To install the Docker image, you must follow the next Platzi Class
All the legal sources used on this projet were extracted from the site of Bogota's Town Hall. Then, by an EDA that you can look on the jupyter notebook etl_legal_sources and recreate with the docker image up.
The notebook of tunning_sandbox you can take a quick look of the behaviour of the four queries that we can use. Even though ElasticSearch has a lot of query types, for all flavours. In our case that is lacking of numbers, and that is required really specific text on the same order, must of the queries don't retrieve a big change that pays the invested time. Other case is the embeddings model, that does not only give us a big challenge, but a best response once is running.
A client requires the construction of an application that works as a search engine on the political constitution of Colombia (available online) in which, through this, the ordinary citizen can consult articles related to a compound word or by tags, that is, if the client wanted to search for "human rights" or "rights" the filter could be precise and show information from the text that is related to its tags. For now, he would like a team of developers to advise him on the most appropriate form of medium for use, be it a responsive web application or a mobile app, this decision will be at the discretion of the proposal that will be presented in the first deliverable to the central team.
- Pandas
- Numpy
- re
Before jumping to the exploration stage, we need to perform basic data pre-processing steps like null value imputation and removal of unwanted data. So, let’s start by importing libraries and reading our dataset. The dataset contains 439 rows and 3 columns. But these columns are in dictionary format and we need title, chapter and article information. Therefore we are transforming our Dataset in order to extract relevant data.

- WordCloud
We will start by looking at the common words present in the articles for each title. For this, we will use the document term matrix created earlier with word clouds for plotting these words. Word clouds are the visual representations of the frequency of different words present in a document. It gives importance to the more frequent words which are bigger in size compared to other less frequent words.

- TensorFlow
- TensorFlow Hub
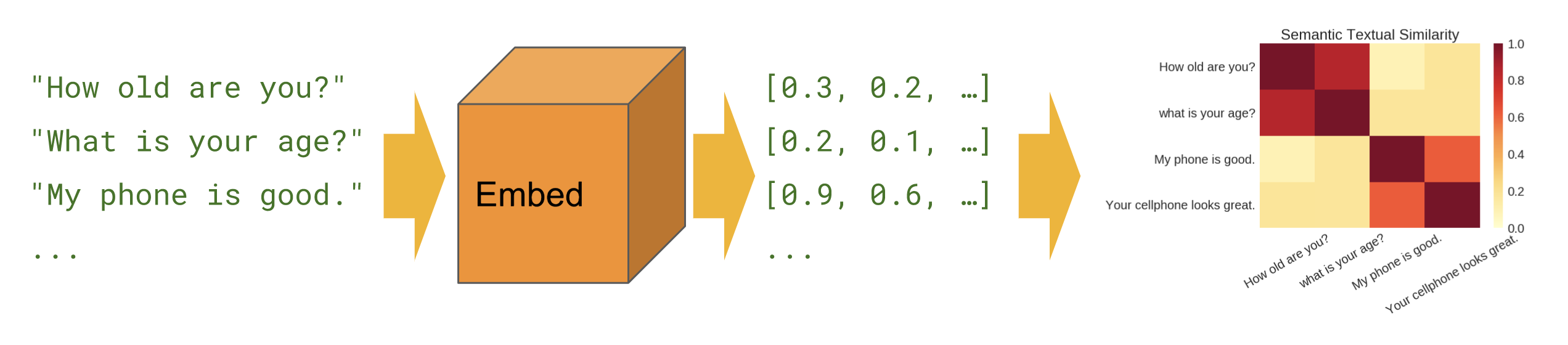
The Universal Sentence Encoder encodes text into high-dimensional vectors that can be used for text classification, semantic similarity, clustering and other natural language tasks.
The model is trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. It is trained on a variety of data sources and a variety of tasks with the aim of dynamically accommodating a wide variety of natural language understanding tasks. The input is variable length Spanish text and the output is a 512 dimensional vector. We apply this model to the STS benchmark for semantic similarity, and the results can be seen in the example notebook made available. The universal-sentence-encoder model is trained with a deep averaging network (DAN) encoder.
- TensorFlow Text
- Numpy
Semantic similarity is a measure of the degree to which two pieces of text carry the same meaning. This is broadly useful in obtaining good coverage over the numerous ways that a thought can be expressed using language without needing to manually enumerate them.