{kind=link}
{kind=link}
This project will include the files to create and define tables for a database with a star schema for a Redshift cluster in Amazon Web Services. It also contains files to create DAGs (Directed Acyclic Graph) using Apache Airflow and the different operators for each dedicated task that will shape the pipeline.
This repository simulates the creation of an ETL pipeline for a music streaming startup whose data currently resides in S3 buckets in AWS and they've decided to add automation and monitoring to their data warehouse in Redshift.
For this purpose, we are going to use Apache Airflow to define and optimize different task and configure task dependencies to establish all the steps for this pipeline. The tasks will include:
- The creation of the tables in the redshift cluster.
- The extraction of the data from the S3 buckets into staging tables.
- Processing the data and loading it into the final tables in the data warehouse.
- Run a quality check to make sure every table has the right structure and format.
The objective of this repository is to process the data and create a star schema optimized for queries for the song play analysis and to use Apache Airflow to be able to monitor and automate each task allowing the client to process the data in a controlled and structured way.
The data currently is in an S3 bucket in directories which contains their log data and song data in JSON files (more information below).
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song's track ID. Here is an example of a file path: "song_data/A/B/C/TRABCEI128F424C983.json" And here is an example of one of the json files: {"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0} S3 bucket: s3://udacity-dend/song_data
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations. Here is an example of a filepath: "log_data/2018/11/2018-11-12-events.json" And here is an example of a json file for these events: {"artist": "None", "auth": "Logged In", "gender": "F", "itemInSession": 0, "lastName": "Williams", "length": "227.15873", "level": "free", "location": "Klamath Falls OR", "method": "GET", "page": "Home", "registration": "1.541078e-12", "sessionId": "438", "Song": "None", "status": "200", "ts": "15465488945234", "userAgent": "Mozilla/5.0(WindowsNT,6.1;WOW641)", "userId": "53"} S3 bucket: s3://udacity-dend/log_data
The star schema that is going to be created using this program will have the next structure:
- Fact table:
- songplays [songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent]
- Dimension tables:
- users [user_id, first_name, last_name, gender, level]
- songs [song_id, title, artist_id, year, duration]
- artist [artist_id, name, location, lattitude, longitude]
- time [start_time, hour, day, week, month, year, weekday]
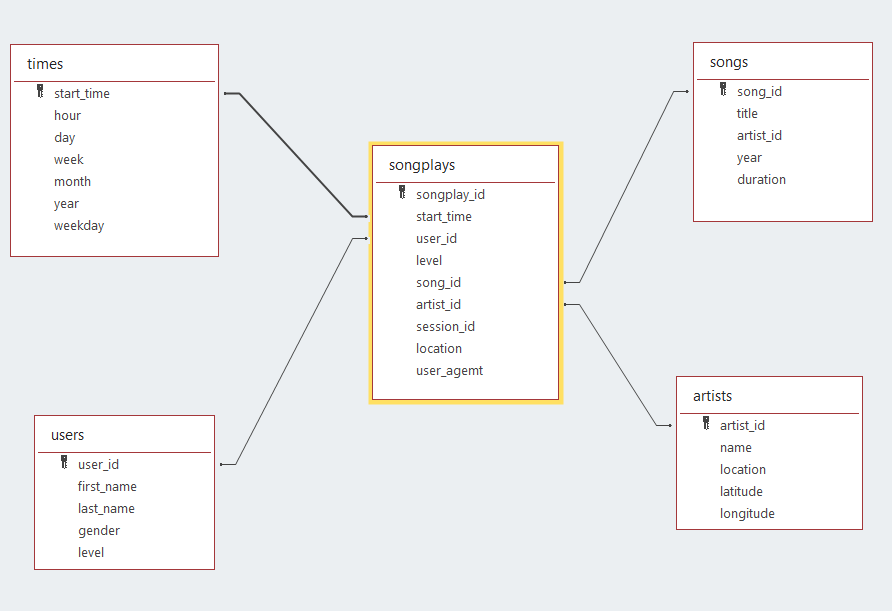
This file contains the sql statements to create the staging tables and fact and dimensional tables that will form the star schema.
This folder contains an auxiliar file with the remaining sql statements.
These file also contains the sql statements to select the data from the staging tables. After formatting this statements the data filtered will be inserted in the fact and dimensional tables.
This folder contains the operators with each dedicated task for the pipeline.
This operator runs the quality check making sure all the tables have the information and that they don't include nulls.
This operator is used to load the data from the staging tables to the dimensional tables (songs, artist, users and time).
This operator is used to load the data from the staging tables to the fact tables (songplays).
This operator contains the code to copy the data from the S3 buckets to the staging tables (staging_song table and staging_events table).
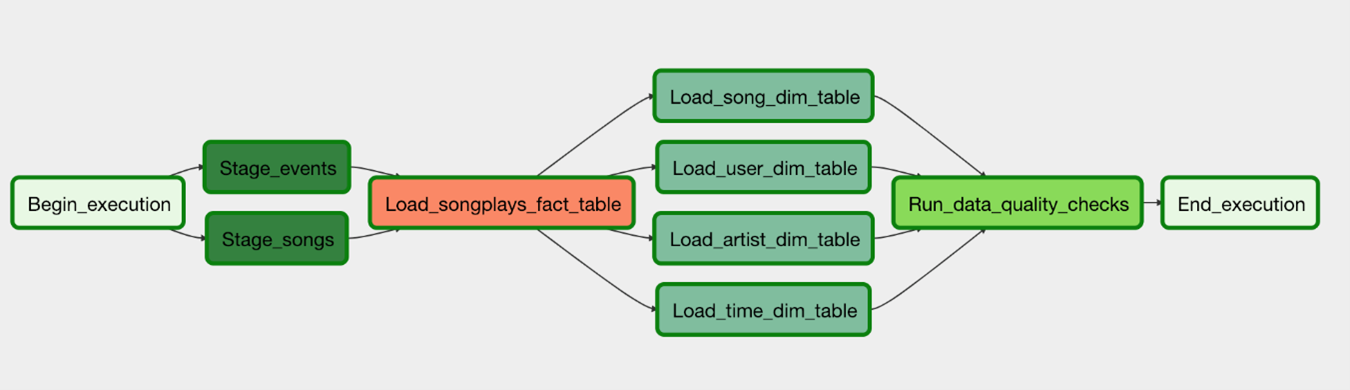
This python file has the main code which contains the call to all the operators and all the variables passed as parameters which allows the program to create and run the entire pipeline. It also contains the task dependencies at the end of the code which controls that each task are run in an order way and forms the pipeline.
Udacity provided the template and the guidelines to start this project. The completion of this was made by Guillermo Garcia and the review of the program and the verification that the project followed the proper procedures was also made by my mentor from udacity.