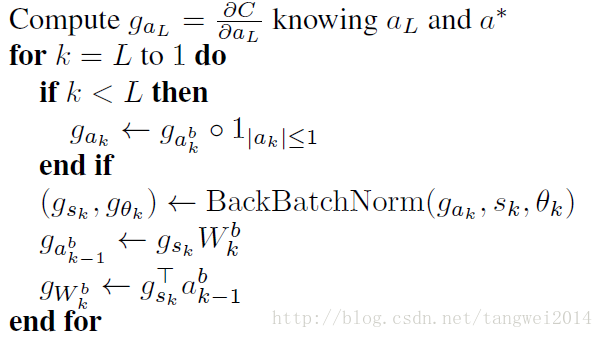论文 BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1.
It is divided in two subrepositories:
-
训练 Train-time enables the reproduction of the benchmark results reported in the article
-
运行 Run-time demonstrates the XNOR and baseline GPU kernels described in the article
首先点燃战火的是Matthieu Courbariaux,他来自深度学习巨头之一的Yoshua Bengio领导的蒙特利尔大学的研究组。 他们的文章于2015年11月出现在arxiv.org上。 与此前二值神经网络的实验不同,Matthieu只关心系数的二值化, 并采取了一种混和的策略, 构建了一个混有单精度与二值的神经网络BinaryConnect: 当网络被用来学习时,系数是单精度的,因此不会受量化噪声影响; 而当被使用时,系数从单精度的概率抽样变为二值,从而获得加速的好处。 这一方法在街拍门牌号码数据集(SVHN)上石破天惊地达到超越单精度神经网络的预测准确率, 同时超越了人类水平,打破了此前对二值网络的一般印象,并奠定了之后一系列工作的基础。 然而由于只有系数被二值化,Matthieu的BinaryConnect只能消减乘法运算, 在CPU和GPU上一般只有2倍的理论加速比, 但在FPGA甚至ASIC这样的专用硬件上则有更大潜力。 一石激起千层浪。Matthieu组很快发现自己的工作引起的兴趣超乎想像。 事实上,3个月后,Itay Hubara在以色列理工的研究组甚至比Matthieu组, 早了一天在arxiv.org上发表了同时实现系数和中间结果二值化,并在SVHN上达到了可观预测准确率的二值网络。 由于双方的工作太过相似,三个星期后,也就是2016年2月29日, 双方的论文被合并后以Matthieu与Itay并列一作的方式再次发表到arxiv.org上。 这个同时实现系数和中间结果二值化的网络被命名为BinaryNet。 由于达成了中间结果的二值化, BinaryNet的一个样例实现无需额外硬件,在现有的GPU上即达成了7倍加速。
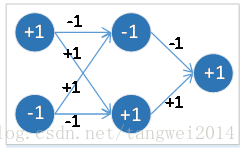
二值化神经网络,是指在浮点型神经网络的基础上,
将其权重矩阵中权重值(线段上) 和 各个 激活函数值(圆圈内) 同时进行二值化得到的神经网络。
1. 一个是存储量减少,一个权重使用 1bit 就可以,而原来的浮点数需要32bits。
2. 运算量减少, 原先浮点数的乘法运算,可以变成 二进制位的异或运算。
论文 Binarized Neural Networks BNN
1. 阈值二值化,确定性(sign()函数)
x = +1, x>0
-1, 其他
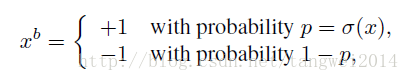
2. 概率二值化随机(基于概率)两种二值化方式。
x = +1, p = sigmod(x) ,
-1, 1-p
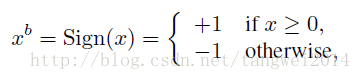

其实就是最低值0.最大值1,中间是 0.5*x+0.5的斜线段
第二种方法虽然看起来比第一种更合理,但是在实现时却有一个问题,
那就是每次生成随机数会非常耗时,所以一般使用第一种方法.
对权重值W 和 激活函数值a 进行二值化
Wk = Binary(Wb) // 权重二值化
Sk = ak-1 * Wb // 计算神经元输出
ak = BN(Sk, Ck) // BN 方式进行激活
ak = Binary(ak) // 激活函数值 二值化
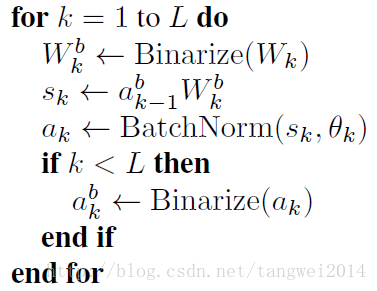
计算浮点型权重值对应的梯度和浮点型激活函数值对应的残差
虽然BNN的参数和各层的激活值是二值化的,但由于两个原因,
导致梯度不得不用较高精度的实数而不是二值进行存储。
两个原因如下:
1. 梯度的值的量级很小
2. 梯度具有累加效果,即梯度都带有一定的噪音,而噪音一般认为是服从正态分布的,
所以,多次累加梯度才能把噪音平均消耗掉。
另一方面,二值化相当于给权重和激活值添加了噪声,而这样的噪声具有正则化作用,可以防止模型过拟合。
所以,二值化也可以被看做是Dropout的一种变形,
Dropout是将激活值的一般变成0,从而造成一定的稀疏性,
而二值化则是将另一半变成1,从而可以看做是进一步的dropout。
使用sign函数时,
对决定化方式中的Sign函数进行松弛化,即前传中是:
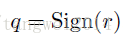
sign函数不可导,
使用直通估计(straight-through estimator)(即将误差直接传递到下一层):
反传中在已知q的梯度,对r求梯度时,Sign函数松弛为:
gr=gq1|r|≤1
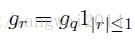
其中1|r|<=1的计算公式就是 Htanh= max(-1, min(1,x))
其实就是上限是1,下限是-1,中间是 y=x的斜线段
即当r的绝对值小于等于1时,r的梯度等于q的梯度,否则r的梯度为0。
直接使用决定式的二值化函数得到二值化的激活值。
对于权重,
在进行参数更新时,要时时刻刻把超出[-1,1]的部分给裁剪了。即权重参数始终是[-1,1]之间的实数。
在使用参数是,要将参数进行二值化。
最后求得各层浮点型权重值对应的梯度和浮点型激活函数值对应的残差,
然后用SGD方法或者其他梯度更新方法对浮点型的权重值进行更新,
以此不断的进行迭代,直到loss不再继续下降。
BNN中同时介绍了基于移位(而非乘法)的BatchNormailze和AdaMax算法。
实验结果:
在MNIST,SVHN和CIFAR-10小数据集上几乎达到了顶尖的水平。
在ImageNet在使用AlexNet架构时有较大差距(在XNOR-Net中的实验Δ=29.8%)
在GPU上有7倍加速.