The Juniper Team of the Erdős Institute has utilized machine learning algorithms to predict the dominant forest cover types from ecological and geological information about a 30m x 30m patch in the Roosevelt National Forest of northern Colorado. In doing so, our project addresses two primary goals:
- Generating an optimal algorithm to predict the cover type based on US Forest Service Information System data.
- Visualizing the “shape” of the dataset and finding the most essential variables in clustering. We wished to communicate relationships between features to a wide audience of users.
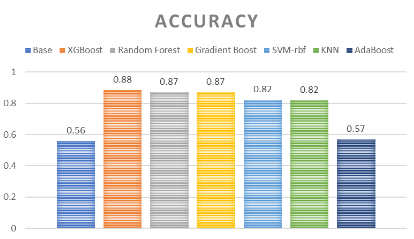
We have evaluated the success of our models using the overall accuracies in predicting each dominant forest cover type. After testing six different algorithms, we found our XGBoost algorithms with parameter tunings had the highest accuracy, correctly predicting 88% of our data points.
This project at the Erdős Institute Fall 2022 Bootcamp was voted by industry and alumni partners in the Top 5 out of 30 submitted projects. The link to the presentation is available here.
- Chris Chia
- Moeka Ono
The dataset of this project is available on Kaggle. The original training dataset includes 15,120 observations with 7 dominant forest cover types, including 1) Spruce/Fir, 2) Lodgepole pine, 3) ponderosa pine, 4) cottonwood/willow, 5) Aspen, 6) Douglass-fir, and 7) Krummholz. The dataset has 12 features containing both continuous and categorical data. The categorical features were already one hot coded, leading to a total of 53 independent variables. The 7 types of forest covers were balanced equally in the dataset. In our project, we split the original training set and used 90% as our training set and the remaining 10% as a validation data set.
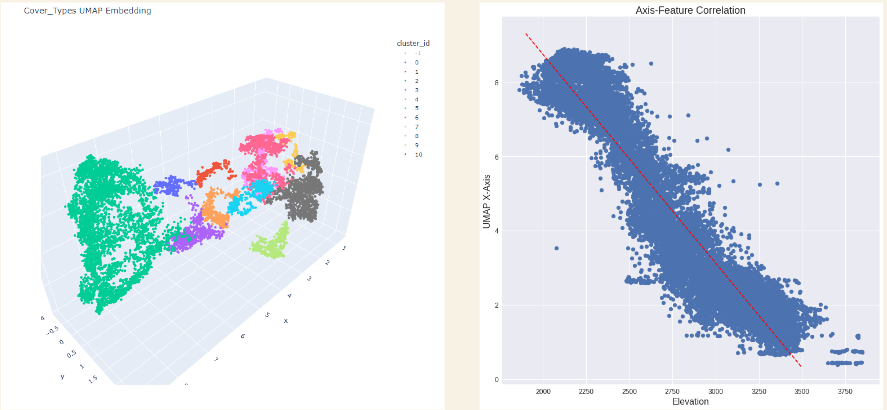
Topology has been used successfully with other projects (eg. COVID-19 data) to find hidden relationships between variables. We’ve also created images that clearly show that elevation is the feature that distinguishes clusters in our data set the most. These images highlight the most important type of data to collect in regards to cover type identification.
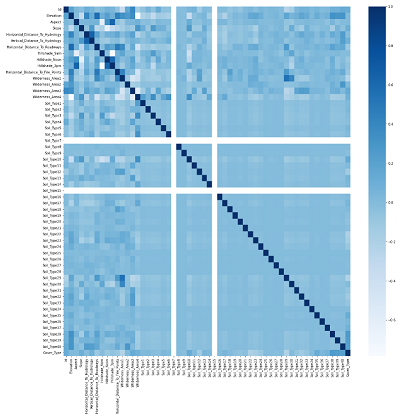
Soil_type7 and Soil_type15 don't have any correlations with Cover_Type, so we removed these variables from the training dataset.
We have deployed a base model as multi logistic regression and 6 different ML models as belows.
- Ensemble Learning
- Random forest
- XGboost
- Gradient boosting
- Adaboost
- KNN (K-nearest neighbors)
- SVM (support vector machines)
Overall, our three ensemble learning algorithms (XGBoost, Random Forest, and Gradient Boosting) did better in predicting our dataset. XGBoost with parameter tuning had the highest overall accuracy of 0.88, which improved the accuracy by 22% compared with the base multi-logistic regression model. Adaboost, on the other hand, performed poorly in predicting the forest cover type. KNN and SVM achieved 82% of accuracy, however, KNN might particularly be overfitted since k=1 was the optimal estimator based on the result of the cross-validations.
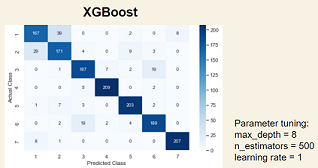
When focusing on the predicted forest cover class, our models struggled with distinguishing between type 1: Spruce/Fir, and type 2: Lodgepole Pine. The biggest difference between these two types seems to be elevation, but other features seem to be very similar, likely resulting in difficulty in identifying these two. In contrast, the precision and recall scores of type 7 (Krummholz) were almost always the highest in any model. It may be because Krummholz is not a specific tree species but a unique formation of trees under exposure to fierce, freezing winds.
In conclusion, our machine learning algorithm gives accurate predictions for those that require an assessment of the location of cover types just from knowing certain basic features such as elevation, slope, soil types, and other features that can be found from satellite imagery rather than requiring data gatherers.
- Implementing time
- It would allow us to detect the changes over time and to improve prediction results.
- Even better accuracy in distinguishing Spruce/Fir and Lodgepole Pine cover types
- Our model struggled the most with these two cover types, likely because the features, except for elevation, seem to be very similar. It may be essential to invest in improving the accuracy of these two species since the former is fire-intolerant, and the latter is fire-tolerant.
- More parameter tuning on the TDA model to separate into 7 clusters for each cover type.