This project was developed in collaboration with Hieu Vuong, Joshua Guevarra, Ramneet Kaur, and Mario Lim. The technologies used include Javscript, HTML, CSS, Vue.js, Groovy, Google Drive API, and Amazon S3 API.
This application downloads a file given a URL to local disk, converts it into a CSV-formatted UTF-8 encoded file, and uploads it to a cloud storage service of choice.
Currently supported file types:
- Text File
- Zip File
- HTML Table
- HTML Unordered List
Currently supported cloud storage services:
- Google Drive
- Amazon S3
To run this application, make sure the repository is cloned onto your local system and that the necessary packages to run the application are installed.
The application will need the following to be installed:
Micronaut: https://micronaut.io/download/
Groovy: https://groovy.apache.org/download.html
Gradle: https://gradle.org/install/
- cd into the data-fetcher/Front-end/data-fetcher
- Make sure that the necessary packages are installed for the front-end by running
npm install - Start up the front-end by running
npm run dev - Start up the back end by either:
a. Open up a new terminal window and cd into data-fetcher/back-end/Data-Fetcher and
run./gradlew run
b. Open the repository in an IDE that supports Groovy and Micronaut (such as IntelliJ) and run the application in there - Open up a web browser and go to http://localhost:3000/
The website will take you to the main dashboard. The Total Success, Total Updating, and Total Error describe the total amount of jobs that were successfully converted and uploaded, are in the process of being converted and uploaded, or failed somewhere along the way.
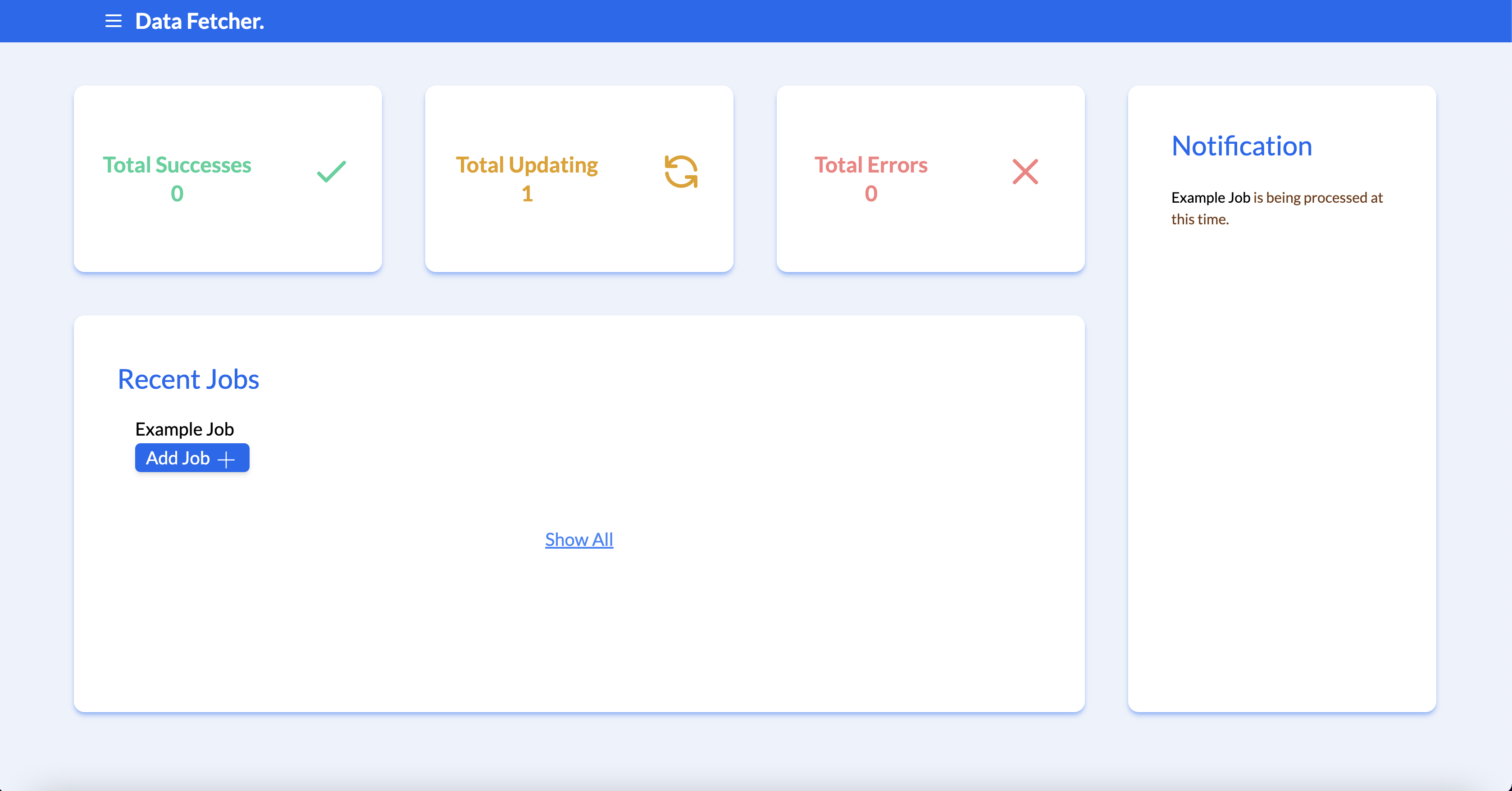
The "Notifications" box describes the status of recent configurations. The recent jobs tab shows the most recent job forms that were submitted.
To begin the process create a new job by clicking on Add Job or going to http://localhost:8080/newConfig
It will take you to the page that allows you to fill in form components.
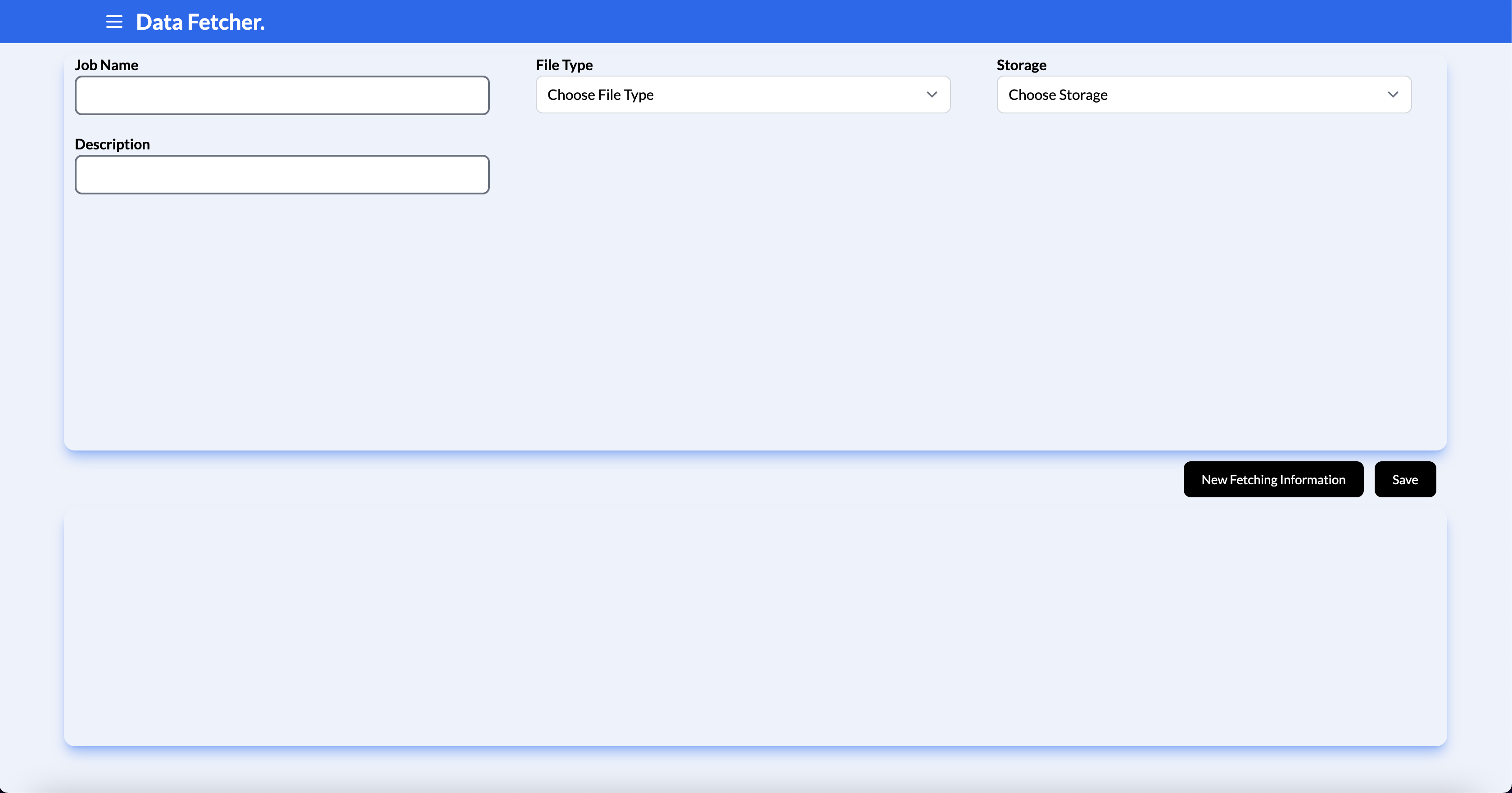
The form will now need to be filled out.
This is the name of the job. This is also the name of your file that will be uploaded to the cloud storage system of choice.
This is the description of your job for quick reference of what job was sent.
The file type is a drop down menu of what file types are currently supported for conversion (currently zip and text files, HTML tables, and HTML Unordered lists). Select the file that you plan on having downloaded and converted and click on "New Fetching Information" on the bottom right to fill in the required information about the file you want processed.
All file types will require the URL to the file, the headers of the columns (if not already provided), and the path of the location you want the files to be saved locally. You will also need to know the information about the file ahead of time, so some files may need to be downloaded and looked through in order to gather their information (such as the delimiter of a file, its headers, etc).
If headers are filled out, they should be separated entered one at a time and separated by commas. For example: these, are, headers
- File Name (Zip Files only): Enter the name of the file you want to be processed.
- Delimiter: This is going to be the delimiter of the file. For example, "\t" for tab delimiter.
- Table Index: Enter the index of the HTML table you want parsed. Index will start at 0 to represent the 1st table on a page, and so forth.
- Selector: Find the selector of your list by looking at the page source and finding where the list begins.
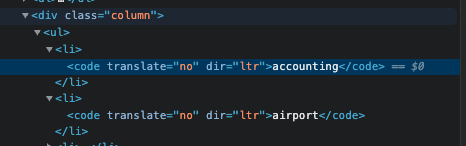
For example, this list starts at the element that contains "accounting" under the div class="column" tag.
This makes the selector div.column.
- List Index: Enter the indexes of the tables you want parsed separated by comma. For example 0, 1.
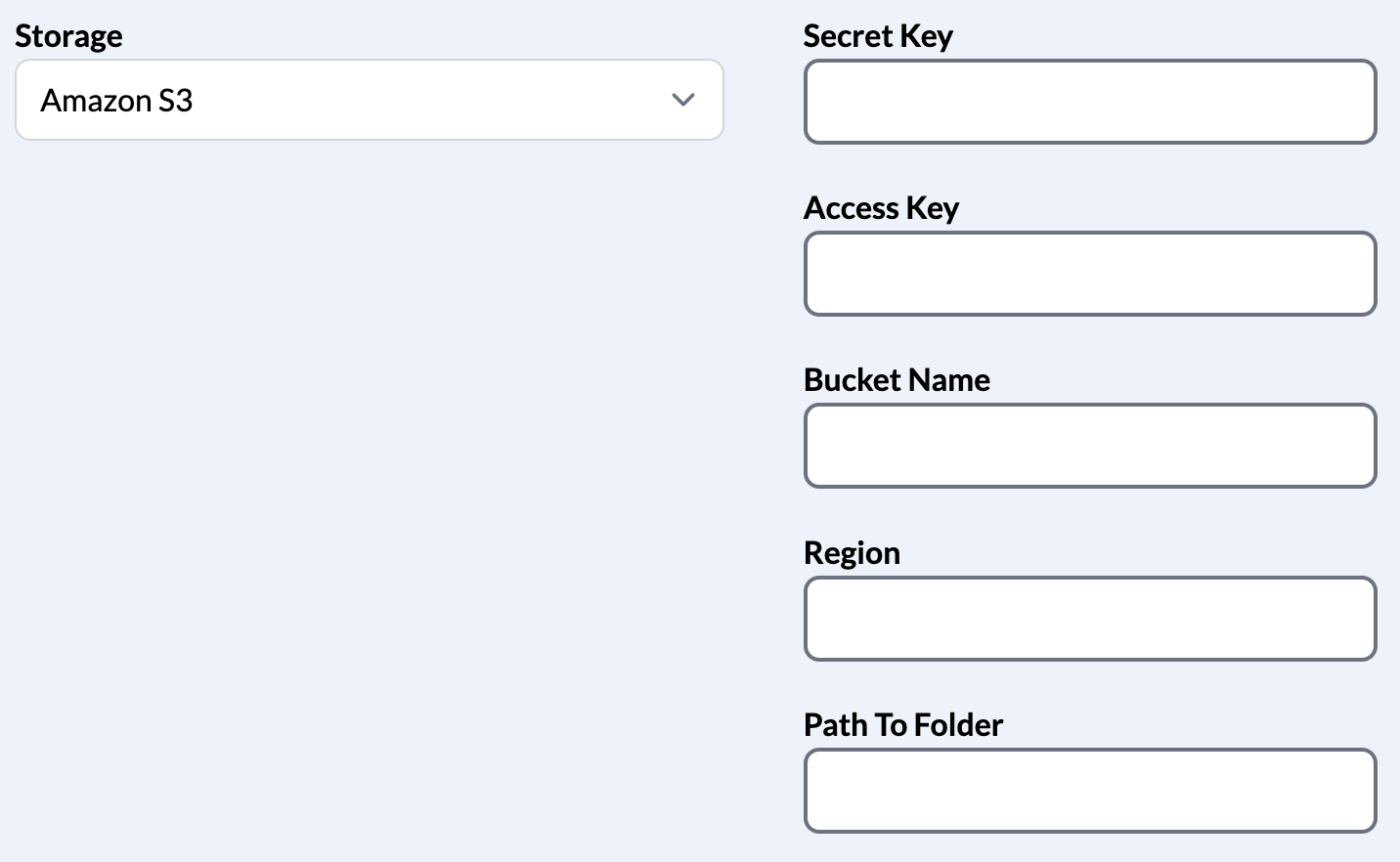
- Amazon S3 is a storage option that the user can choose to store the processed .csv file in.
- The user is expected to have a S3 account and bucket created before using this as a possible option.
- The application will need several pieces of information from the user.
-
- Secret Key
-
- Access Key
-
- Bucket Name
-
- Region (this is the region that the bucket is assigned to)
-
- Path to Folder (this is the path to a folder that the user would like to place their file in S3)
- For example: drive/test (in this example, the file would be put in a folder called "drive" with a subfolder called "test"
- User can either choose to create a new folder or access one that is already in the bucket.
Screenshot of form input for reference:
- Google Drive is the alternate storage option that the user can choose to store the processed .csv file in.
- The user is expected to have a Google Drive account created before using this as a possible option. When authenticating to Google Drive, the user will
- be asked to login to their specifed Google account.
- The application will only need to know the following:
- Folder Name (The name of the newly created folder that the file will be saved into)