Note: Current format of NERD is NOT WORKING the way I hoped for need some more modifications.
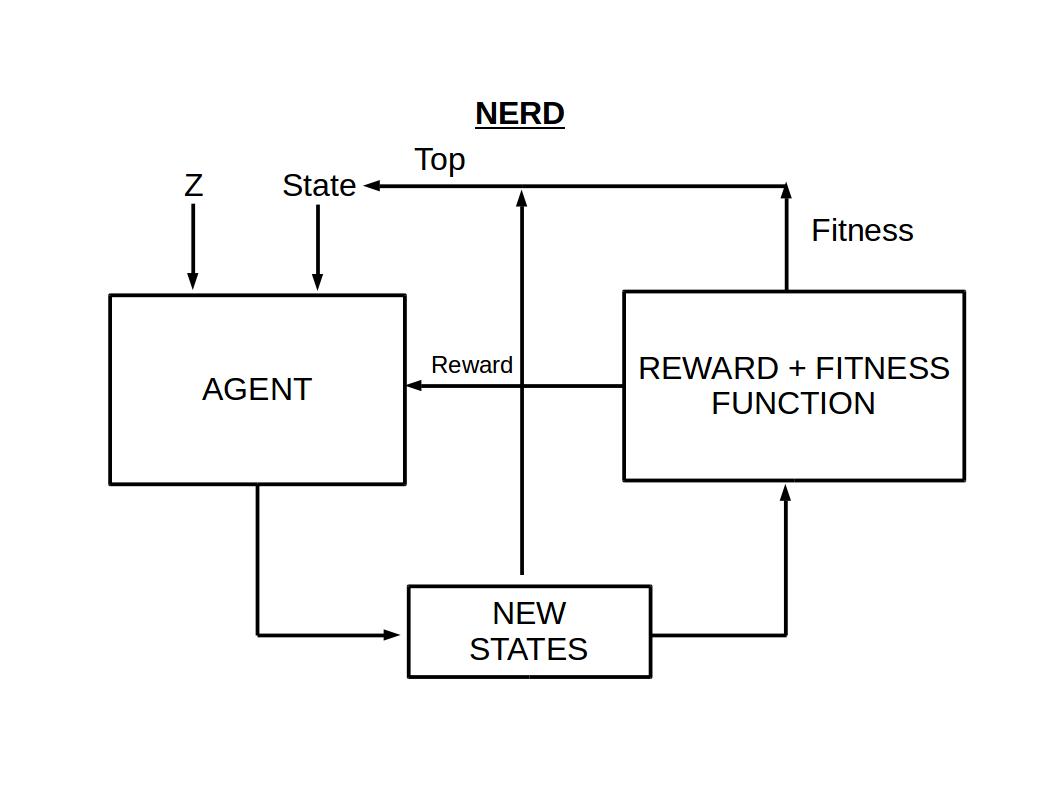
Evolution of Discrete data with Reinforcement Learning
https://gananath.github.io/nerd.html
- pytorch 1.3
- pysmiles 1.0
- sklearn
After some testing I found that actions taken by RL agent are collapsing to a certain action similar to mode collapse in GAN.
Epoch: 10000 Reward: -1000.0 Loss: -0.73
CCBCCCBCBCC|C||||CC|||||||||||||||||||||||||||... -10.0 -0.501915
CCBCCCBCBCC|C||||CC|||||||||||||||||||||||||||... -10.0 -0.502028
CCBCCCBCBCC|C||||CC|||||||||||||||||||||||||||... -10.0 -0.502080

{kind=link}
DOI: https://doi.org/10.5281/zenodo.3518054
@misc{gananath2016,
author = {Gananath, R.},
title = {NERD},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Gananath/NERD}},
doi = {10.5281/zenodo.3518054}
}