Understanding the data
elsapy is primarily designed to give access to data from Scopus. The Scopus data model is designed around the notion that scientific articles are written by authors that are affiliated with institutions. Visually and rather simplistically, this relational model can be represented like this:
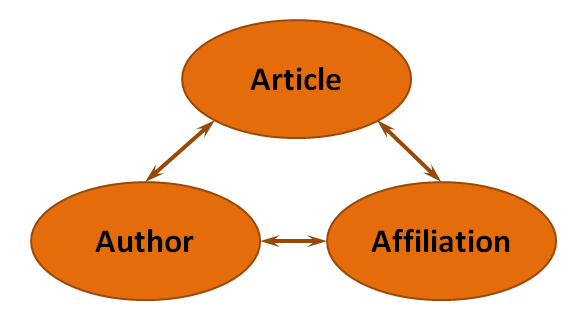
In Scopus, each of these entities has its own type of page - for example:
- Document page - e.g. https://www.scopus.com/inward/record.uri?partnerID=HzOxMe3b&scp=84872135457
- Author profile - e.g. https://www.scopus.com/authid/detail.uri?authorId=7202909704
- Affiliation profile - e.g. https://www.scopus.com/affil/profile.uri?afid=60002573
As you can see on those pages, each of these entities has a lot of metadata associated with it (e.g. the keywords of an article, the publication range of an author, the address of an institution), and some calculated metrics (such as h-index, citation count, publication count, etc.). And from those pages, there are also links that point to other entities, to lists of documents associated with that entity, and so on.
Elsevier's APIs are designed in a similar way. Essentially, each document or author or affiliation not only has its own page on www.scopus.com, but also its own JSON and XML representation through api.elsevier.com (think of it as a machine-readable version of the human-readable page on www.scopus.com). Here are the API URLs for those same three examples:
- Document URL - e.g. http://api.elsevier.com/content/abstract/SCOPUS_ID/84872135457
- Author profile - e.g. http://api.elsevier.com/content/author/AUTHOR_ID/7202909704
- Affiliation profile - e.g. http://api.elsevier.com/content/affiliation/AFFILIATION_ID/60002573
And just like the pages on www.scopus.com, those JSON/XML representations contain a lot of data about the entity in question - and also contain URLs (i.e. links) to related entities and list of documents.
In elsapy, this data model is expressed through classes: there is a document class, an author class, and an affiliation class. You can create an instance of each class using the identifier - or even API URL - of that entity, e.g.:
myAuth = ElsAuthor(uri = 'http://api.elsevier.com/content/author/AUTHOR_ID/7202909704')
This creates an author object in our machine's memory with that API URL. But at this point, this object doesn't actually contain any of the data for that author - it only has the URL. If we want to populate the author object with all the data for that author, we will need to tell the object to 'read' itself, using an client connection to the APIs we instantiated earlier (called 'myCl'):
myAuth.read(myCl)
This causes the author object to make a request to http://api.elsevier.com/content/author/AUTHOR_ID/7202909704, to parse the data it finds at that URL, and to store it internally. We can access this data by calling the author object's .data property:
myAuth.data
This will display the full data set as a Python dictionary. As with any Python dictionary, we can ask for its keys:
myAuth.data.keys()
We can then use these keys to drill deeper into the data, e.g.:
myAuth.data['affiliation-history']
This displays this author's affiliation history - which, conveniently, includes URLs that we can use to instantiate affiliation objects, in the same way we just instantiated this author object. As you explore the data stored in an object, you will see more URLs that allow you to 'spin off' new objects in your code.
For convenience, some elements from an object's .data property are available as properties in and of themselves. For example, author objects have the author's full name as a separate property:
myAuth.full_name
Author and affiliation objects have another feature: we can tell them to retrieve and store a list of the documents associated with them. For example (again using the previously established 'myCl' connection):
myAuth.read_docs(myCl)
This causes the author object to retrieve (using multiple requests, if need be) and internally store the list of documents written by the author. After this, we can access this list using its .doc_list property:
myAuth.doc_list
Keep in mind, though, that some authors and pretty much all affiliations have a LOT of documents associated with them - so it can take an author or affiliation object a long time to read all those documents, and the size of the object in your machine's memory can increase considerably as a result.
Through the ElsClient class, the elsapy module can be used to execute requests to any of the APIs documented here. This includes requests to retrieve data for other entities than documents, authors and affiliations from Scopus (e.g. full-text articles from ScienceDirect). You will have to construct the request URLs for those yourself; elsapy does not contain classes yet that create objects that can do that themselves.