blocksync: Some performance improvements on top of #3957 #3985
Conversation
|
Fixup switches from searching |
|
Performance remains the same for block sync, if not better:
|

1d60831
to
92ab81a
Compare
|
Hmm, my response to this got lost. Anyway, I can't find any requirement on json.org or jsonrpc.org that a JSON RPC end with '\n'. Even if it said that, my ignorance suggests it's dangerous to rely on it. We can, however, insist that we have just read a '}'. In the normal case, this is harmless, but in the case here "huge token", it's an effective hack. Needs a huge comment though: /* Our JSON parser is pretty good at incremental parsing, but `getrawblock` gives a giant 2MB token, which forces it to re-parse
every time until we have all of it. However, we can't complete a JSON object without a '}', so we do a cheaper check here. */ |
That is because the JSON-RPC spec is (mostly) transport agnostic, and the usual suspects (HTTP/HTTPS/HTTP2.0) provide built-in framing support, i.e., either the header contains the number of bytes to read, or the connection is closed after submitting the payload. In our case we don't have that which required us to come up with a different end-of-message marker, and so we did with a very inefficient end-of-json = end-of-message which requires either re-parsing the message on every increment, or having a resumable parser like I'm pretty sure that requiring a newline after the message is safe, even if not explicitly documented right now, but happy to start enforcing that only in conjunction with a
I went ahead and implemented the single
So it seems like checking for I added the details on why we filter to the comment, and if this looks good I can squash it all into place. |

lightningd/plugin.c
Outdated
| * `getrawblock` gives a giant 2MB token, which forces it to re-parse | ||
| * every time until we have all of it. However, we can't complete a | ||
| * JSON object without a '}', so we do a cheaper check here. | ||
| */ | ||
| have_full = memmem(plugin->buffer + plugin->used - offset, | ||
| plugin->len_read + offset, "}", 1); |
There was a problem hiding this comment.
This can be memchr :)
And we no longer need offset. I'll add a fixup (and seems like a file needs regen, too...)
|
Changed to a straight memchr, squashed fixups and rebased on (Travis-fixed) master... |
|
Ack e45b22d |
We were using `tal_fmt` to truncate off the last byte of the response (newline), which required an allocation, a call to `vsnprintf` and a copy of the block contents. This being >2MB in size on mainnet was rather expensive. We now just signal the end of the string by overwriting the trailing newline, and stealing directly onto the result.
We're not going to mutate transactions in a block, so computing the txids every time we need them is a waste, let's compute them upfront and use them afterwards.
PR ElementsProject#3957 improved performance considerably, however we still look over the entire message for the message separator. If instead we just look in the incrementally read data, we remove the quadratic behavior for large messages. This is safe since we then loop over the messages which would drain any message separator from the buffer before we attempt the next read. Changelog-Fixed: bcli: Significant speedups for block synchronization
|
ACK 64f2dcb |
Inspired by #3957 I took some time to benchmark and improve the block sync
time as well. It's not as impressive as the 30x that #3957 achieved but it has
some incremental gains. The benchmarks use the following code, with a local
bitcoindand the defaultbclibackend:The following are the performance gains achieved by individual commits (and compared to #3957):
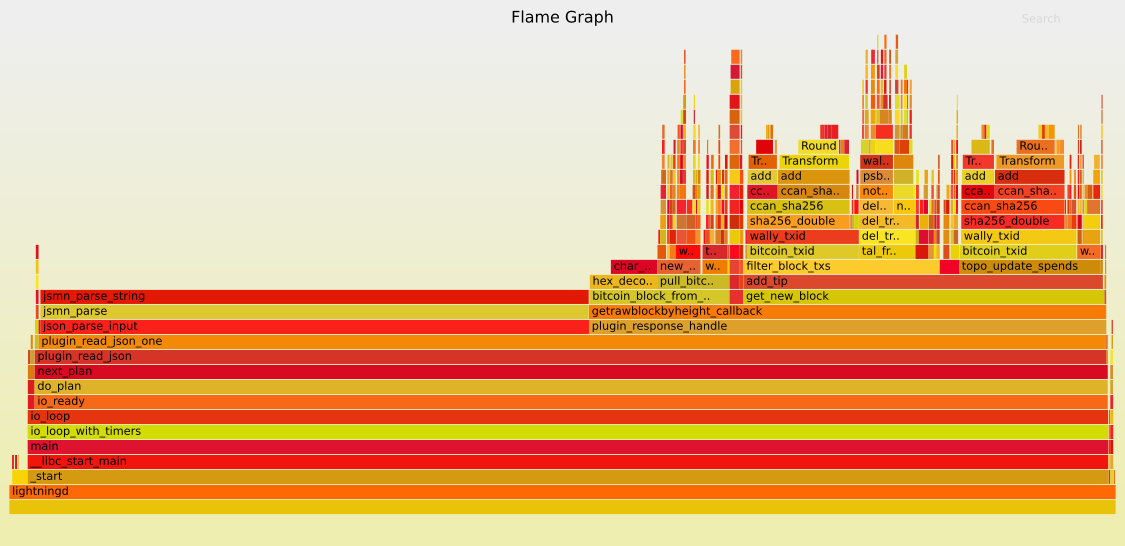
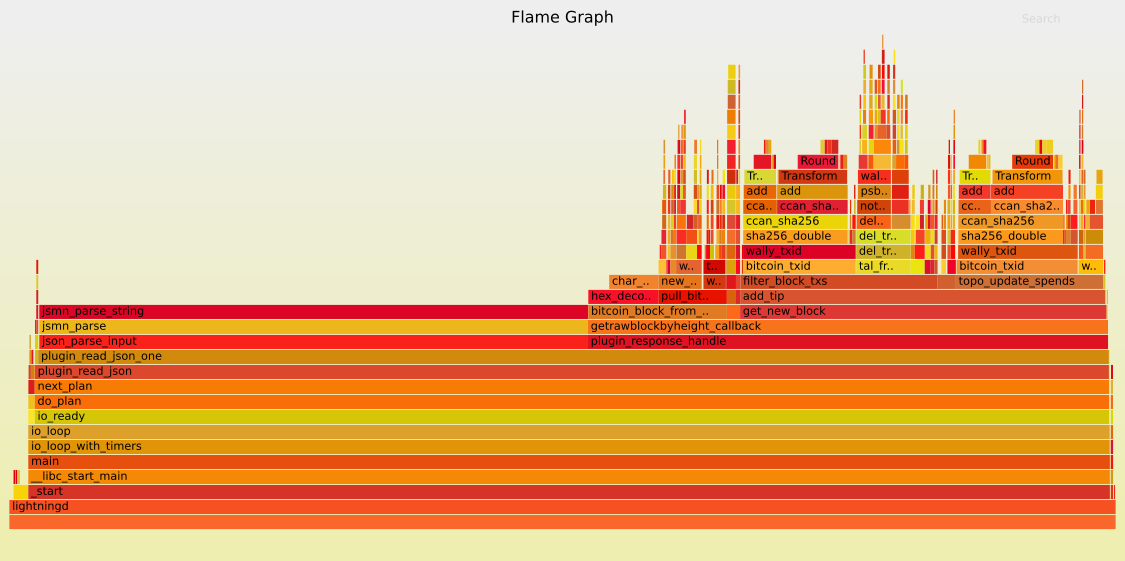
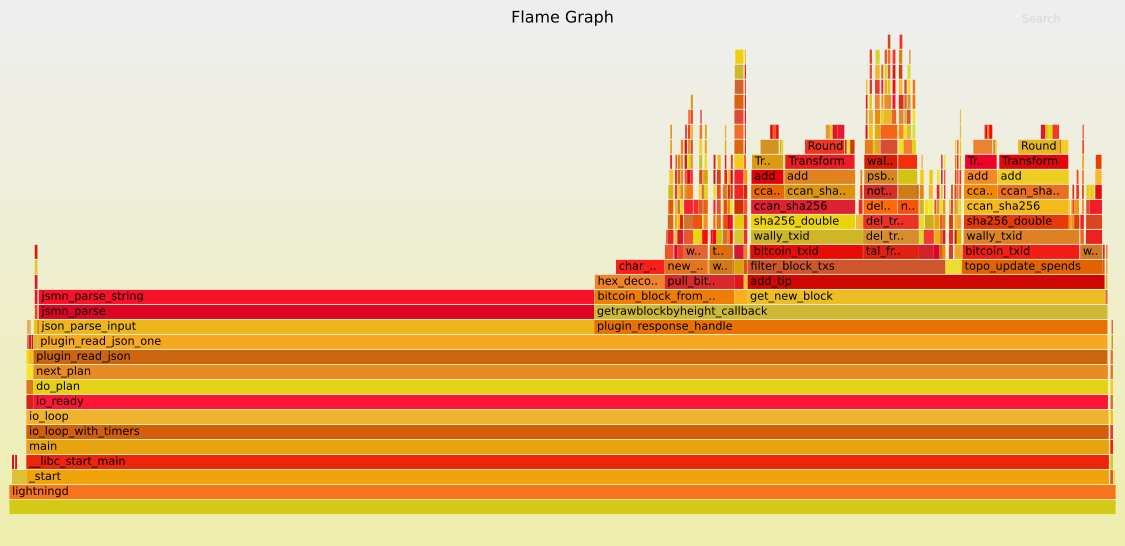
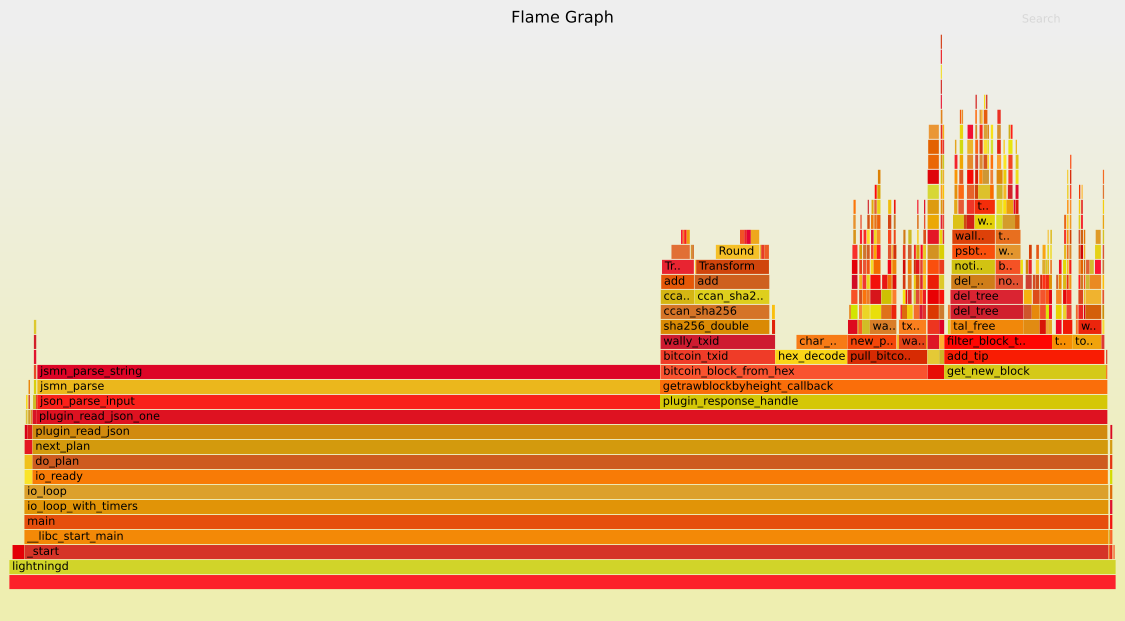
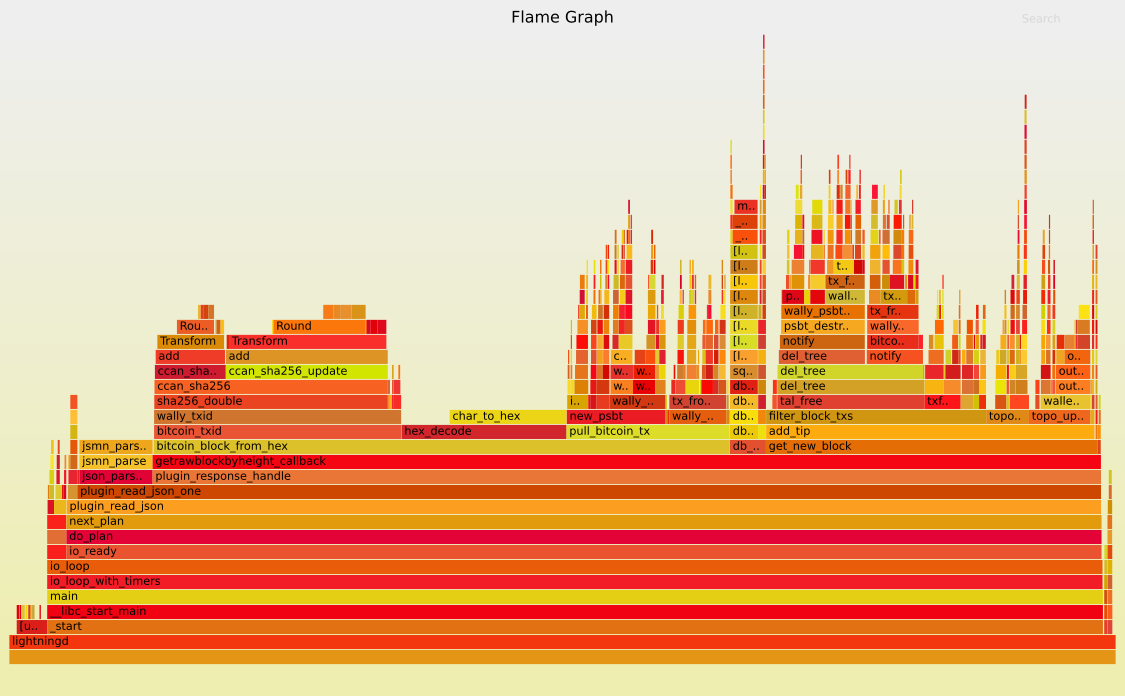
And here are the flamegraphs that I used to guide the changes: