Comparison between the standard KD and SFT-KD-Recon. (a) The standard KD trains teacher alone and distills knowledge to student. (b) SFT-KD-Recon trains the teacher along with the student branches and then distills effective knowledge to student. (c) SFT Vs SFT-KD-Recon, the former learns in the feature domain via residual CNN while the latter learns in the image domain via image domain CNN.

The teacher DC-CNN has five blocks, each having CNN with five convolution layers and DF layer, and the student DC-CNN has five blocks, each having three convolution layers and a DF layer. The teacher is trained with three loss terms. Note that all the blocks of the student learn initial weights except the first block during SFT training.


Comparison of our framework with standard KD framework for MRI Reconstruction on MRBrainS and cardiac datasets. In all the KD methods, the student distilled from the SFT-KD-Recon outperforms the ones distilled from the standard teacher.

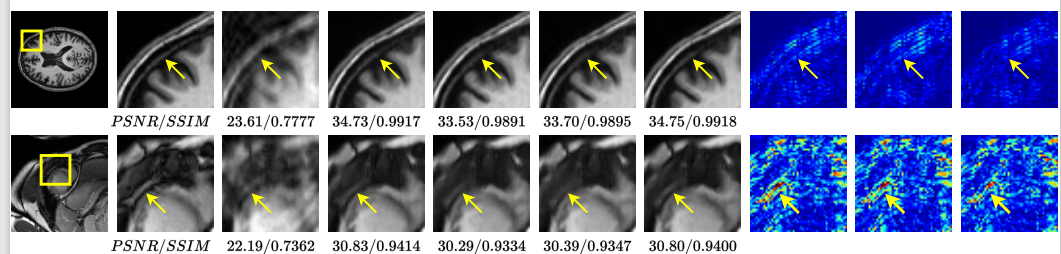
Visual results (from left to right): target, target inset, ZF, teacher, student, Std-KD, SFT-KD-Recon, student residue, Std-KD residue, SFT-KD-Recon residue with respect to the target, for the brain (top) and cardiac (bottom) with 4x acceleration. We note that in addition to lower reconstruction errors, the SFT-KD distilled student is able to retain finer structures better when compared to the student and Std-KD output.
├── KD-MRI
|-- Cardiac_reconstruction
|-- us_masks
...
├── datasets
|-- {DATASET_TYPE}
|-- train
|-- acc_{ACC_FACTOR}
|-- 1.h5
|-- 2.h5
|..
|-- validation
|--acc_{ACC_FACTOR}
|-- 1.h5
|-- 2.h5
|..
├── experiments
|-- {DATASET_TYPE}
|-- acc_{ACC_FACTOR}
|-- {MODEL}_{MODEL_TYPE}
|-- best_model.pt
|-- model.pt
|-- summary
|-- results
|-- 1.h5
|-- 2.h5
|-- .
|-- report.txt
Example: {DATASET_TYPE} = cardiac, {ACC_FACTOR} = 4x, {MODEL} = attention_imitation, {MODEL_TYPE} = teacher
├── KD-MRI
|-- reconstruction
|-- super-resolution
|-- us_masks
...
├── datasets
|-- cardiac
|-- train
|--acc_4x
|-- 1.h5
|-- 2.h5
|..
|-- validation
|--acc_4x
|-- 1.h5
|-- 2.h5
|..
├── experiments
|-- cardiac
|-- acc_4x
|-- attention_imitation_teacher
|-- best_model.pt
|-- model.pt
|-- summary
|-- results
|-- 1.h5
|-- 2.h5
|..
Gayathri, M.N., Ramanarayanan, S., Fahim, M.A., Ram, K. and Sivaprakasam, M., 2023. SFT-KD-Recon: Learning a Student-friendly Teacher for Knowledge Distillation in Magnetic Resonance Image Reconstruction. arXiv preprint arXiv:2304.05057.