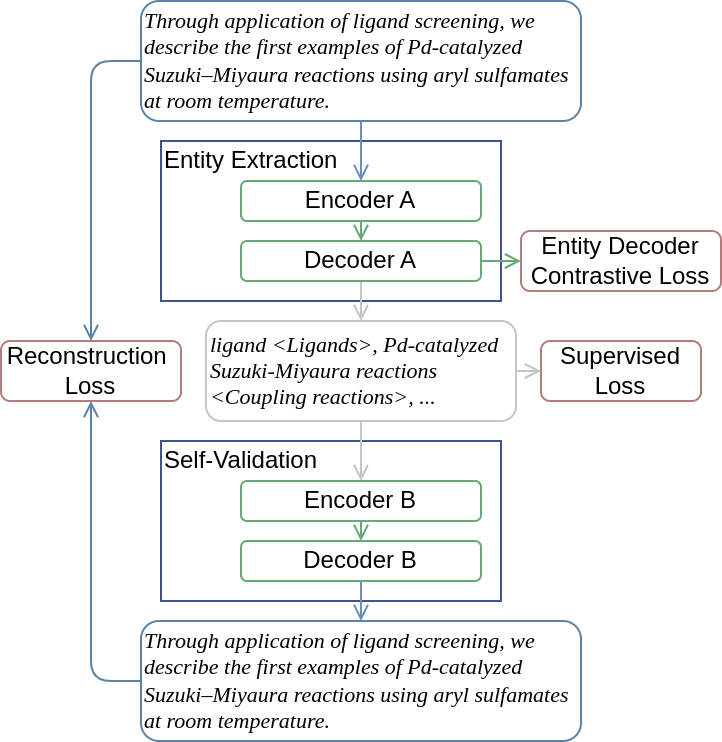
-
Python 3.10.12
-
Ubuntu 22.04
To set up the environment for this repository, please follow the steps below:
Step 1: Create a Python environment (optional) If you wish to use a specific Python environment, you can create one using the following:
conda create -n pyt1.12 python=3.10.12Step 2: Install PyTorch with CUDA (optional) If you want to use PyTorch with CUDA support, you can install it using the following:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidiaStep 3: Install Python dependencies To install the required Python dependencies, run the following command:
pip install -r requirements.txtStep 4: Download NLTK data
python -m nltk.downloader punktThis repositiory contains two chemical few-shot fine-grained entity extraction dataset based on ChemNER and CHEMET.
We choose the values annotation folder contains annotation guidelines and fine-grained entity ontology.
CHEMET folder contains full CHEMET dataset and its few-shot subsets. Each folder contains four files: train.json, valid.json, test.json, and types.json.
ChemNER+ folder contains full ChemNER+ dataset and its few-shot subsets. Each folder contains four files: train.json, valid.json, test.json, and types.json.
train.json, valid.json, test.json are used for training, validation, and testing respectively. Each file contains multiple lines. Each line represent an instance. The schema for each instance is listed below:
{
"coupling": # sentence id
"sent_tokens": # tokens in the sentence
"entities": # ground truth entities in the sentence, which is a list containing entity type, text, start position, end position
"f1": # semantic similarity between entity list and input
}Modify file path under pretrain.sh and finetune_cl.sh.
You can fisrt pretrain your self-validation model by running pretrain.sh in this folder.
bash pretrain.sh You can then finetune your model by running finetune_cl.sh in this folder.
bash finetune_cl.sh You can then test your model by running test_cl.sh in this folder.
bash test_cl.sh @inproceedings{wang-etal-2024-chem,
title = "Chem-{FINESE}: Validating Fine-Grained Few-shot Entity Extraction through Text Reconstruction",
author = "Wang, Qingyun and
Zhang, Zixuan and
Li, Hongxiang and
Liu, Xuan and
Han, Jiawei and
Zhao, Huimin and
Ji, Heng",
editor = "Graham, Yvette and
Purver, Matthew",
booktitle = "Findings of the Association for Computational Linguistics: EACL 2024",
month = mar,
year = "2024",
address = "St. Julian{'}s, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-eacl.1",
pages = "1--16",
}