Architectural Overview
- Adaptive Alerting in context
- High-level Adaptive Alerting architecture
- Mid-level Adaptive Alerting architecture
- Code modules
This page describes the Adaptive Alerting (AA) architecture. We'll start at the highest level and dig deeper as we progress.
Adaptive Alerting is one stage of a larger alert processing pipeline. The main goal for AA is to help drive down the Mean Time To Detect (MTTD). It does this by listening to streaming metric data, identifying candidate anomalies, validating them to avoid false positives and finally passing them along to downstream enrichment and response systems.
Here's one example of the sort of pipeline we have in mind. (Right-click the image and open it in a new tab to see a larger version.)
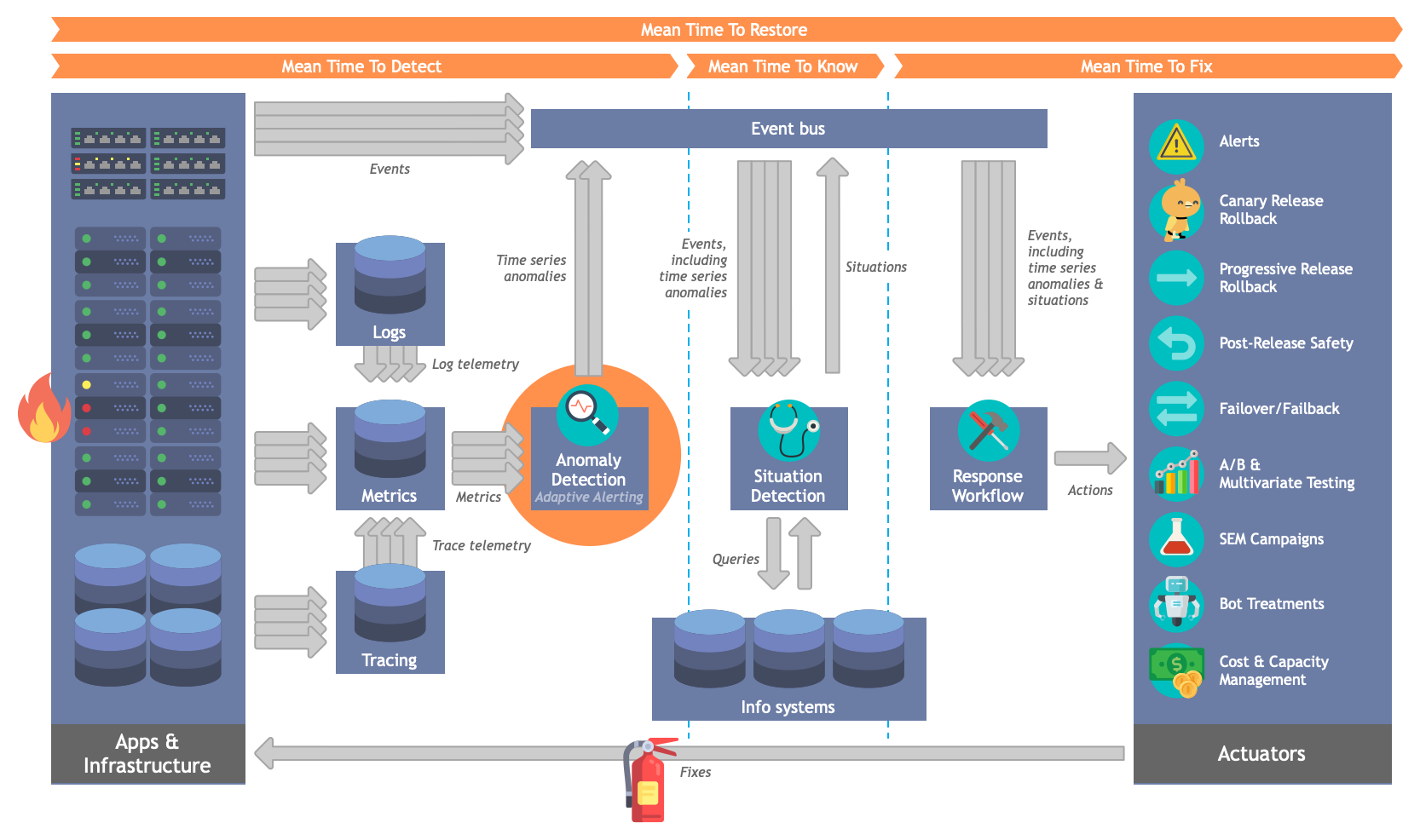
The specific example above is Expedia-specific, but the concepts involved are more general.
This isn't the only possible pipeline. For example you may not have an automated response system. This just gives you an idea as to where AA fits into the big picture.
Now let's look at AA itself.

At the highest level, Adaptive Alerting comprises three key concerns:
- An Anomaly Engine, which the runtime that accepts incoming metric streams from arbitrary time series metric source systems; classifies individual metric points as normal, weak anomalies or strong anomalies; and then passes them along to consumer systems such as alert management systems (for end users) and automated response systems (automated workflows to remediate problems);
- a Model Building system that trains (some of) the models underlying the anomaly detectors; and
- a Model Selection and Autotuning system that automatically picks the best model and tuning for a given metric.
Let's take a look at the next level down.

The diagram above offers additional detail. Let's look at the different systems in turn.
As we noted above, the Anomaly Detection system's job is to process incoming metric streams, decide which points represent anomalies and pass that information on to downstream systems (end user alerting and automated response). But now we can see some key pieces:
- A metric router (not shown, but part of Anomaly Detection), which determines for any given metric point which anomaly detector to send it to. Basically we look at which metric the point comes from, and then look up a metric-to-model mapping that lives in the Model Service. See Anomaly Detection for more details.
- A set of anomaly detectors, whose job is to decide quickly for a given point whether it looks like an anomaly. Anomaly detectors generally do this by comparing the observed time series value to a prediction produced by some underlying time series model. If the observation is "too far" away from the prediction, the anomaly detector classifies the point either as a weak anomaly (the point is somewhat far from the prediction, and warrants further investigation) or else a strong anomaly (the point is quite far away from what the model predicted). See Anomaly Detection for more details.
- A set of anomaly validators. Anybody familiar with monitoring systems knows that one big problem is false alerts--alerts that occur even though nothing is actually wrong. False positives are bad because they draw attention away from the alerts that are "real", and ultimately undermine the users' confidence in the system. In order to scale AA out to handling millions of metrics, we need to place strong bounds on the number of false positives, and that's where anomaly validation comes in. Here we perform a more detailed inspection of candidate anomalies before passing them on as such to downstream systems. See Anomaly Validation for more information.
Not all time series models involve offline training, but many of the interesting ones do. Model building encompasses both the scheduling of training jobs as well as the training itself.
Training jobs come into model building through a topic. They come from three sources:
- Model Selection and Autotuning jobs that run as part of the model search process;
- scheduled rebuilds that typically occur on a regular period; and
- "performance rebuilds" that occur when the Performance Monitor detects that a model fit has degraded.
In the diagram you can see that we have a repository for training data as well as a model repository. Both of these are based on Amazon S3, at least for now. The idea is that Model Building consumes training data and produces models, which are in turn loaded into the Anomaly Detection system for (you guessed it) anomaly detection. Training data arrives by way of a pipe connecting the incoming metric topic to the training data repo.
Earlier we noted the need to perform automated model selection and autotuning on behalf of users. The "autotuning" piece is more commonly known as "hyperparameter optimization" (HPO) in machine learning circles. Here's what these mean in quasi-layperson's terms:
- Model selection is determining which family of model best applies to a given time series. There are many different model families, and they serve different purposes. For example, we might choose to use a constant threshold model for a metric that tracks the amount of disk available, or for a metric that represents the success rate for some given transaction. On the other hand, for a metric with strong daily and weekly seasonalities, we'd probably want to use something like Twitter's Seasonal Hybrid ESD, random cut forests or perhaps an LSTM network. The challenging task for model selection is to find the right model family.
- Hyperparameter optimization (HPO). To generate models from a given family, we run machine learning training algorithms. These training algorithms use training data to "fit" a model to the data, which means to find the parameter values for that model that produce the best performance on real-world (non-training) data. It turns out that the algorithms themselves have parameters that need to be chosen. These algorithm parameters (as opposed to the model parameters) are called hyperparameters. It's often a challenging hit-or-miss process to find the right hyperparameters for a given model. The HPO problem is to automate the search for good hyperparameters.
Once MSA finds the right model and hyperparameters, it saves this information in the Model Service (see below). This informs the Model Build process.
The Model Service plays a supporting role. It provides data services to the other AA subsystems. For example, MSA needs a place to save the metric-to-model mappings it discovers, and the metric router needs a place to look those up. Model Building needs to know which models are due for rebuilds. Anomaly Detection needs to store user preferences around threshold sensitivity. The Model Service provides a shared location within the architecture to manage this sort of data.
The codebase is organized into a number of Maven modules:

Modules higher up in the diagram depend on modules lower in the diagram. For example, the Samples module depends on everything, and everything depends on the Core module.
Here are brief descriptions of the modules. Each module has a wiki page with more details.
The core module contains code that many or even all other modules want to use. This is generally utility code, though domain code makes sense in certain cases too. For example, model evaluation is a common concern across multiple modules (we use it for model selection and autotuning, training, and model performance monitoring), so the core contains model evaluation components.
The modelservice module contains the Model Service as described above.
Certain anomaly detection models require offline training. modeltrain provides an interface for attaching model training algorithms to the system so that they can be invoked during model selection and autotuning, or just as part of the periodic retraining that models undergo.
We expect that this will mostly be a thin interface into external training algos, such as one might find in a machine learning framework like Tensorflow. The idea is to deploy those models into an AA environment as Docker containers, and have the modeltrain interface know how to invoke those.
The msa module handles Model Search and Autotuning, as described above.
The anomdetect contains anomaly detectors as well as the model performance monitor. See Anomaly Detection for more details.
The anomvalidate module contains anomaly validators. See Anomaly Validation for more details.
The kakfa module adapts other modules for use in a Kafka environment. Specifically we use it for the Anomaly Detection modules, anomdetect and anomvalidate.
The tools module contains model development tools, such as data sources and visualization tools. See Tools for more details.
The samples module contains sample data pipelines that we build using the tools module. See Samples for more details.