Create environment:
conda env create -f environment.yaml
conda activate ddpm
Download the Landscape Dataset from Kaggle as archive.zip or the Celeba dataset (aligned & cropped) as img_align_celeba.zip.
$ mkdir -p landscape_img_folder/train
$ unzip archive.zip -d landscape_img_folder/train/
For my convenience I set up the buckets and download datasets, checkpoints etc. by running:
source ./setup.sh
Also trained it for the celeba dataset. Download three example checkpoints (epoch 30, 80, 490) from the bucket (or /ddpm/models_celeba/). Then sample from these three checkpoints (saved as models/ckpt_epoch[30, 80, 490]_ddpm.pt):
python ddpm_accelerate.py --ckpt /mnt/task_runtime/ddpm/models/ckpt_epoch490.pt --ckpt_sampling


Generated the gif by ffmpeg -framerate 5 -i results/denoised/denoised_%3d.jpg ddpm_slow.gif
Use multi-GPU training script using 🤗 Accelerate .
accelerate launch ddpm_accelerate.py
Note: Running the same script as python ddpm_acclerate.py will fall back to single GPU mode (no effect of accelerate). Therefore, the same script can be directly used for single GPU tasks like sampling/inference or debugging. So I decided to retire the single GPU script ddpm.py.
Below images show noising of images used in training (see Details on Notation for more on the notation)
-
Noised samples : from
$q(\mathbf{x}_t |\mathbf{x}_0)$ -
Original samples : from
$q(\mathbf{x}_0)$
| Noised samples | Original |
|---|---|
 |
 |
Fig. For batch B=12, illustrates the noising process for
Noising (or diffusion) is defined as a Markovian process over states
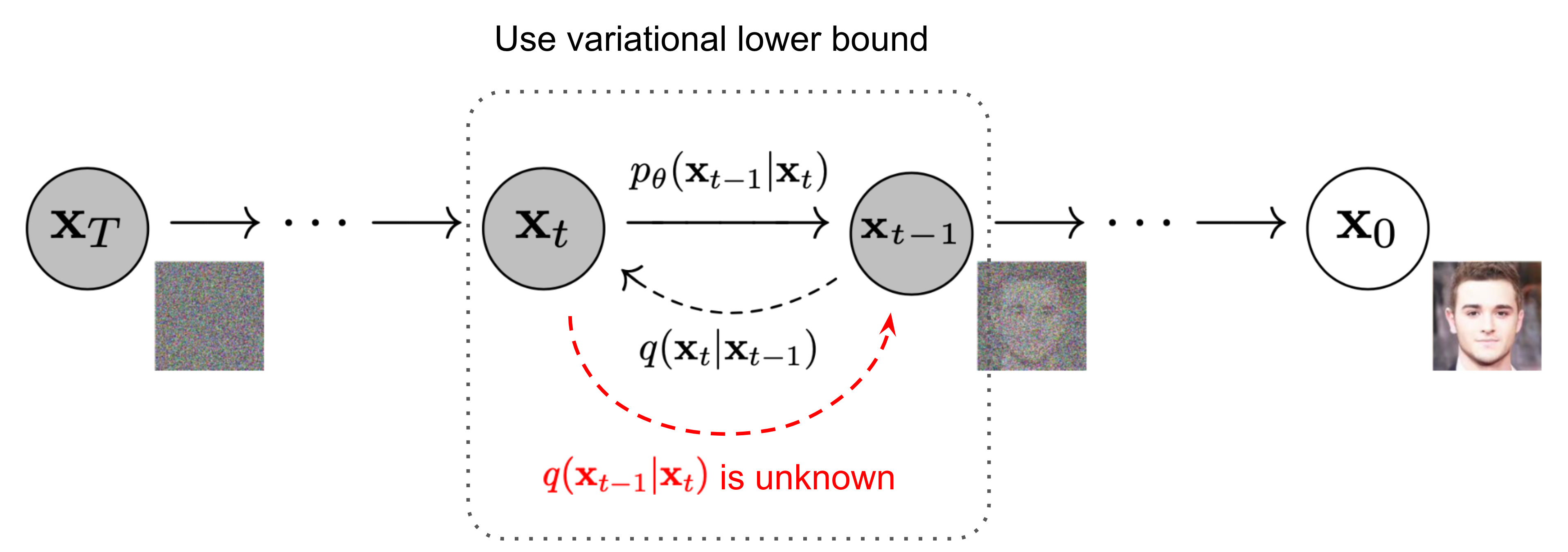
Then the noising process
In training, U-Net is trained to estimate the noise (i.e. the mean of

Fig. For given
[1] Started the code based on outlier's Diffusion-Models-pytorch repo.
[2] Also used his youtube tutorial [Diffusion Models | Pytorch Implementation].
[3] Referring and using Phil Wang's (lucidrains) denoising-diffusion-pytorch repo.
[4] Lillian Weng's blog (lil'log) https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
[5] Ho et al. 2020 "Denoising Diffusion Probabilistic Models" paper with original implementation and its pytorch reimplementation by Patrick Esser.
[6] Referred to CompVis' Latent Diffusion Models repo and paper Rombach et al. 2022 "High-Resolution Image Synthesis with Latent Diffusion Models"
[7] HuggingFace's Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX. For quickly testing DDPM here
[8] MMagic from OpenMMLab with nice resource on Stable Diffusion which mainly builds on HuggingFace's diffusers.