In this repository, we publish the codes necessary to implement the Multi-Start Optimization Neural Networks (MSO-NNs), presented fin the paper: Automatic Differentiation-Based Multi-Start for Gradient-Based Optimization Methods, Mathematics 2024, 12(8), 1201; https://doi.org/10.3390/math12081201

A MSO-NN is a shallow NN that can be trained on fake input–output pairs to perform a gradient-based optimization method
with respect to
In this repository we show a MSO-NN implementation in Tensorflow. In particular, we implement both a custom MultiStartOptimizationModel class (for object-oriented programming approaches) and functions for building/running MSO-NNs (for procedural programming approaches).
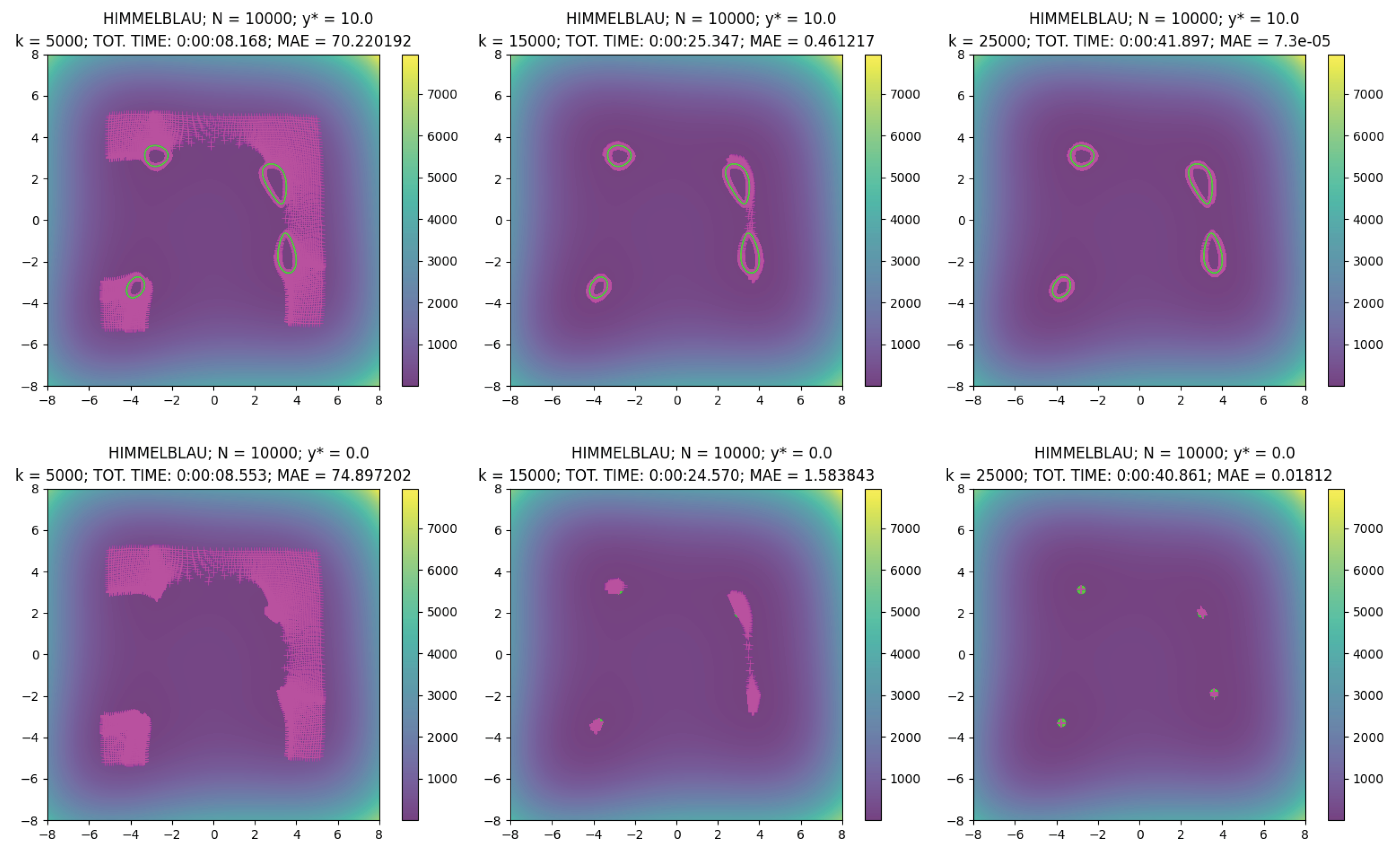
See the two examples (example_msonn_levelset.py and example_msonn_minimize.py) for two applications (level set detection and global minimization, respectively) of MSO-NNs with the Himmelblau function.
Thew code in this repository is released under the MIT License (refer to the LICENSE file for details).
- matplotlib==3.7.2
- numpy==1.24.3
- tensorflow==2.15.0.post1
MSO-NNs can be initialized using the class MultiStartOptimizationModel in the multistart.models module or the function make_mso_model in the multistart.mso_nn module.
The necessary objects for creating a MSO-NN are listed below:.
-
function: tensorflow function (better if vectorized for batches of inputs) representing the objective function
$f:\mathbb{R}^n\rightarrow\mathbb{R}$ ; -
starting_pts: numpy
$N$ -by-$n$ array collecting the$N$ starting points$\boldsymbol{x}^{(0)}_1,\ldots ,\boldsymbol{x}^{(0)}_1\in\mathbb{R}^n$ in its rows; - dtype: data type of the model (default tf.float32).
Extra inputs for the procedural case:
- name: name for the MSO-NN model (default None).
Then, the MSO-NN can be created with one of the two following steps:
- As MultiStartOptimizationModel object.
model = MultiStartOptimizationModel(function, starting_pts, dtype)
- As Keras Model object.
model = make_mso_model(function, starting_pts, dtype, name=model_name)
For running
- As MultiStartOptimizationModel object.
# Example with: # - Adam optimizer; # - 1000 epochs. # MSE loss is mandatory, MAE metric is suggested for minitoring model.compile(optimizer='adam', loss='mse', metrics=['mae']) Xmin = model.minimize(epochs=1000, verbose=True) # alternatively, set verbose to False
- As Keras Model object.
# Example with: # - Adam optimizer; # - 1000 epochs. # MSE loss is mandatory, MAE metric is suggested for minitoring model.compile(optimizer='adam', loss='mse', metrics=['mae']) Xmin = minimize_mso_model(model, epochs=1000, verbose=True) # alternatively, set verbose to False
For running
- As MultiStartOptimizationModel object.
# Example with: # - Adam optimizer; # - 1000 epochs; # - Level set = 100. # MSE loss is mandatory, MAE metric is suggested for minitoring model.compile(optimizer='adam', loss='mse', metrics=['mae']) # Xlevel = model.find_level_set(y_level=100., epochs=1000, verbose=True) # alternatively, set verbose to False
- As Keras Model object.
# Example with: # - Adam optimizer; # - 1000 epochs; # - Level set = 100. # MSE loss is mandatory, MAE metric is suggested for minitoring model.compile(optimizer='adam', loss='mse', metrics=['mae']) # Xlevel = find_levelset_mso_model(model, y_level=100., epochs=1000, verbose=True) # alternatively, set verbose to False
Remark (Practical Hints): for practical hints on the optimizer or other hyper-parameters, look at the examples in this repository (example_msonn_levelset.py and example_msonn_minimize.py) or the original paper. In particular, for Adam optimizer, it is recommended to set the epsilon hyper-parameter to 1e-7/$N$ (Remark 6, original paper).
To see a code example of MSO-NN construction and optimization, see the scripts example_msonn_levelset.py and example_msonn_minimize.py in this repository.
To run the examples (bash terminal, illustrated only for example_msonn_minimize.py):
- Clone the repository:
git clone https://github.com/Fra0013To/AD_MultiStartOpt.git
- Install the required python modules.
or
pip install -r requirements.txt
pip install numpy==1.24.3 pip install matplotlib==3.7.2 pip install tensorflow==2.15.0.post1
- Run the script example_msonn_minimize.py:
python example_msonn_minimize.py
Remark: you can modify the hyper-parameters in the scripts (e.g., the epochs) for observing different outputs.
If you find MSO-NNs useful in your research, please cite the following paper (BibTeX and RIS versions):
@article{DellaSanta2024ADbasedOpt,
author = {{Della Santa}, Francesco},
doi = {10.3390/math12081201},
issn = {2227-7390},
issue = {8},
journal = {Mathematics},
month = {4},
pages = {1201},
title = {Automatic Differentiation-Based Multi-Start for Gradient-Based Optimization Methods},
volume = {12},
url = {https://www.mdpi.com/2227-7390/12/8/1201 },
year = {2024},
}
TY - EJOU
AU - Della Santa, Francesco
TI - Automatic Differentiation-Based Multi-Start for Gradient-Based Optimization Methods
T2 - Mathematics
PY - 2024
VL - 12
IS - 8
SN - 2227-7390
KW - global optimization
KW - multi-start methods
KW - Automatic Differentiation
KW - Neural Networks
DO - 10.3390/math12081201
- v 1.0 (2024.04.11): Repository creation.