This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 United States License.

Locate and Beamform: Two-dimensional Locating All-neural Beamformer for Multi-channel Speech Separation (LaBNet)
Official PyTorch implementation and dataset generation scripts of the Interspeech 2023 paper "Locate and Beamform: Two-dimensional Locating All-neural Beamformer for Multi-channel Speech Separation" by Fu Yanjie et al.
- Fu, Yanjie, et al. "Locate and Beamform: Two-dimensional Locating All-neural Beamformer for Multi-channel Speech Separation." arXiv preprint arXiv:2305.10821 (2023).
@misc{fu2023locate,
title={Locate and Beamform: Two-dimensional Locating All-neural Beamformer for Multi-channel Speech Separation},
author={Yanjie Fu and Meng Ge and Honglong Wang and Nan Li and Haoran Yin and Longbiao Wang and Gaoyan Zhang and Jianwu Dang and Chengyun Deng and Fei Wang},
year={2023},
eprint={2305.10821},
archivePrefix={arXiv},
primaryClass={eess.AS}
}We implement LaBNet based on Generalized spatio-temporal RNN Beamformer (GRNN-BF), which directly learns the beamforming weights from the estimated speech and noise spatial covariance matrices. For more details, please refer to the original paper: "Generalized Spatio-Temporal RNN Beamformer for Target Speech Separation".
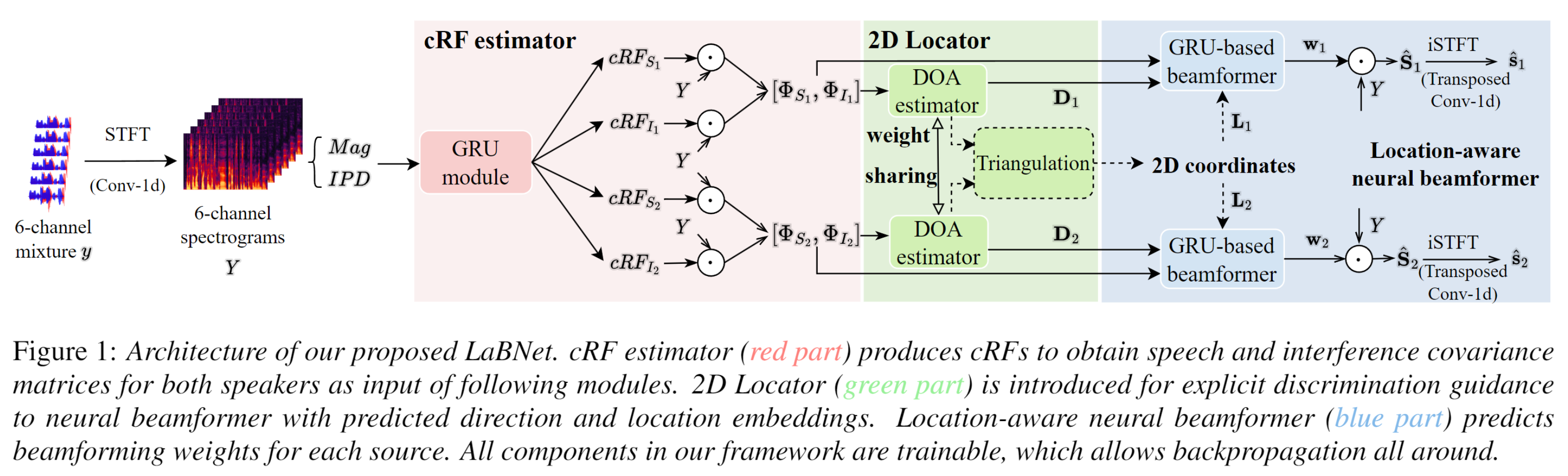
The figure below shows the architecture of our proposed LaBNet.
The simulated dataset Libri-SIM is based on the Librispeech corpus.
- Download the train-clean-100, dev-clean and test-clean data from Librispeech's website and unzip them into any directory. The absolute path for the directory is denoted as libri_path, which should contain 3 subfolders train-clean-100, dev-clean and test-clean.
- Download or clone this repository.
Run the command below for train-clean-100, dev-clean and test-clean respectively.
python ./preparation/1_sb_vad.py
python ./preparation/2_clip_segments.py
python ./preparation/3_generate_list.pyThe preprocessing here is to clip 4 seconds long speech segments with few silence for further simulation.
- We simulate 6-channel audio data from original single-channel audio through pyroomacoustics, the spacings of 6 microphones are 0.04 m, 0.04 m, 0.12 m, 0.04 m, 0.04 m. The parameters of simulated rooms are shown in Tabel 1, the length of room is randomly selected between 4 m and 12 m, the width of room is a random number between 3 m and 9 m, and the height of room is a random number between 2.5 m and 5 m. There are small, middle, large 3 types of room according to the length of the room, the RT60 is a random number between 0.3 s and 0.6 s, 0.4 s and 0.7 s, 0.5 s and 0.8 s respectively.

- As shown in Figure 1, the microphone array is located in the middle of the wall, at a distance of 0.5 m from the wall and 2 m from the ground. In order to make sound sources cover the area in rooms better, we first set the direction-of-arrival of sound source, then we leave 0.5 m between the sound source and the microphone array and between the sound source and the wall, and divide the rest range into near, medium and far range, the distance between microphone array and sound source is a random number in 3 types of range, so we simulate one original single channel speech data at near, medium, far distance simultaneously.
- We simulate 50 training rooms, 10 validation rooms and 10 testing rooms, respectively. The angular spacing between simulated sources is 1°.
- Then we generate 3 sets of training, validation set, and testing set from the simulated rooms. We randomly select 2 sources by random angles and source-to-array distances.
- The training set contains 40,000 utterances (44.44 hours), the validation set and the testing set contains 5,000 and 3,000 utterances, respectively.
Run commands below to simulate and generate the .lst which contains dataset paths.
python ./preparation/libri_sim_code/4_gen_simulated_room.py
python ./preparation/libri_sim_code/5_generate_json.py
python ./preparation/libri_sim_code/6_json_2_list.py