Unsupervised Learning
Knowledge is the fuel,
That feeds all inventions' fire,
But dreams are the spark
Unsupervised learning is a branch of machine learning in which the AI algorithm is trained using uncategorised, unclassified input data to find structure in the data, such as clustering or grouping. Unlike with Supervised Learning, the AI algorithm does not have access to a target output, this allows the algorithm to act on information unguided2. Unsupervised learning systems instead search for similarities in the data and react based on the presence or absence of these similarities in each new piece of data4 5. These systems try to infer patterns from a dataset, therefore the best time to use unsupervised machine learning is when you don't have data on desired outcomes3.
Clustering is the unsupervised learning task of grouping unlabeled data points into unknown groups (clusters) based on similarities (and dissimilarities) in the data1. Clustering places data into classes; the algorithms attempt to discover the labels of these classes by assessing the data iteratively since the labels are unknown beforehand. The clustering of data points helps to profile the attributes of different groups, giving an insight into the underlying patterns of different groups. A simple example of where this would be useful would be in grouping documents that have similar topics together.
Valid clustering depends only on the data attributes used in the algorithm since this is how it assesses similarities in the data. Good clustering is judged based on two core properties: 1) High cluster density and 2) High cluster to cluster separation space.
K-means Clustering[6]
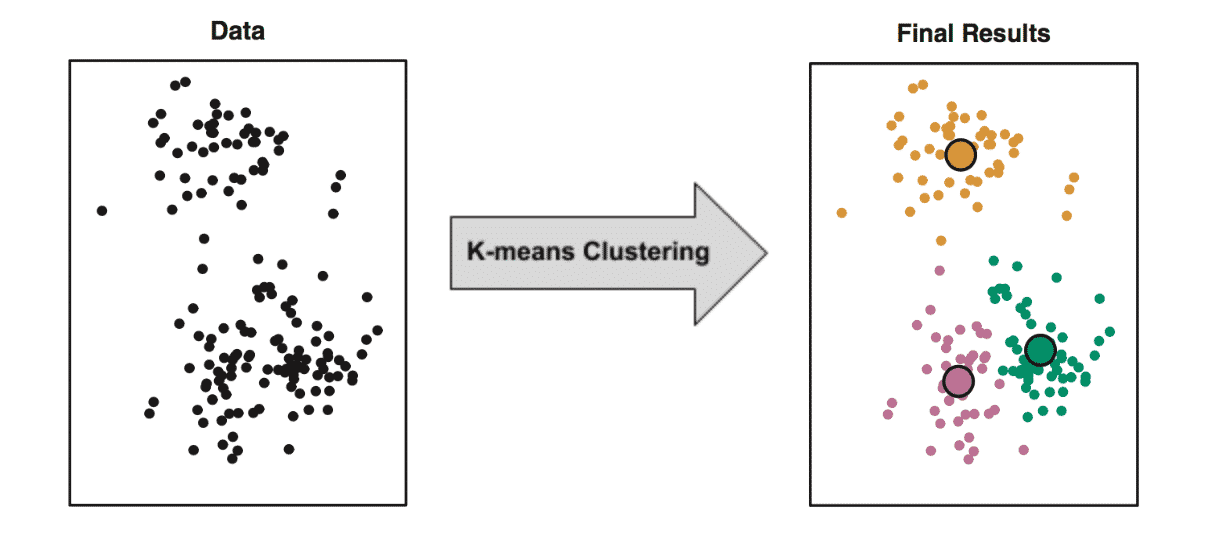
A K-means7 clustering algorithm iteratively updates the number of clusters (K) and the assignment of data points to centroids8. Each centroid defines a cluster. Data points are assigned to a centroid based on its squared Euclidean distance to that centroid. The centroids are continuously recomputed using the mean of all data points assigned to each centroid's cluster. This algorithm works for a predetermined K value (number of clusters). To find the most accurate estimate for K, the user must run the algorithm with a range of different values for K and compare the results. A way to determine the most accurate k value is to take the average distance of the data points (within each cluster) to the centroid point of that cluster and measure this against the different K value options. Often described as Distortion vs a number of K values. You can use this to see where the elbow point is (a steep climb in the distortion) as shown in the graph below. This should lead to a final result of clusters with the two core properties mentioned earlier.
The graph indicates an Elbow Point at a K value of 3

1 G. N. Yannakakis and J. Togelius, "Artificial Intelligence and Games". Springer, 2018.
2 Author unknown, "Unsupervised Machine Learning". Available: https://www.datarobot.com/wiki/unsupervised-machine-learning/ [Accessed: 05-Feb-2019]
3 Margaret Rouse, "Unsupervised Learning Definition", December 2016. Available: https://whatis.techtarget.com/definition/unsupervised-learning [Accessed: 05-Feb-2019]
4 D. O. Hebb. The Organization of Behavior. Wiley, New York, 1949.
5 W. Ross Ashby. Principles of the self-organizing system. In Facets of Systems Science, pages
521–536. Springer, 1991.
6 Narin Luangrath, "Machine Learning Crash Course, Part II: Unsupervised Machine Learning", February 13, 2018. Available: https://www.iotforall.com/machine-learning-crash-course-unsupervised-learning/ [Accessed: 05-Feb-2019]
7 MacQueen, J. (1967, June). Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability (Vol. 1, No. 14, pp. 281-297).
8 Andrea Trevino, "Introduction to K-means Clustering", December 6, 2016. Available: https://www.datascience.com/blog/k-means-clustering [Accessed: 06-Feb-2019]